Big Data
Les mégadonnées désignent des ensembles de données trop volumineux ou trop complexes pour être traités par des logiciels d’application de traitement de données traditionnels . Les données comportant de nombreux champs (lignes) offrent une plus grande Puissance statistique , tandis que les données plus complexes (plus d’attributs ou de colonnes) peuvent entraîner un taux de fausses découvertes plus élevé . [2] Les défis de l’analyse des mégadonnées comprennent la capture de données , le stockage de données , l’analyse de données , la recherche, le partage , le transfert , la visualisation , l’ interrogation , la mise à jour, la confidentialité des informations, et source de données. Le Big Data était à l’origine associé à trois concepts clés : volume , variété et vélocité . [3] L’analyse des mégadonnées présente des défis en matière d’échantillonnage, et ne permettait donc auparavant que des observations et un échantillonnage. Par conséquent, les mégadonnées incluent souvent des données dont la taille dépasse la capacité des logiciels traditionnels à traiter dans un délai et une valeur acceptables .
 Croissance non linéaire de la capacité mondiale de stockage numérique de l’information et déclin du stockage analogique [1]
Croissance non linéaire de la capacité mondiale de stockage numérique de l’information et déclin du stockage analogique [1]
L’utilisation actuelle du terme Big Data a tendance à faire référence à l’utilisation de l’analyse prédictive , de l’analyse du comportement des utilisateurs ou de certaines autres méthodes avancées d’analyse de données qui extraient de la valeur du Big Data, et rarement à une taille particulière d’ensemble de données. “Il ne fait aucun doute que les quantités de données désormais disponibles sont effectivement importantes, mais ce n’est pas la caractéristique la plus pertinente de ce nouvel écosystème de données.” [4] L’analyse des ensembles de données peut trouver de nouvelles corrélations pour « repérer les tendances commerciales, prévenir les maladies, combattre la criminalité, etc. [5] Scientifiques, chefs d’entreprise, médecins, publicitaires et gouvernementsrencontrent régulièrement des difficultés avec de grands ensembles de données dans des domaines tels que les recherches sur Internet , les technologies financières , l’analyse des soins de santé, les systèmes d’information géographique, l’informatique urbaine et l’informatique d’entreprise . Les scientifiques rencontrent des limites dans le travail e-Science , y compris la météorologie , la génomique , [6] la connectomique , les simulations physiques complexes, la biologie et la recherche environnementale. [7]
La taille et le nombre d’ensembles de données disponibles ont augmenté rapidement à mesure que les données sont collectées par des appareils tels que des appareils mobiles , des appareils Internet des objets de détection d’informations bon marché et nombreux , aériens ( télédétection ), journaux logiciels, caméras , microphones, identification par radiofréquence lecteurs (RFID) et Réseaux de capteurs sans fil . [8] [9] La capacité technologique mondiale par habitant de stocker des informations a à peu près doublé tous les 40 mois depuis les années 1980 ; [10] depuis 2012 [mettre à jour], chaque jour 2,5 exaoctets (2,5×2 60 octets) de données sont générés. [11]Sur la base d’une prédiction du rapport d’ IDC , le volume mondial de données devrait croître de façon exponentielle de 4,4 zettaoctets à 44 zettaoctets entre 2013 et 2020. D’ici 2025, IDC prévoit qu’il y aura 163 zettaoctets de données. [12] Une question pour les grandes entreprises est de déterminer qui devrait posséder les initiatives de mégadonnées qui affectent l’ensemble de l’organisation. [13]
Les systèmes de gestion de bases de données relationnelles et les progiciels statistiques de bureau utilisés pour visualiser les données ont souvent des difficultés à traiter et à analyser les mégadonnées. Le traitement et l’analyse des mégadonnées peuvent nécessiter “des logiciels massivement parallèles fonctionnant sur des dizaines, des centaines, voire des milliers de serveurs”. [14] Ce qui est qualifié de « mégadonnées » varie en fonction des capacités de ceux qui les analysent et de leurs outils. De plus, l’expansion des capacités fait du Big Data une cible mouvante. “Pour certaines organisations, faire face à des centaines de gigaoctets de données pour la première fois peut déclencher un besoin de reconsidérer les options de gestion des données. Pour d’autres, cela peut prendre des dizaines ou des centaines de téraoctets avant que la taille des données ne devienne une considération importante.” [15]
Définition
Le terme big data est utilisé depuis les années 1990, certains attribuant le mérite à John Mashey d’avoir popularisé le terme. [16] [17] Les mégadonnées comprennent généralement des ensembles de données dont la taille dépasse la capacité des outils logiciels couramment utilisés pour capturer , conserver , gérer et traiter les données dans un délai tolérable. [18] La philosophie des mégadonnées englobe les données non structurées, semi-structurées et structurées, mais l’accent est mis principalement sur les données non structurées. [19] La “taille” des mégadonnées est une cible en constante évolution ; à partir de 2012 [update]allant de quelques dizaines de téraoctets à plusieurs zettaoctets de données. [20]Les mégadonnées nécessitent un ensemble de techniques et de technologies avec de nouvelles formes d’ intégration pour révéler des informations à partir d’ensembles de données diversifiés, complexes et à grande échelle. [21]
“Variété”, “véracité” et divers autres “V” sont ajoutés par certaines organisations pour le décrire, une révision contestée par certaines autorités de l’industrie. [22] Les V des mégadonnées étaient souvent appelés les « trois V », les « quatre V » et les « cinq V ». Ils représentaient les qualités du Big Data en termes de volume, de variété, de vélocité, de véracité et de valeur. [3] La variabilité est souvent incluse comme une qualité supplémentaire des mégadonnées.
Une définition de 2018 indique que « le Big Data est l’endroit où des outils informatiques parallèles sont nécessaires pour gérer les données », et note : « Cela représente un changement distinct et clairement défini dans l’informatique utilisée, via des théories de programmation parallèle, et des pertes de certaines des garanties et capacités apportées par le modèle relationnel de Codd .” [23]
Dans une étude comparative d’ensembles de données volumineuses, Kitchin et McArdle ont constaté qu’aucune des caractéristiques couramment considérées des données volumineuses n’apparaît de manière cohérente dans tous les cas analysés. [24] Pour cette raison, d’autres études ont identifié la redéfinition de la dynamique du pouvoir dans la découverte des connaissances comme le trait déterminant. [25] Au lieu de se concentrer sur les caractéristiques intrinsèques des mégadonnées, cette perspective alternative met en avant une compréhension relationnelle de l’objet affirmant que ce qui compte est la manière dont les données sont collectées, stockées, mises à disposition et analysées.
Big data vs business intelligence
La maturité croissante du concept délimite plus nettement la différence entre « big data » et « business intelligence » : [26]
- L’intelligence d’affaires utilise des outils de mathématiques appliquées et des statistiques descriptives avec des données à haute densité d’information pour mesurer des choses, détecter des tendances, etc.
- Les mégadonnées utilisent l’analyse mathématique, l’optimisation, les Statistiques inductives et les concepts de l’identification de systèmes non linéaires [27] pour déduire des lois (régressions, relations non linéaires et effets de causalité) à partir de grands ensembles de données à faible densité d’informations [28] afin de révéler des relations et des dépendances. , ou pour effectuer des prédictions de résultats et de comportements. [27] [29] [ source promotionnelle ? ]
Les caractéristiques
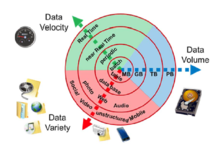 Montre la croissance des principales caractéristiques du Big Data que sont le volume, la vélocité et la variété
Montre la croissance des principales caractéristiques du Big Data que sont le volume, la vélocité et la variété
Les mégadonnées peuvent être décrites par les caractéristiques suivantes :
Le volume La quantité de données générées et stockées. La taille des données détermine la valeur et les informations potentielles, et si elles peuvent être considérées comme des mégadonnées ou non. La taille des mégadonnées dépasse généralement les téraoctets et les pétaoctets. [30] Variété Le type et la nature des données. Les technologies antérieures telles que les SGBDR étaient capables de gérer des données structurées de manière efficace et efficiente. Cependant, le changement de type et de nature de structuré à semi-structuré ou non structuré a remis en question les outils et technologies existants. Les technologies de mégadonnées ont évolué avec l’intention première de capturer, stocker et traiter les données semi-structurées et non structurées (variété) générées à grande vitesse (vélocité) et de taille énorme (volume). Plus tard, ces outils et technologies ont été explorés et utilisés pour gérer également des données structurées, mais de préférence pour le stockage. Finalement, le traitement des données structurées est resté facultatif, soit à l’aide de données volumineuses, soit de SGBDR traditionnels. Cela aide à analyser les données en vue d’une utilisation efficace des informations cachées exposées à partir des données collectées via les médias sociaux, fichiers journaux, capteurs, etc. Le Big Data puise dans le texte, les images, l’audio, la vidéo ; de plus, il complète les pièces manquantes à travers fusion de données . Rapidité La vitesse à laquelle les données sont générées et traitées pour répondre aux demandes et aux défis qui se dressent sur la voie de la croissance et du développement. Les mégadonnées sont souvent disponibles en temps réel. Par rapport aux petites données , les grandes données sont produites de manière plus continue. Deux types de vitesse liés aux mégadonnées sont la fréquence de génération et la fréquence de traitement, d’enregistrement et de publication. [31] Véracité La véracité ou la fiabilité des données, qui fait référence à la qualité des données et à la valeur des données. [32] Les données volumineuses doivent non seulement être volumineuses, mais également fiables afin d’en tirer une valeur dans l’analyse de celles-ci. La qualité des données capturées peut varier considérablement, affectant une analyse précise. [33] Valeur La valeur de l’information qui peut être obtenue par le traitement et l’analyse de grands ensembles de données. La valeur peut également être mesurée par une évaluation des autres qualités des mégadonnées. [34] La valeur peut également représenter la rentabilité des informations extraites de l’analyse des mégadonnées. Variabilité La caractéristique de l’évolution des formats, de la structure ou des sources de données volumineuses. Les mégadonnées peuvent inclure des données structurées, non structurées ou des combinaisons de données structurées et non structurées. L’analyse de mégadonnées peut intégrer des données brutes provenant de plusieurs sources. Le traitement de données brutes peut également impliquer des transformations de données non structurées en données structurées.
Les autres caractéristiques possibles des mégadonnées sont : [35]
Complet Si l’ensemble du système (c’est-à-dire n {textstyle n} 
Architecture
Les référentiels de données volumineuses ont existé sous de nombreuses formes, souvent construits par des entreprises ayant un besoin particulier. Les fournisseurs commerciaux proposaient historiquement des systèmes de gestion de bases de données parallèles pour le Big Data à partir des années 1990. Pendant de nombreuses années, WinterCorp a publié le plus grand rapport de base de données. [36] [ source promotionnelle ? ]
Teradata Corporation a commercialisé en 1984 le système de traitement parallèle DBC 1012 . Les systèmes Teradata ont été les premiers à stocker et analyser 1 téraoctet de données en 1992. Les disques durs étaient de 2,5 Go en 1991, de sorte que la définition du Big Data évolue en permanence. Teradata a installé le premier système basé sur RDBMS de classe pétaoctet en 2007. Depuis 2017 [update], quelques dizaines de bases de données relationnelles Teradata de classe pétaoctet sont installées, dont la plus grande dépasse 50 Po. Jusqu’en 2008, les systèmes étaient constitués à 100 % de données relationnelles structurées. Depuis lors, Teradata a ajouté des types de données non structurés, notamment XML , JSON et Avro.
En 2000, Seisint Inc. (maintenant LexisNexis Risk Solutions ) a développé une plate-forme distribuée basée sur C++ pour le traitement et l’interrogation des données connue sous le nom de plate-forme HPCC Systems . Ce système partitionne, distribue, stocke et fournit automatiquement des données structurées, semi-structurées et non structurées sur plusieurs serveurs de base. Les utilisateurs peuvent écrire des pipelines de traitement de données et des requêtes dans un langage de programmation déclaratif de flux de données appelé ECL. Les analystes de données travaillant dans ECL ne sont pas tenus de définir des schémas de données à l’avance et peuvent plutôt se concentrer sur le problème particulier en question, en remodelant les données de la meilleure manière possible au fur et à mesure qu’ils développent la solution. En 2004, LexisNexis a acquis Seisint Inc. [37]et leur plate-forme de traitement parallèle à grande vitesse et ont utilisé avec succès cette plate-forme pour intégrer les systèmes de données de Choicepoint Inc. lors de l’acquisition de cette société en 2008. [38] En 2011, la plate-forme de Systèmes HPCC était open source sous Apache v2.0 Licence.
Le CERN et d’autres expériences de physique ont collecté de grands ensembles de données pendant de nombreuses décennies, généralement analysés via un calcul à haut débit plutôt que par les architectures de réduction de carte généralement désignées par le mouvement actuel des “big data”.
En 2004, Google a publié un article sur un processus appelé MapReduce qui utilise une architecture similaire. Le concept MapReduce fournit un modèle de traitement parallèle, et une implémentation associée a été publiée pour traiter d’énormes quantités de données. Avec MapReduce, les requêtes sont divisées et distribuées sur des nœuds parallèles et traitées en parallèle (l’étape “map”). Les résultats sont ensuite rassemblés et livrés (l’étape “réduire”). Le cadre a été très réussi, [39] donc d’autres ont voulu reproduire l’algorithme. Par conséquent, une implémentation du framework MapReduce a été adoptée par un projet open-source Apache nommé ” Hadoop “. [40] Apache Étincellea été développé en 2012 en réponse aux limitations du paradigme MapReduce, car il ajoute la possibilité de configurer de nombreuses opérations (pas seulement une carte suivie d’une réduction).
MIKE2.0 est une approche ouverte de la gestion de l’information qui reconnaît la nécessité de révisions en raison des implications du Big Data identifiées dans un article intitulé « Offre de solution Big Data ». [41] La méthodologie aborde la gestion des mégadonnées en termes de permutations utiles de sources de données, de complexité des interrelations et de difficulté à supprimer (ou modifier) des enregistrements individuels. [42]
Des études menées en 2012 ont montré qu’une architecture multicouche était une option pour résoudre les problèmes que présentent les mégadonnées. Une architecture parallèle distribuée répartit les données sur plusieurs serveurs ; ces environnements d’exécution parallèles peuvent considérablement améliorer les vitesses de traitement des données. Ce type d’architecture insère des données dans un SGBD parallèle, qui implémente l’utilisation des frameworks MapReduce et Hadoop. Ce type de framework cherche à rendre la puissance de traitement transparente pour l’utilisateur final en utilisant un serveur d’application frontal. [43]
Le lac de données permet à une organisation de passer d’un contrôle centralisé à un modèle partagé pour répondre à la dynamique changeante de la gestion de l’information. Cela permet une ségrégation rapide des données dans le lac de données, réduisant ainsi le temps de surcharge. [44] [45]
Les technologies
Un rapport du McKinsey Global Institute de 2011 caractérise les principaux composants et l’écosystème des mégadonnées comme suit : [46]
- Techniques d’analyse des données, telles que les tests A/B , l’apprentissage automatique et le traitement du langage naturel
- Technologies de mégadonnées, telles que l’informatique décisionnelle , le cloud computing et les bases de données
- Visualisation, telle que des tableaux, des graphiques et d’autres affichages des données
Les mégadonnées multidimensionnelles peuvent également être représentées sous forme de cubes de données OLAP ou, mathématiquement, de tenseurs . Les systèmes de base de données de tableau ont pour objectif de fournir un stockage et une prise en charge des requêtes de haut niveau sur ce type de données. Les technologies supplémentaires appliquées aux mégadonnées comprennent le calcul efficace basé sur les tenseurs, [47] comme l’ apprentissage de sous-espace multilinéaire , [48] les bases de données de traitement massivement parallèle ( MPP ), les applications basées sur la recherche , l’exploration de données , [49] les systèmes de fichiers distribués , cache distribué (par exemple, burst buffer et Memcached ),les bases de données distribuées , les infrastructures basées sur le cloud et le HPC (applications, ressources de stockage et de calcul) [50] et Internet. [ citation nécessaire ] Bien que de nombreuses approches et technologies aient été développées, il reste encore difficile de réaliser un apprentissage automatique avec des mégadonnées. [51]
Certaines bases de données relationnelles MPP ont la capacité de stocker et de gérer des pétaoctets de données. Implicite est la capacité de charger, de surveiller, de sauvegarder et d’optimiser l’utilisation des grands tableaux de données dans le SGBDR . [52] [ source promotionnelle ? ]
Le programme d’analyse des données topologiques de la DARPA recherche la structure fondamentale d’ensembles de données massifs et, en 2008, la technologie est devenue publique avec le lancement d’une société appelée “Ayasdi”. [53] [ source tierce partie nécessaire ]
Les praticiens des processus d’analyse de données volumineuses sont généralement hostiles au stockage partagé plus lent, [54] préférant le stockage à connexion directe ( DAS ) sous ses diverses formes, du disque SSD au disque SATA haute capacité enfoui dans des nœuds de traitement parallèles. La perception des architectures de stockage partagées (réseau de stockage (SAN) et stockage en réseau (NAS)) est qu’elles sont relativement lentes, complexes et coûteuses. Ces qualités ne sont pas compatibles avec les systèmes d’analyse de données volumineuses qui se nourrissent de performances système, d’une infrastructure de base et d’un faible coût.
La diffusion d’informations en temps réel ou quasi réel est l’une des caractéristiques déterminantes de l’analyse des mégadonnées. La latence est donc évitée autant que possible. Les données en mémoire à connexion directe ou sur disque sont bonnes, mais pas les données en mémoire ou sur disque à l’autre extrémité d’une connexion FC SAN . Le coût d’un SAN à l’échelle requise pour les applications d’analyse est beaucoup plus élevé que les autres techniques de stockage.
Applications
 Bus enveloppé de big data SAP stationné à l’extérieur d’IDF13 .
Bus enveloppé de big data SAP stationné à l’extérieur d’IDF13 .
Le Big Data a tellement augmenté la demande de spécialistes de la gestion de l’information que Software AG , Oracle Corporation , IBM , Microsoft , SAP , EMC , HP et Dell ont dépensé plus de 15 milliards de dollars dans des éditeurs de logiciels spécialisés dans la gestion et l’analyse des données. En 2010, cette industrie valait plus de 100 milliards de dollars et augmentait de près de 10 % par an : environ deux fois plus vite que l’ensemble du secteur des logiciels. [5]
Les économies développées utilisent de plus en plus des technologies à forte intensité de données. Il y a 4,6 milliards d’abonnements à la téléphonie mobile dans le monde et entre 1 et 2 milliards de personnes accèdent à Internet. [5] Entre 1990 et 2005, plus d’un milliard de personnes dans le monde sont entrées dans la classe moyenne, ce qui signifie que davantage de personnes sont devenues plus alphabétisées, ce qui a entraîné une croissance de l’information. La capacité mondiale effective d’échanger des informations via les réseaux de télécommunication était de 281 pétaoctets en 1986, 471 pétaoctets en 1993, 2,2 exaoctets en 2000, 65 exaoctets en 2007 [10] et les prévisions évaluent la quantité de trafic Internet à 667 exaoctets par an d’ici 2014. [5 ]Selon une estimation, un tiers des informations stockées dans le monde se présentent sous la forme de texte alphanumérique et de données d’images fixes, [55] qui est le format le plus utile pour la plupart des applications de mégadonnées. Cela montre également le potentiel des données encore inutilisées (c’est-à-dire sous forme de contenu vidéo et audio).
Alors que de nombreux fournisseurs proposent des produits prêts à l’emploi pour le Big Data, les experts encouragent le développement de systèmes internes sur mesure si l’entreprise dispose de capacités techniques suffisantes. [56]
Gouvernement
L’utilisation et l’adoption des mégadonnées dans les processus gouvernementaux permettent des gains d’efficacité en termes de coût, de productivité et d’innovation, [57] mais ne sont pas sans défauts. L’analyse des données nécessite souvent que plusieurs parties du gouvernement (central et local) travaillent en collaboration et créent des processus nouveaux et innovants pour obtenir le résultat souhaité. Une organisation gouvernementale commune qui utilise les mégadonnées est la National Security Administration ( NSA ), qui surveille constamment les activités d’Internet à la recherche de modèles potentiels d’activités suspectes ou illégales que leur système pourrait détecter.
L’état civil et les statistiques de l’état civil (CRVS) recueillent tous les certificats d’état de la naissance au décès. Le CRVS est une source de mégadonnées pour les gouvernements.
Développement international
Les recherches sur l’utilisation efficace des technologies de l’information et de la communication pour le développement (également appelées « ICT4D ») suggèrent que la technologie des mégadonnées peut apporter des contributions importantes, mais également présenter des défis uniques au développement international . [58] [59] Les progrès de l’analyse des mégadonnées offrent des opportunités rentables pour améliorer la prise de décision dans des domaines de développement critiques tels que les soins de santé, l’emploi, la productivité économique , la criminalité, la sécurité et la gestion des catastrophes naturelles et des ressources. [60] [61] [62] De plus, les données générées par les utilisateurs offrent de nouvelles opportunités pour donner une voix aux inconnus. [63]Cependant, les défis de longue date pour les régions en développement, tels que l’infrastructure technologique inadéquate et la rareté des ressources économiques et humaines, exacerbent les préoccupations existantes concernant les mégadonnées telles que la confidentialité, la méthodologie imparfaite et les problèmes d’interopérabilité. [60] L’enjeu du “big data pour le développement” [60] évolue actuellement vers l’application de ces données par l’apprentissage automatique, connu sous le nom d'”intelligence artificielle pour le développement (AI4D)”. [64]
Avantages
Une application pratique majeure des mégadonnées pour le développement a été de “lutter contre la pauvreté avec les données”. [65] En 2015, Blumenstock et ses collègues ont estimé la pauvreté et la richesse prédites à partir des métadonnées des téléphones portables [66] et en 2016, Jean et ses collègues ont combiné l’imagerie satellite et l’apprentissage automatique pour prédire la pauvreté. [67] En utilisant des données de trace numériques pour étudier le marché du travail et l’économie numérique en Amérique latine, Hilbert et ses collègues [68] [69] soutiennent que les données de trace numériques présentent plusieurs avantages tels que :
- Couverture thématique : y compris les domaines qui étaient auparavant difficiles ou impossibles à mesurer
- Couverture géographique : nos sources internationales ont fourni des données importantes et comparables pour presque tous les pays, y compris de nombreux petits pays qui ne sont généralement pas inclus dans les inventaires internationaux
- Niveau de détail : fournir des données précises avec de nombreuses variables interdépendantes et de nouveaux aspects, tels que les connexions réseau
- Actualité et séries chronologiques : les graphiques peuvent être produits quelques jours après leur collecte
Défis
Dans le même temps, travailler avec des données de trace numériques au lieu de données d’enquête traditionnelles n’élimine pas les défis traditionnels liés au travail dans le domaine de l’analyse quantitative internationale. Les priorités changent, mais les discussions de base restent les mêmes. Parmi les principaux défis figurent :
- Représentativité. Alors que les statistiques de développement traditionnelles concernent principalement la représentativité des échantillons d’enquête aléatoires, les données de trace numériques ne sont jamais un échantillon aléatoire. [70]
- Généralisabilité. Alors que les données d’observation représentent toujours très bien cette source, elles ne représentent que ce qu’elle représente, et rien de plus. Bien qu’il soit tentant de généraliser des observations spécifiques d’une plate-forme à des contextes plus larges, cela est souvent très trompeur.
- Harmonisation. Les données de trace numériques nécessitent encore une harmonisation internationale des indicateurs. Il ajoute le défi de ce qu’on appelle la “fusion de données”, l’harmonisation des différentes sources.
- Surcharge de données. Les analystes et les institutions ne sont pas habitués à traiter efficacement un grand nombre de variables, ce qui est fait efficacement avec des tableaux de bord interactifs. Les praticiens manquent toujours d’un flux de travail standard qui permettrait aux chercheurs, aux utilisateurs et aux décideurs de travailler de manière efficace et efficiente. [68]
Soins de santé
L’analyse des mégadonnées a été utilisée dans les soins de santé en fournissant une médecine personnalisée et des analyses prescriptives, une intervention sur les risques cliniques et des analyses prédictives, une réduction de la variabilité des déchets et des soins, des rapports externes et internes automatisés sur les données des patients, des termes médicaux normalisés et des registres de patients. [71] [72] [73] [74] Certains domaines d’amélioration sont plus ambitieux que réellement mis en œuvre. Le niveau de données générées au sein des systèmes de santé n’est pas anodin. Avec l’adoption accrue des technologies mHealth, eHealth et portables, le volume de données continuera d’augmenter. Cela comprend le dossier de santé électroniquedonnées, données d’imagerie, données générées par le patient, données de capteur et autres formes de données difficiles à traiter. Il est désormais encore plus nécessaire que ces environnements accordent une plus grande attention à la qualité des données et des informations. [75] “Les mégadonnées signifient très souvent ‘ données sales ‘ et la fraction des inexactitudes de données augmente avec la croissance du volume de données.” L’inspection humaine à l’échelle des mégadonnées est impossible et les services de santé ont désespérément besoin d’outils intelligents pour le contrôle et le traitement de l’exactitude et de la crédibilité des informations manquées. [76] Bien que de nombreuses informations sur les soins de santé soient désormais électroniques, elles s’inscrivent dans le cadre des mégadonnées, car la plupart sont non structurées et difficiles à utiliser. [77]L’utilisation des mégadonnées dans les soins de santé a soulevé d’importants défis éthiques allant des risques pour les droits individuels, la vie privée et l’autonomie , à la transparence et à la confiance. [78]
Les mégadonnées dans la recherche en santé sont particulièrement prometteuses en termes de recherche biomédicale exploratoire, car l’analyse fondée sur les données peut avancer plus rapidement que la recherche fondée sur des hypothèses. [79] Ensuite, les tendances observées dans l’analyse des données peuvent être testées dans le cadre d’une recherche biologique de suivi traditionnelle fondée sur des hypothèses et éventuellement d’une recherche clinique.
Un sous-domaine d’application connexe, qui repose fortement sur les mégadonnées, dans le domaine de la santé est celui du diagnostic assisté par ordinateur en médecine. [80] Par exemple, pour le suivi de l’ épilepsie , il est d’usage de créer quotidiennement 5 à 10 Go de données. [81] De même, une seule image non compressée de tomosynthèse mammaire représente en moyenne 450 Mo de données. [82] Ce ne sont là que quelques-uns des nombreux exemples où le diagnostic assisté par ordinateur utilise des mégadonnées. Pour cette raison, les mégadonnées ont été reconnues comme l’un des sept défis clés que les systèmes de diagnostic assisté par ordinateur doivent surmonter afin d’atteindre le prochain niveau de performance. [83]
Éducation
Une étude du McKinsey Global Institute a révélé une pénurie de 1,5 million de professionnels et de gestionnaires de données hautement qualifiés [46] et un certain nombre d’universités [84] [ meilleure source nécessaire ] , dont l’Université du Tennessee et l’UC Berkeley , ont créé des programmes de maîtrise pour répondre à cette demande. Des camps d’entraînement privés ont également développé des programmes pour répondre à cette demande, y compris des programmes gratuits comme The Data Incubator ou des programmes payants comme General Assembly . [85] Dans le domaine spécifique du marketing, un des problèmes soulignés par Wedel et Kannan [86]est que le marketing comporte plusieurs sous-domaines (par exemple, la publicité, les promotions, le développement de produits, l’image de marque) qui utilisent tous différents types de données.
Médias
Pour comprendre comment les médias utilisent les mégadonnées, il est d’abord nécessaire de fournir un certain contexte dans le mécanisme utilisé pour le processus médiatique. Il a été suggéré par Nick Couldry et Joseph Turow que les praticiens des médias et de la publicité abordent les mégadonnées comme autant de points d’information exploitables sur des millions d’individus. L’industrie semble s’éloigner de l’approche traditionnelle consistant à utiliser des environnements médiatiques spécifiques tels que les journaux, les magazines ou les émissions de télévision et fait plutôt appel aux consommateurs avec des technologies qui atteignent des personnes ciblées à des moments optimaux et à des endroits optimaux. Le but ultime est de servir ou de véhiculer un message ou un contenu qui est (statistiquement parlant) en accord avec l’état d’esprit du consommateur. Par example,activités d’exploration de données . [87]
- Ciblage des consommateurs (pour la publicité par les commerçants) [88]
- Capture de données
- Journalisme de données : les éditeurs et les journalistes utilisent des outils de mégadonnées pour fournir des informations et des infographies uniques et innovantes .
Channel 4 , le diffuseur de télévision britannique de service public, est un leader dans le domaine du big data et de l’analyse de données . [89]
Assurance
Les prestataires d’assurance maladie collectent des données sur les “déterminants sociaux de la santé” tels que la consommation d’aliments et de télévision , l’état matrimonial, la taille des vêtements et les habitudes d’achat, à partir desquels ils font des prévisions sur les coûts de santé, afin de repérer les problèmes de santé chez leurs clients. Il est controversé de savoir si ces prévisions sont actuellement utilisées pour la tarification. [90]
Internet des objets (IdO)
Les mégadonnées et l’IdO fonctionnent de concert. Les données extraites des appareils IoT fournissent une cartographie de l’inter-connectivité des appareils. De telles cartographies ont été utilisées par l’industrie des médias, les entreprises et les gouvernements pour cibler plus précisément leur public et accroître l’efficacité des médias. L’IdO est également de plus en plus adopté comme moyen de collecte de données sensorielles, et ces données sensorielles ont été utilisées dans des contextes médicaux, [91] de fabrication [92] et de transport [93] .
Kevin Ashton , l’expert en innovation numérique qui est crédité d’avoir inventé le terme, [94] définit l’Internet des objets dans cette citation : “Si nous avions des ordinateurs qui savaient tout ce qu’il y avait à savoir sur les choses, en utilisant les données qu’ils ont recueillies sans l’aide de nous – nous serions en mesure de tout suivre et de tout compter, et de réduire considérablement le gaspillage, les pertes et les coûts. Nous saurions quand les choses doivent être remplacées, réparées ou rappelées, et si elles sont fraîches ou dépassées.
Informatique
Surtout depuis 2015, les mégadonnées ont pris de l’importance dans les opérations commerciales en tant qu’outil pour aider les employés à travailler plus efficacement et à rationaliser la collecte et la distribution des technologies de l’information (TI). L’utilisation des mégadonnées pour résoudre les problèmes informatiques et de collecte de données au sein d’une entreprise est appelée analyse des opérations informatiques (ITOA). [95] En appliquant les principes du Big Data aux concepts d’ intelligence artificielle et d’informatique en profondeur, les services informatiques peuvent prévoir les problèmes potentiels et les prévenir. [95] Les entreprises de l’ITOA proposent des plates-formes de gestion des systèmes qui apportent des silos de donnéesensemble et générer des informations à partir de l’ensemble du système plutôt qu’à partir de poches de données isolées.
Études de cas
Gouvernement
Chine
- La plateforme intégrée d’opérations conjointes (IJOP, 一体化联合作战平台) est utilisée par le gouvernement pour surveiller la population, en particulier les Ouïghours . [96] La biométrie , y compris les échantillons d’ADN, est recueillie grâce à un programme d’examens physiques gratuits. [97]
- D’ici 2020, la Chine prévoit d’attribuer à tous ses citoyens un score personnel de “crédit social” basé sur leur comportement. [98] Le système de crédit social , actuellement testé dans un certain nombre de villes chinoises, est considéré comme une forme de surveillance de masse qui utilise la technologie d’analyse des mégadonnées. [99] [ douteux – discuter ] [100]
Inde
- L’analyse de mégadonnées a été testée pour que le BJP remporte les élections générales indiennes de 2014. [101]
- Le gouvernement indien utilise de nombreuses techniques pour déterminer comment l’électorat indien réagit à l’action du gouvernement, ainsi que des idées d’augmentation des politiques.
Israël
- Des traitements personnalisés du diabète peuvent être créés grâce à la solution Big Data de GlucoMe. [102]
Royaume-Uni
Exemples d’utilisations du big data dans les services publics :
- Données sur les médicaments délivrés sur ordonnance : en reliant l’origine, le lieu et l’heure de chaque ordonnance, une unité de recherche a pu illustrer et examiner le délai considérable entre la sortie d’un médicament donné et une adaptation à l’échelle du Royaume-Uni du National Institute for Health and Lignes directrices sur l’excellence des soins . Cela suggère que les médicaments nouveaux ou les plus récents mettent un certain temps à se diffuser chez le patient en général. [ citation nécessaire ] [103]
- Regrouper les données : une autorité locale a combiné des données sur les services, tels que les rotations de sablage des routes, avec des services pour les personnes à risque, tels que Meals on Wheels . La connexion des données a permis à l’autorité locale d’éviter tout retard lié à la météo. [104]
États-Unis
- En 2012, l’ administration Obama a annoncé la Big Data Research and Development Initiative, pour explorer comment les mégadonnées pourraient être utilisées pour résoudre les problèmes importants auxquels le gouvernement est confronté. [105] L’initiative est composée de 84 programmes différents de mégadonnées répartis dans six ministères. [106]
- L’analyse des mégadonnées a joué un rôle important dans la campagne de réélection réussie de Barack Obama en 2012 . [107]
- Le gouvernement fédéral des États-Unis possède cinq des dix supercalculateurs les plus puissants au monde. [108] [109]
- Le centre de données de l’Utah a été construit par la National Security Agency des États-Unis . Une fois terminée, l’installation sera en mesure de traiter une grande quantité d’informations collectées par la NSA sur Internet. La quantité exacte d’espace de stockage est inconnue, mais des sources plus récentes affirment qu’elle sera de l’ordre de quelques exaoctets . [110] [111] [112] Cela a posé des problèmes de sécurité concernant l’anonymat des données recueillies. [113]
Détail
- Walmart traite plus d’un million de transactions clients chaque heure, qui sont importées dans des bases de données estimées contenir plus de 2,5 pétaoctets (2560 téraoctets) de données, soit l’équivalent de 167 fois les informations contenues dans tous les livres de la US Library of Congress . [5]
- Windermere Real Estate utilise les informations de localisation de près de 100 millions de conducteurs pour aider les nouveaux acheteurs à déterminer leurs temps de trajet typiques vers et depuis le travail à différents moments de la journée. [114]
- Le système de détection de carte FICO protège les comptes dans le monde entier. [115]
Science
- Les expériences du Large Hadron Collider représentent environ 150 millions de capteurs délivrant des données 40 millions de fois par seconde. Il y a près de 600 millions de collisions par seconde. Après avoir filtré et évité d’enregistrer plus de 99,99995 % [116] de ces flux, il y a 1 000 collisions intéressantes par seconde. [117] [118] [119]
- Par conséquent, en ne travaillant qu’avec moins de 0,001 % des données du flux de capteurs, le flux de données des quatre expériences LHC représente un débit annuel de 25 pétaoctets avant réplication (à partir de 2012 [update]). Cela devient près de 200 pétaoctets après la réplication.
- Si toutes les données des capteurs étaient enregistrées dans le LHC, le flux de données serait extrêmement difficile à gérer. Le flux de données dépasserait 150 millions de pétaoctets en rythme annuel, soit près de 500 exaoctets par jour, avant réplication. Pour mettre le chiffre en perspective, cela équivaut à 500 quintillions (5×10 20 ) d’octets par jour, presque 200 fois plus que toutes les autres sources combinées dans le monde.
- Le Square Kilometre Array est un radiotélescope composé de milliers d’antennes. Il devrait être opérationnel d’ici 2024. Collectivement, ces antennes devraient collecter 14 exaoctets et stocker un pétaoctet par jour. [120] [121] Il est considéré comme l’un des projets scientifiques les plus ambitieux jamais entrepris. [122]
- Lorsque le Sloan Digital Sky Survey (SDSS) a commencé à collecter des données astronomiques en 2000, il en a amassé plus au cours de ses premières semaines que toutes les données collectées dans l’histoire de l’astronomie auparavant. Continuant à un rythme d’environ 200 Go par nuit, SDSS a amassé plus de 140 téraoctets d’informations. [5] Lorsque le Large Synoptic Survey Telescope , successeur du SDSS, sera mis en ligne en 2020, ses concepteurs s’attendent à ce qu’il acquière cette quantité de données tous les cinq jours. [5]
- Le décodage du génome humain a demandé à l’origine 10 ans de traitement ; maintenant, il peut être atteint en moins d’une journée. Les séquenceurs d’ADN ont divisé le coût du séquençage par 10 000 au cours des dix dernières années, soit 100 fois moins cher que la réduction de coût prédite par la loi de Moore . [123]
- Le Centre de simulation climatique de la NASA (NCCS) stocke 32 pétaoctets d’observations et de simulations climatiques sur le cluster de supercalcul Discover. [124] [125]
- DNAStack de Google compile et organise des échantillons d’ADN de données génétiques du monde entier pour identifier les maladies et autres défauts médicaux. Ces calculs rapides et précis éliminent tout “point de friction” ou toute erreur humaine qui pourrait être commise par l’un des nombreux experts scientifiques et biologiques travaillant avec l’ADN. DNAStack, une partie de Google Genomics, permet aux scientifiques d’utiliser instantanément le vaste échantillon de ressources du serveur de recherche de Google pour mettre à l’échelle des expériences sociales qui prendraient généralement des années. [126] [127]
- La base de données ADN de 23andme contient les informations génétiques de plus d’un million de personnes dans le monde. [128] La société envisage de vendre les “données génétiques agrégées anonymes” à d’autres chercheurs et sociétés pharmaceutiques à des fins de recherche si les patients donnent leur consentement. [129] [130] [131] [132] [133] Ahmad Hariri, professeur de psychologie et de neurosciences à l’Université Duke qui utilise 23andMe dans ses recherches depuis 2009 déclare que l’aspect le plus important du nouveau service de l’entreprise est qu’il rend la recherche génétique accessible et relativement bon marché pour les scientifiques. [129]Une étude qui a identifié 15 sites génomiques liés à la dépression dans la base de données de 23andMe a entraîné une augmentation des demandes d’accès au référentiel, 23andMe ayant répondu à près de 20 demandes d’accès aux données sur la dépression dans les deux semaines suivant la publication de l’article. [134]
- La dynamique des fluides computationnelle ( CFD ) et la recherche sur la turbulence hydrodynamique génèrent des ensembles de données massifs. Les bases de données Johns Hopkins Turbulence Databases ( JHTDB ) contiennent plus de 350 téraoctets de champs spatio-temporels issus de simulations numériques directes de divers écoulements turbulents. Ces données ont été difficiles à partager en utilisant des méthodes traditionnelles telles que le téléchargement de fichiers de sortie de simulation plats. Les données de JHTDB sont accessibles à l’aide de “capteurs virtuels” avec différents modes d’accès allant des requêtes directes du navigateur Web à l’accès via les programmes Matlab, Python, Fortran et C s’exécutant sur les plates-formes des clients, en passant par la suppression de services pour télécharger des données brutes. Les données ont été utilisées dans plus de 150 publications scientifiques.
Des sports
Les mégadonnées peuvent être utilisées pour améliorer l’entraînement et la compréhension des concurrents, à l’aide de capteurs sportifs. Il est également possible de prédire les gagnants d’un match à l’aide d’analyses de données volumineuses. [135] Les performances futures des joueurs pourraient également être prédites. Ainsi, la valeur et le salaire des joueurs sont déterminés par les données collectées tout au long de la saison. [136]
Dans les courses de Formule 1, les voitures de course dotées de centaines de capteurs génèrent des téraoctets de données. Ces capteurs collectent des points de données allant de la pression des pneus à l’efficacité de la consommation de carburant. [137] Sur la base des données, les ingénieurs et les analystes de données décident si des ajustements doivent être faits pour gagner une course. De plus, en utilisant le big data, les équipes de course tentent de prédire l’heure à laquelle elles finiront la course à l’avance, sur la base de simulations utilisant des données collectées au cours de la saison. [138]
Technologie
- eBay.com utilise deux entrepôts de données à 7,5 pétaoctets et 40 Po ainsi qu’un cluster Hadoop de 40 Po pour la recherche, les recommandations aux consommateurs et le merchandising. [139]
- Amazon.com gère chaque jour des millions d’opérations back-end, ainsi que des requêtes de plus d’un demi-million de vendeurs tiers. La technologie de base qui permet à Amazon de fonctionner est basée sur Linux et, en 2005 [update], ils disposaient des trois plus grandes bases de données Linux au monde, avec des capacités de 7,8 To, 18,5 To et 24,7 To. [140]
- Facebook gère 50 milliards de photos de sa base d’utilisateurs. [141] En juin 2017 [update], Facebook atteignait 2 milliards d’utilisateurs actifs par mois . [142]
- Google traitait environ 100 milliards de recherches par mois en août 2012 [update]. [143]
COVID-19 [feminine]
Au cours de la pandémie de COVID-19 , les mégadonnées ont été collectées afin de minimiser l’impact de la maladie. Les applications importantes des mégadonnées comprenaient la minimisation de la propagation du virus, l’identification des cas et le développement de traitements médicaux. [144]
Les gouvernements ont utilisé les mégadonnées pour suivre les personnes infectées afin de minimiser la propagation. Les premiers utilisateurs comprenaient la Chine, Taïwan, la Corée du Sud et Israël. [145] [146] [147]
Activités de recherche
La recherche cryptée et la formation de clusters dans les mégadonnées ont été démontrées en mars 2014 à l’American Society of Engineering Education. Gautam Siwach s’est engagé à relever les défis du Big Data par le laboratoire d’ informatique et d’intelligence artificielle du MITet Amir Esmailpour du groupe de recherche de l’UNH a étudié les principales caractéristiques des mégadonnées en tant que formation de clusters et leurs interconnexions. Ils se sont concentrés sur la sécurité des mégadonnées et l’orientation du terme vers la présence de différents types de données sous une forme cryptée à l’interface cloud en fournissant les définitions brutes et des exemples en temps réel au sein de la technologie. De plus, ils ont proposé une approche pour identifier la technique de codage pour progresser vers une recherche accélérée sur du texte crypté conduisant à des améliorations de la sécurité dans les mégadonnées. [148]
En mars 2012, la Maison Blanche a annoncé une « Initiative Big Data » nationale composée de six ministères et organismes fédéraux engageant plus de 200 millions de dollars dans des projets de recherche sur les mégadonnées. [149]
L’initiative comprenait une subvention “Expeditions in Computing” de la National Science Foundation de 10 millions de dollars sur cinq ans à l’AMPLab [150] de l’Université de Californie à Berkeley. [151] L’AMPLab a également reçu des fonds de la DARPA et de plus d’une douzaine de sponsors industriels et utilise les mégadonnées pour s’attaquer à un large éventail de problèmes, de la prévision des embouteillages [152] à la lutte contre le cancer. [153]
L’initiative Big Data de la Maison Blanche comprenait également un engagement du ministère de l’Énergie à fournir un financement de 25 millions de dollars sur cinq ans pour établir l’Institut de gestion, d’analyse et de visualisation des données évolutives (SDAV), [154] dirigé par Lawrence Berkeley National du ministère de l’Énergie. Laboratoire . L’Institut SDAV a pour objectif de fédérer les expertises de six laboratoires nationaux et de sept universités pour développer de nouveaux outils d’aide à la gestion et à la visualisation des données sur les supercalculateurs du département.
L’État américain du Massachusetts a annoncé la Massachusetts Big Data Initiative en mai 2012, qui fournit un financement du gouvernement de l’État et d’entreprises privées à une variété d’instituts de recherche. [155] Le Massachusetts Institute of Technology héberge le Intel Science and Technology Center for Big Data dans le laboratoire d’informatique et d’intelligence artificielle du MIT , combinant des efforts de financement et de recherche du gouvernement, des entreprises et des institutions. [156]
La Commission européenne finance le Forum public-privé sur les mégadonnées, d’une durée de deux ans, par le biais de son septième programme-cadre, afin d’engager les entreprises, les universitaires et d’autres parties prenantes à discuter des problèmes liés aux mégadonnées. Le projet vise à définir une stratégie en matière de recherche et d’innovation pour guider les actions d’accompagnement de la Commission européenne dans la mise en place réussie de l’économie du big data. Les résultats de ce projet serviront de base à Horizon 2020 , leur prochain programme – cadre . [157]
Le gouvernement britannique a annoncé en mars 2014 la création de l’ Institut Alan Turing , du nom du pionnier de l’informatique et de la décryptage, qui se concentrera sur de nouvelles façons de collecter et d’analyser de grands ensembles de données. [158]
Lors de la journée d’inspiration de l’expérience canadienne des données ouvertes (CODE) de l’ Université de Waterloo à Stratford , les participants ont démontré comment l’utilisation de la visualisation des données peut accroître la compréhension et l’attrait des grands ensembles de données et communiquer leur histoire au monde. [159]
Sciences sociales computationnelles – N’importe qui peut utiliser les interfaces de programmation d’applications (API) fournies par les détenteurs de mégadonnées, tels que Google et Twitter, pour effectuer des recherches dans les sciences sociales et comportementales. [160] Souvent, ces API sont fournies gratuitement. [160] Tobias Preis et al. ont utilisé les données de Google Trends pour démontrer que les internautes des pays dont le produit intérieur brut (PIB) par habitant est plus élevé sont plus susceptibles de rechercher des informations sur l’avenir que des informations sur le passé. Les résultats suggèrent qu’il pourrait y avoir un lien entre les comportements en ligne et les indicateurs économiques réels. [161] [162] [163]Les auteurs de l’étude ont examiné les logs de requêtes Google réalisés par rapport du volume de recherches de l’année à venir (2011) au volume de recherches de l’année précédente (2009), qu’ils appellent le « future orientation index ». [164] Ils ont comparé l’indice d’orientation future au PIB par habitant de chaque pays et ont constaté une forte tendance pour les pays où les utilisateurs de Google se renseignent davantage sur l’avenir à avoir un PIB plus élevé.
Tobias Preis et ses collègues Helen Susannah Moat et H. Eugene Stanley ont introduit une méthode pour identifier les précurseurs en ligne des mouvements boursiers, en utilisant des stratégies de trading basées sur les données de volume de recherche fournies par Google Trends. [165] Leur analyse du volume de recherche Google pour 98 termes de pertinence financière variable, publiée dans Scientific Reports , [166] suggère que les augmentations du volume de recherche pour les termes de recherche financièrement pertinents ont tendance à précéder les pertes importantes sur les marchés financiers. [167] [168] [169] [170] [171] [172] [173]
Les grands ensembles de données s’accompagnent de défis algorithmiques qui n’existaient pas auparavant. Par conséquent, certains considèrent qu’il est nécessaire de modifier fondamentalement les méthodes de traitement. [174]
Les Workshops on Algorithms for Modern Massive Data Sets (MMDS) rassemblent des informaticiens, des statisticiens, des mathématiciens et des praticiens de l’analyse de données pour discuter des défis algorithmiques du big data. [175] En ce qui concerne les mégadonnées, ces concepts de magnitude sont relatifs. Comme il est dit “Si le passé est d’une quelconque orientation, alors les mégadonnées d’aujourd’hui ne seront très probablement pas considérées comme telles dans un avenir proche”. [80]
Échantillonnage de mégadonnées
Une question de recherche posée sur les grands ensembles de données est de savoir s’il est nécessaire d’examiner les données complètes pour tirer certaines conclusions sur les propriétés des données ou si un échantillon est suffisamment bon. Le nom Big Data lui-même contient un terme lié à la taille et c’est une caractéristique importante du Big Data. Mais l’échantillonnagepermet de sélectionner les bons points de données à partir de l’ensemble de données plus large pour estimer les caractéristiques de l’ensemble de la population. Lors de la fabrication, différents types de données sensorielles telles que l’acoustique, les vibrations, la pression, le courant, la tension et les données du contrôleur sont disponibles à de courts intervalles de temps. Pour prédire les temps d’arrêt, il n’est peut-être pas nécessaire d’examiner toutes les données, mais un échantillon peut suffire. Les mégadonnées peuvent être décomposées en différentes catégories de points de données telles que les données démographiques, psychographiques, comportementales et transactionnelles. Avec de grands ensembles de points de données, les spécialistes du marketing sont en mesure de créer et d’utiliser des segments de consommateurs plus personnalisés pour un ciblage plus stratégique.
Des travaux ont été effectués sur les algorithmes d’échantillonnage pour les mégadonnées. Une formulation théorique pour l’échantillonnage des données Twitter a été développée. [176]
La critique
Les critiques du paradigme des mégadonnées sont de deux types : celles qui remettent en question les implications de l’approche elle-même et celles qui remettent en question la manière dont elle est actuellement appliquée. [177] Une approche à cette critique est le domaine des études de données critiques .
Critiques du paradigme du big data
“Un problème crucial est que nous ne savons pas grand-chose sur les micro-processus empiriques sous-jacents qui conduisent à l’émergence des caractéristiques de réseau typiques du Big Data.” [18] Dans leur critique, Snijders, Matzat et Reips soulignent que des hypothèses souvent très fortes sont faites sur les propriétés mathématiques qui peuvent ne pas du tout refléter ce qui se passe réellement au niveau des micro-processus. Mark Graham a émis de larges critiques à l’affirmation de Chris Anderson selon laquelle les mégadonnées sonneront le glas de la théorie : [178] en se concentrant en particulier sur la notion que les mégadonnées doivent toujours être contextualisées dans leurs contextes sociaux, économiques et politiques. [179]Alors même que les entreprises investissent des sommes à huit et neuf chiffres pour obtenir des informations sur les flux d’informations provenant des fournisseurs et des clients, moins de 40 % des employés disposent de processus et de compétences suffisamment matures pour le faire. Pour surmonter ce déficit de perspicacité, les données volumineuses, aussi complètes soient-elles ou bien analysées, doivent être complétées par un “grand jugement”, selon un article de la Harvard Business Review . [180]
Dans le même ordre d’idées, il a été souligné que les décisions fondées sur l’analyse des mégadonnées sont inévitablement “informées par le monde tel qu’il était dans le passé, ou, au mieux, tel qu’il est actuellement”. [60] Alimentés par un grand nombre de données sur les expériences passées, les algorithmes peuvent prédire l’évolution future si l’avenir est similaire au passé. [181] Si la dynamique du futur du système change (s’il ne s’agit pas d’un processus stationnaire ), le passé peut dire peu de choses sur l’avenir. Afin de faire des prédictions dans des environnements changeants, il serait nécessaire d’avoir une compréhension approfondie de la dynamique des systèmes, ce qui nécessite une théorie. [181]En réponse à cette critique, Alemany Oliver et Vayre proposent d’utiliser “le raisonnement abductif comme première étape du processus de recherche afin de contextualiser les traces numériques des consommateurs et faire émerger de nouvelles théories”. [182] De plus, il a été suggéré de combiner des approches de mégadonnées avec des simulations informatiques, telles que des modèles à base d’agents [60] et des systèmes complexes . Les modèles basés sur les agents s’améliorent de plus en plus pour prédire le résultat des complexités sociales de scénarios futurs, même inconnus, grâce à des simulations informatiques basées sur une collection d’algorithmes mutuellement interdépendants. [183] [184] Enfin, l’utilisation de méthodes multivariées qui sondent la structure latente des données, telles quel’analyse factorielle et l’analyse par grappes se sont avérées utiles en tant qu’approches analytiques qui vont bien au-delà des approches à deux variables (par exemple , les tableaux de contingence ) généralement employées avec des ensembles de données plus petits.
En santé et en biologie, les approches scientifiques conventionnelles reposent sur l’expérimentation. Pour ces approches, le facteur limitant est les données pertinentes qui peuvent confirmer ou infirmer l’hypothèse initiale. [185] Un nouveau postulat est désormais accepté en biosciences : l’information apportée par les données en masse ( omics ) sans hypothèse préalable est complémentaire et parfois nécessaire aux approches conventionnelles basées sur l’expérimentation. [186] [187] Dans les approches massives c’est la formulation d’une hypothèse pertinente pour expliquer les données qui est le facteur limitant. [188] La logique de recherche est inversée et les limites de l’induction (“Glory of Science and Philosophy scandale”, CD Broad, 1926) sont à considérer. [ citation nécessaire ]
Les défenseurs de la vie privée s’inquiètent de la menace pour la vie privée représentée par le stockage et l’intégration croissants d’ informations personnellement identifiables ; Des groupes d’experts ont publié diverses recommandations politiques pour conformer la pratique aux attentes en matière de confidentialité. [189] L’utilisation abusive des mégadonnées dans plusieurs cas par les médias, les entreprises et même le gouvernement a permis l’abolition de la confiance dans presque toutes les institutions fondamentales qui soutiennent la société. [190]
Nayef Al-Rodhan soutient qu’un nouveau type de contrat social sera nécessaire pour protéger les libertés individuelles dans le contexte des mégadonnées et des sociétés géantes qui possèdent de grandes quantités d’informations, et que l’utilisation des mégadonnées devrait être surveillée et mieux réglementée au niveau niveaux national et international. [191] Barocas et Nissenbaum soutiennent qu’une façon de protéger les utilisateurs individuels consiste à être informés des types de renseignements recueillis, avec qui ils sont partagés, sous quelles contraintes et à quelles fins. [192]
Critiques du modèle “V”
Le modèle en « V » des données volumineuses est préoccupant car il se concentre sur l’évolutivité des calculs et manque de perte autour de la perceptibilité et de la compréhensibilité des informations. Cela a conduit au cadre du big data cognitif , qui caractérise les applications du big data selon : [193]
- Complétude des données : compréhension du non-évident des données
- Corrélation des données, causalité et prévisibilité : la causalité n’est pas une exigence essentielle pour atteindre la prévisibilité
- Explicabilité et interprétabilité : les humains désirent comprendre et accepter ce qu’ils comprennent, là où les algorithmes ne font pas face à cela
- Niveau de prise de décision automatisée : algorithmes qui prennent en charge la prise de décision automatisée et l’auto-apprentissage algorithmique
Critiques de la nouveauté
De grands ensembles de données ont été analysés par des machines informatiques pendant plus d’un siècle, y compris l’analyse du recensement américain effectuée par les machines à cartes perforées d’ IBM qui ont calculé des statistiques comprenant des moyennes et des variances de populations sur l’ensemble du continent. Au cours des dernières décennies, des expériences scientifiques telles que le CERN ont produit des données à des échelles similaires aux “big data” commerciales actuelles. Cependant, les expériences scientifiques ont eu tendance à analyser leurs données à l’aide de clusters et de grilles de calcul haute performance (super-calcul) spécialisés et personnalisés, plutôt que de nuages d’ordinateurs de base bon marché comme dans la vague commerciale actuelle, ce qui implique une différence à la fois culturelle et technologique. pile.
Critiques de l’exécution du Big Data
Ulf-Dietrich Reips et Uwe Matzat ont écrit en 2014 que le big data était devenu une « mode » dans la recherche scientifique. [160] Le chercheur danah boyd a soulevé des inquiétudes quant à l’utilisation des mégadonnées en science en négligeant des principes tels que le choix d’un échantillon représentatif en étant trop préoccupé par le traitement d’énormes quantités de données. [194] Cette approche peut conduire à des résultats biaisés d’une manière ou d’une autre. [195]L’intégration entre des ressources de données hétérogènes – certaines pouvant être considérées comme des mégadonnées et d’autres non – présente de formidables défis logistiques et analytiques, mais de nombreux chercheurs affirment que de telles intégrations sont susceptibles de représenter les nouvelles frontières les plus prometteuses de la science. [196] Dans l’article provocateur “Critical Questions for Big Data”, [197] les auteurs intitulent le big data comme faisant partie de la mythologie : “les grands ensembles de données offrent une forme supérieure d’intelligence et de connaissance […], avec l’aura de vérité, objectivité et exactitude ». Les utilisateurs de Big Data sont souvent “perdus dans le volume des chiffres”, et “travailler avec le Big Data est encore subjectif, et ce qu’il quantifie n’a pas nécessairement une prétention plus proche à la vérité objective”.Les développements récents dans le domaine de la BI, tels que le reporting proactif, ciblent en particulier l’amélioration de l’utilisabilité des données volumineuses, grâce au filtrage automatisé des données et des corrélations non utiles . [198] Les grandes structures sont pleines de fausses corrélations [199] soit en raison de coïncidences non causales ( loi des très grands nombres ), soit uniquement de la nature du grand hasard [200] ( théorie de Ramsey ), soit de l’existence de facteurs non inclus de sorte que la l’espoir des premiers expérimentateurs de faire “parler d’eux-mêmes” de grandes bases de données de nombres et de révolutionner la méthode scientifique, est remis en question. [201] Catherine Tuckera souligné le « battage publicitaire » autour des mégadonnées, en écrivant « En soi, les mégadonnées ont peu de chance d’être utiles ». L’article explique : “Les nombreux contextes où les données sont bon marché par rapport au coût de rétention des talents pour les traiter, suggèrent que les compétences de traitement sont plus importantes que les données elles-mêmes dans la création de valeur pour une entreprise.” [202]
L’analyse de données volumineuses est souvent superficielle par rapport à l’analyse d’ensembles de données plus petits. [203] Dans de nombreux projets de mégadonnées, il n’y a pas d’analyse de données volumineuses, mais le défi est l’ extraction, la transformation et le chargement d’une partie du prétraitement des données. [203]
Le big data est un mot à la mode et un “terme vague”, [204] [205] mais en même temps une “obsession” [205] pour les entrepreneurs, les consultants, les scientifiques et les médias. Les grandes vitrines de données telles que Google Flu Trends n’ont pas fourni de bonnes prédictions ces dernières années, multipliant par deux les épidémies de grippe. De même, les Oscarset les prédictions électorales uniquement basées sur Twitter étaient plus souvent erronées que ciblées. Les mégadonnées posent souvent les mêmes défis que les petites données ; ajouter plus de données ne résout pas les problèmes de biais, mais peut mettre en évidence d’autres problèmes. En particulier, les sources de données telles que Twitter ne sont pas représentatives de la population globale, et les résultats tirés de ces sources peuvent alors conduire à des conclusions erronées. Google Traduction , qui est basé sur l’analyse statistique de données volumineuses sur le texte, fait un bon travail pour traduire des pages Web. Cependant, les résultats des domaines spécialisés peuvent être considérablement faussés. D’autre part, les mégadonnées peuvent également introduire de nouveaux problèmes, tels que le problème des comparaisons multiples: tester simultanément un grand nombre d’hypothèses est susceptible de produire de nombreux résultats erronés qui semblent erronément significatifs. Ioannidis a fait valoir que “la plupart des résultats de recherche publiés sont faux” [206] en raison essentiellement du même effet : lorsque de nombreuses équipes scientifiques et chercheurs effectuent chacun de nombreuses expériences (c’est-à-dire traitent une grande quantité de données scientifiques ; mais pas avec la technologie des mégadonnées), le la probabilité qu’un résultat “significatif” soit faux augmente rapidement – d’autant plus lorsque seuls des résultats positifs sont publiés. De plus, la qualité des résultats de l’analyse des données volumineuses dépend du modèle sur lequel elles reposent. Dans un exemple, les mégadonnées ont participé à la tentative de prédire les résultats de l’élection présidentielle américaine de 2016 [207] avec plus ou moins de succès.
Critiques de la police et de la surveillance des mégadonnées
Les mégadonnées ont été utilisées dans le maintien de l’ordre et la surveillance par des institutions telles que les forces de l’ordre et les entreprises . [208] En raison de la nature moins visible de la surveillance basée sur les données par rapport aux méthodes traditionnelles de maintien de l’ordre, les objections au maintien de l’ordre des mégadonnées sont moins susceptibles de survenir. Selon Sarah Brayne’s Big Data Surveillance: The Case of Policing [209] , la police des mégadonnées peut reproduire les inégalités sociétales existantes de trois façons :
- Placer les criminels présumés sous surveillance accrue en utilisant la justification d’un algorithme mathématique et donc impartial
- Accroître la portée et le nombre de personnes faisant l’objet d’un suivi des forces de l’ordre et exacerber la surreprésentation raciale existante dans le système de justice pénale
- Encourager les membres de la société à abandonner les interactions avec les institutions qui créeraient une trace numérique, créant ainsi des obstacles à l’inclusion sociale
Si ces problèmes potentiels ne sont pas corrigés ou réglementés, les effets de la police du Big Data pourraient continuer à façonner les hiérarchies sociétales. L’utilisation consciencieuse de la police des mégadonnées pourrait empêcher les préjugés au niveau individuel de devenir des préjugés institutionnels, note également Brayne.
Dans la culture populaire
Livres
- Moneyball est un livre de non-fiction qui explore comment les Oakland Athletics ont utilisé l’analyse statistique pour surpasser les équipes avec des budgets plus importants. En 2011, une adaptation cinématographique mettant en vedette Brad Pitt est sortie.
Film
- Dans Captain America : The Winter Soldier , HYDRA (déguisé en SHIELD ) développe des héliporteurs qui utilisent des données pour déterminer et éliminer les menaces sur le globe.
- Dans The Dark Knight , Batman utilise un appareil sonar qui peut espionner tout Gotham City . Les données sont recueillies à partir des téléphones portables des habitants de la ville.
Voir également
Pour une liste des entreprises et des outils, voir aussi : Catégorie : Big data
- Éthique des mégadonnées
- Modèle de maturité des mégadonnées
- Grande mémoire
- Conservation des données
- Stockage défini par les données
- Lignage des données
- Philanthropie des données
- Science des données
- Datafication
- Base de données orientée documents
- Traitement en mémoire
- Liste des grandes entreprises de données
- Informatique urbaine
- Très grande base de données
- XLDB
Références
- ^ Hilbert, Martin; Lopez, Priscila (2011). “La capacité technologique mondiale à stocker, communiquer et calculer des informations” . Sciences . 332 (6025): 60–65. Bibcode : 2011Sci…332…60H . doi : 10.1126/science.1200970 . PMID 21310967 . S2CID 206531385 . Récupéré le 13 avril 2016 .
- ^ Breur, Tom (juillet 2016). “L’analyse statistique des pouvoirs et la “crise” contemporaine des sciences sociales” . Journal d’analyse marketing . Londres, Angleterre : Palgrave Macmillan . 4 (2–3) : 61–65. doi : 10.1057/s41270-016-0001-3 . ISSN 2050-3318 .
- ^ un b “Les 5 V de grandes données” . Perspectives de la santé Watson . 17 septembre 2016 . Récupéré le 20 janvier 2021 .
- ^ boyd, dana; Crawford, Kate (21 septembre 2011). “Six provocations pour le Big Data” . Réseau de recherche en sciences sociales : Une décennie à l’heure d’Internet : Symposium sur la dynamique d’Internet et de la société . doi : 10.2139/ssrn.1926431 . S2CID 148610111 .
- ^ un bcdefg ” Données , données partout ” . L’Économiste . 25 février 2010 . Récupéré le 9 décembre 2012 .
- ^ “Intelligence communautaire requise” . Nature . 455 (7209): 1. Septembre 2008. Bibcode : 2008Natur.455….1. . doi : 10.1038/455001a . PMID 18769385 .
- ^ Reichman JO, Jones MB, Schildhauer MP (février 2011). “Défis et opportunités de l’open data en écologie” . Sciences . 331 (6018) : 703–5. Bibcode : 2011Sci…331..703R . doi : 10.1126/science.1197962 . PMID 21311007 . S2CID 22686503 .
- ^ Hellerstein, Joe (9 novembre 2008). “La programmation parallèle à l’ère du Big Data” . Blog Gigaom .
- ^ Segaran, Toby; Hammerbacher, Jeff (2009). De belles données : les histoires derrière des solutions de données élégantes . O’Reilly Media. p. 257. ISBN 978-0-596-15711-1.
- ^ un b Hilbert M, López P (avril 2011). “La capacité technologique du monde à stocker, communiquer et calculer des informations” (PDF) . Sciences . 332 (6025): 60–5. Bibcode : 2011Sci…332…60H . doi : 10.1126/science.1200970 . PMID 21310967 . S2CID 206531385 .
- ^ “IBM Qu’est-ce que le big data ? – Apporter le big data à l’entreprise” . ibm.com . Récupéré le 26 août 2013 .
- ^ Reinsel, David; Gantz, John; Rydning, John (13 avril 2017). ” Data Age 2025: L’évolution des données vers la vie critique ” (PDF) . seagate.com . Framingham, MA, États-Unis : International Data Corporation . Récupéré le 2 novembre 2017 .
- ^ Oracle et FSN, “Mastering Big Data: CFO Strategies to Transform Insight into Opportunity” Archivé le 4 août 2013 à la Wayback Machine , décembre 2012
- ^ Jacobs, A. (6 juillet 2009). « Les pathologies du Big Data » . ACMQueue .
- ↑ Magoulas, Roger ; Lorica, Ben (février 2009). “Introduction au Big Data” . Version 2.0 . Sébastopol CA : O’Reilly Media (11).
- ^ John R. Mashey (25 avril 1998). “Big Data … et la prochaine vague d’infrastress” (PDF) . Diapositives de la conférence invitée . Usenix . Récupéré le 28 septembre 2016 .
- ^ Steve Lohr (1er février 2013). “Les origines du ‘Big Data’ : une histoire policière étymologique” . Le New York Times . Récupéré le 28 septembre 2016 .
- ^ un b Snijders, C.; Matzat, U. ; Reips, U.-D. (2012). ” ‘Big Data’ : grandes lacunes dans les connaissances dans le domaine d’Internet” . International Journal of Internet Science . 7 : 1–5.
- ^ Dedić, N.; En ligneStanier, C. (2017). “Vers une différenciation de la Business Intelligence, du Big Data, de l’analyse des données et de la découverte des connaissances” . Innovations dans la gestion et l’ingénierie des systèmes d’information d’entreprise . Notes de cours sur le traitement de l’information commerciale. Vol. 285.Berlin ; Heidelberg : Springer International Publishing. p. 114–122. doi : 10.1007/978-3-319-58801-8_10 . ISBN 978-3-319-58800-1. ISSN 1865-1356 . OCLC 909580101 .
- ^ Everts, Sarah (2016). “Surcharge d’informations” . Distillations . Vol. 2, non. 2. p. 26–33 . Récupéré le 22 mars 2018 .
- ^ Ibrahim; Targio Hachem, Abaker ; Yacoob, Ibrar ; Badrul Anuar, Nor ; Mokhtar, Salimah; Gani, Abdallah ; Ullah Khan, Samee (2015). “big data” on cloud computing: Review and open research issues”. Information Systems . 47 : 98–115. doi : 10.1016/j.is.2014.07.006 .
- ^ Grimes, Seth. “Big Data : évitez la confusion ‘Wanna V'” . Semaine de l’information . Récupéré le 5 janvier 2016 .
- ^ Renard, Charles (25 mars 2018). Science des données pour les transports . Springer Textbooks in Earth Sciences, Geography and Environment. Springer. ISBN 9783319729527.
- ^ Kitchin, Rob; McArdle, Gavin (2016). “Qu’est-ce qui fait du Big Data, du Big Data ? Exploration des caractéristiques ontologiques de 26 ensembles de données”. Big Data & Société . 3 : 1–10. doi : 10.1177/2053951716631130 . S2CID 55539845 .
- ^ Balazka, Dominik; Rodighiero, Dario (2020). « Big Data et Little Big Bang : Une (R)évolution épistémologique » . Frontières du Big Data . 3 : 31. doi : 10.3389/fdata.2020.00031 . hdl : 1721.1/128865 . PMC 7931920 . PMID 33693404 .
- ^ “avec focalisation sur Big Data & Analytique” (PDF) . Bigdataparis.com . Archivé de l’original (PDF) le 25 février 2021 . Récupéré le 8 octobre 2017 .
- ^ un b Billings SA “l’Identification de Système Non linéaire : les Méthodes de NARMAX dans le Temps, la Fréquence et les Domaines Spatio-Temporels”. Wiley, 2013
- ^ “le Blog ANDSI » DSI Big Data” . Andsi.fr . Récupéré le 8 octobre 2017 .
- ↑ Les Échos (3 avril 2013). “Les Echos – Big Data car Low-Density Data ? La faible densité en information comme facteur discriminant – Archives” . Lesechos.fr . Récupéré le 8 octobre 2017 .
- ^ Sagiroglu, Seref (2013). « Mégadonnées : un bilan ». Conférence internationale 2013 sur les technologies et systèmes de collaboration (CTS) : 42–47. doi : 10.1109/CTS.2013.6567202 . ISBN 978-1-4673-6404-1. S2CID 5724608 .
- ^ Kitchin, Rob; McArdle, Gavin (17 février 2016). “Qu’est-ce qui fait du Big Data, du Big Data ? Exploration des caractéristiques ontologiques de 26 ensembles de données” . Big Data & Société . 3 (1) : 205395171663113. doi : 10.1177/2053951716631130 .
- ^ Onay, Ceylan; Öztürk, Elif (2018). “Un examen de la recherche sur la notation de crédit à l’ère du Big Data”. Journal de la réglementation financière et de la conformité . 26 (3): 382–405. doi : 10.1108/JFRC-06-2017-0054 . S2CID 158895306 .
- ^ Le quatrième V du Big Data
- ^ “Mesurer la valeur commerciale du Big Data | IBM Big Data & Analytics Hub” . www.ibmbigdatahub.com . Récupéré le 20 janvier 2021 .
- ^ Kitchin, Rob; McArdle, Gavin (5 janvier 2016). “Qu’est-ce qui fait du Big Data, du Big Data ? Exploration des caractéristiques ontologiques de 26 ensembles de données” . Big Data & Société . 3 (1) : 205395171663113. doi : 10.1177/2053951716631130 . ISSN 2053-9517 .
- ^ “Enquête : les plus grandes bases de données approchent 30 téraoctets” . Eweek.com . 8 novembre 2003 . Récupéré le 8 octobre 2017 .
- ^ “LexisNexis pour acheter Seisint pour 775 millions de dollars” . Le Washington Post . Récupéré le 15 juillet 2004 .
- ^ Le Washington Post
- ^ Bertolucci, Jeff “Hadoop : de l’expérience à la principale plate-forme de données volumineuses” , “Information Week”, 2013. Récupéré le 14 novembre 2013.
- ^ Webster, Jean. “MapReduce : traitement simplifié des données sur les grands clusters” , “Search Storage”, 2004. Consulté le 25 mars 2013.
- ^ “Offre de solutions Big Data” . MIKE2.0 . Récupéré le 8 décembre 2013 .
- ^ “Définition de données volumineuses” . MIKE2.0 . Récupéré le 9 mars 2013 .
- ^ Boja, C; Pocovnicu, A; Batagan, L. (2012). “Architecture parallèle distribuée pour le Big Data”. Informatica Economica . 16 (2): 116–127.
- ^ “Résoudre les principaux défis commerciaux avec un Big Data Lake” (PDF) . Hcltech.com . août 2014 . Récupéré le 8 octobre 2017 .
- ^ “Méthode pour tester la tolérance aux pannes des frameworks MapReduce” (PDF) . Réseaux informatiques. 2015.
- ^ un b Manyika, James; Chui, Michael ; Bughin, Jacques ; Brown, Brad ; Dobbs, Richard; Roxburgh, Charles; Byers, Angela Hung (mai 2011). “Big Data : la prochaine frontière pour l’innovation, la concurrence et la productivité” (PDF) . Institut mondial McKinsey . Récupéré le 22 mai 2021 . {{cite journal}}: Cite journal requires |journal= (help)
- ^ “Directions futures dans le calcul et la modélisation basés sur le tenseur” (PDF) . Mai 2009.
- ^ Lu, Haiping; Plataniotis, KN; En ligneVenetsanopoulos, AN (2011). “Une enquête sur l’apprentissage de sous-espace multilinéaire pour les données tensorielles” (PDF) . Reconnaissance de formes . 44 (7): 1540-1551. Bibcode : 2011PatRe..44.1540L . doi : 10.1016/j.patcog.2011.01.004 .
- ^ Pllana, Sabri; Janciak, Ivan; Brezany, Pierre; Wohrer, Alexander (2016). “Une enquête sur l’état de l’art dans l’exploration de données et les langages de requête d’intégration”. 2011 14e Conférence internationale sur les systèmes d’information en réseau . 2011 Conférence internationale sur les systèmes d’information en réseau (NBIS 2011) . Société informatique IEEE. p. 341–348. arXiv : 1603.01113 . Bib code : 2016arXiv160301113P . doi : 10.1109/NBiS.2011.58 . ISBN 978-1-4577-0789-6. S2CID 9285984 .
- ^ Wang, Yandong; Goldstone, Robin; Yu, Weikuan ; Wang, Teng (octobre 2014). “Caractérisation et optimisation de MapReduce résident en mémoire sur les systèmes HPC”. 2014 IEEE 28e Symposium international sur le traitement parallèle et distribué . IEEE. pages 799–808. doi : 10.1109/IPDPS.2014.87 . ISBN 978-1-4799-3800-1. S2CID 11157612 .
- ^ L’Heureux, A.; Grolinger, K.; Elyamany, HF ; Capretz, MAM (2017). “Apprentissage automatique avec le Big Data : défis et approches” . Accès IEEE . 5 : 7776–7797. doi : 10.1109/ACCESS.2017.2696365 . ISSN 2169-3536 .
- ^ Monash, Curt (30 avril 2009). “Les deux énormes entrepôts de données d’eBay” .
Monash, Curt (6 octobre 2010). “Suivi eBay – Greenplum out, Teradata> 10 pétaoctets, Hadoop a une certaine valeur, et plus encore” . - ^ “Ressources sur la façon dont l’analyse des données topologiques est utilisée pour analyser les mégadonnées” . Ayasdi.
- ^ Nouvelles CNET (1er avril 2011). “Les réseaux de zone de stockage ne doivent pas s’appliquer” .
- ^ Hilbert, Martin (2014). “Quel est le contenu de la capacité mondiale d’information et de communication à médiation technologique : combien de texte, d’image, d’audio et de vidéo ?” . La société de l’information . 30 (2): 127-143. doi : 10.1080/01972243.2013.873748 . S2CID 45759014 .
- ^ Rajpurohit, Anmol (11 juillet 2014). “Entretien : Amy Gershkoff, directrice de l’analyse et des informations client, eBay sur la façon de concevoir des outils de BI personnalisés en interne” . KDnuggets . Récupéré le 14 juillet 2014 . En règle générale, je trouve que les outils d’informatique décisionnelle prêts à l’emploi ne répondent pas aux besoins des clients qui souhaitent tirer des informations personnalisées de leurs données. Par conséquent, pour les moyennes et grandes organisations ayant accès à de solides talents techniques, je recommande généralement de créer des solutions internes personnalisées.
- ^ “Le gouvernement et les mégadonnées : utilisation, problèmes et potentiel” . Monde informatique . 21 mars 2012 . Récupéré le 12 septembre 2016 .
- ^ “Livre blanc: Big Data pour le développement: opportunités et défis (2012) – United Nations Global Pulse” . Unglobalpulse.org . Récupéré le 13 avril 2016 .
- ^ “WEF (Forum économique mondial), & Vital Wave Consulting. (2012). Big Data, Big Impact: Nouvelles possibilités pour le développement international” . Forum économique mondial . Récupéré le 24 août 2012 .
- ^ un bcde Hilbert , M. (2016) . Big Data pour le développement : un examen des promesses et des défis. Examen des politiques de développement, 34(1), 135–174. https://doi.org/10.1111/dpr.12142 accès libre : https://www.martinhilbert.net/big-data-for-development/
- ^ “Elena Kvochko, Quatre façons de parler de Big Data (Technologies de communication de l’information pour la série de développement)” . banquemondiale.org. 4 décembre 2012 . Récupéré le 30 mai 2012 .
- ^ “Daniele Medri : Big Data & Business : Une révolution en cours” . Vues statistiques. 21 octobre 2013. Archivé de l’original le 17 juin 2015 . Récupéré le 21 juin 2015 .
- ^ Tobias Knobloch et Julia Manske (11 janvier 2016). “Utilisation responsable des données” . D+C, Développement et Coopération .
- ^ Mann, S., & Hilbert, M. (2020). AI4D : Intelligence Artificielle pour le Développement. Journal international de la communication, 14(0), 21. https://www.martinhilbert.net/ai4d-artificial-intelligence-for-development/
- ^ Blumenstock, JE (2016). Combattre la pauvreté avec les données. Sciences, 353(6301), 753–754. https://doi.org/10.1126/science.aah5217
- ^ Blumenstock, J., Cadamuro, G., & On, R. (2015). Prédire la pauvreté et la richesse à partir des métadonnées des téléphones portables. Sciences, 350(6264), 1073–1076. https://doi.org/10.1126/science.aac4420
- ^ Jean, N., Burke, M., Xie, M., Davis, WM, Lobell, DB et Ermon, S. (2016). Combiner l’imagerie satellitaire et l’apprentissage automatique pour prédire la pauvreté. Sciences, 353(6301), 790–794. https://doi.org/10.1126/science.aaf7894
- ^ un b Hilbert, M., & Lu, K. (2020). La trace du marché du travail en ligne en Amérique latine et dans les Caraïbes (UN ECLAC LC/TS.2020/83; p. 79). Commission économique des Nations Unies pour l’Amérique latine et les Caraïbes. https://www.cepal.org/en/publications/45892-online-job-market-trace-latin-america-and-caribbean
- ^ ONU CEPALC, (Commission économique des Nations Unies pour l’Amérique latine et les Caraïbes). (2020). Suivi de l’empreinte numérique en Amérique latine et dans les Caraïbes : leçons tirées de l’utilisation des mégadonnées pour évaluer l’économie numérique (Développement productif, Affaires de genre LC/TS.2020/12 ; Documentos de Proyecto). CEPALC des Nations Unies. https://repositorio.cepal.org/handle/11362/45484
- ^ Banerjee, Amitav; Chaudhury, Suprakash (2010). “Statistiques sans larmes : Populations et échantillons” . Journal de psychiatrie industrielle . 19 (1): 60–65. doi : 10.4103/0972-6748.77642 . ISSN 0972-6748 . PMC 3105563 . PMID 21694795 .
- ^ Huser V, Cimino JJ (juillet 2016). “Défis imminents pour l’utilisation du Big Data” . Journal international de radio-oncologie, biologie, physique . 95 (3): 890–894. doi : 10.1016/j.ijrobp.2015.10.060 . PMC 4860172 . PMID 26797535 .
- ^ Sejdić, Ervin; Falk, Tiago H. (4 juillet 2018). Traitement du signal et apprentissage automatique pour le Big Data biomédical . Sejdić, Ervin, Falk, Tiago H. [Lieu de publication non identifié]. ISBN 9781351061216. OCLC 1044733829 .
- ^ Raghupathi W, Raghupathi V (décembre 2014). “L’analyse des mégadonnées dans le domaine de la santé : promesses et potentiel” . Sciences et systèmes d’information sur la santé . 2 (1): 3. doi : 10.1186/2047-2501-2-3 . PMC 4341817 . PMID 25825667 .
- ^ Viceconti M, Hunter P, Tuyau R (juillet 2015). « Big data, big knowledge : big data pour des soins de santé personnalisés » (PDF) . Journal IEEE d’informatique biomédicale et de santé . 19 (4) : 1209–15. doi : 10.1109/JBHI.2015.2406883 . PMID 26218867 . S2CID 14710821 .
- ^ O’Donoghue, John; Herbert, John (1er octobre 2012). “Gestion des données dans les environnements mHealth : capteurs de patients, appareils mobiles et bases de données”. Journal de la qualité des données et de l’information . 4 (1) : 5 :1–5 :20. doi : 10.1145/2378016.2378021 . S2CID 2318649 .
- ^ Mirkes EM, Coats TJ, Levesley J, Gorban AN (août 2016). “Gestion des données manquantes dans un grand ensemble de données sur les soins de santé : une étude de cas de résultats de traumatismes inconnus”. Informatique en Biologie et Médecine . 75 : 203–16. arXiv : 1604.00627 . Bib code : 2016arXiv160400627M . doi : 10.1016/j.compbiomed.2016.06.004 . PMID 27318570 . S2CID 5874067 .
- ^ Murdoch TB, Detsky AS (avril 2013). “L’inévitable application du big data aux soins de santé”. JAMA . 309 (13): 1351–2. doi : 10.1001/jama.2013.393 . PMID 23549579 .
- ^ Vayena E, Salathé M, Madoff LC, Brownstein JS (février 2015). « Les enjeux éthiques du big data en santé publique » . Biologie computationnelle PLOS . 11 (2) : e1003904. Bibcode : 2015PLSCB..11E3904V . doi : 10.1371/journal.pcbi.1003904 . PMC 4321985 . PMID 25664461 .
- ^ Copeland, CS (juillet-août 2017). “Découverte de la conduite des données” (PDF) . Journal de santé de la Nouvelle-Orléans : 22–27.
- ^ un b Yanase J, Triantaphyllou E (2019). “Une enquête systématique sur le diagnostic assisté par ordinateur en médecine: développements passés et présents”. Systèmes experts avec applications . 138 : 112821. doi : 10.1016/j.eswa.2019.112821 . S2CID 199019309 .
- ^ Dong X, Bahroos N, Sadhu E, Jackson T, Chukhman M, Johnson R, Boyd A, Hynes D (2013). « Tirez parti du cadre Hadoop pour les applications informatiques cliniques à grande échelle ». Sommets conjoints de l’AMIA sur les actes de la science translationnelle. Sommets conjoints AMIA sur la science translationnelle . 2013 : 53. PMID 24303235 .
- ^ Clunie D (2013). “La tomosynthèse mammaire défie l’infrastructure d’imagerie numérique” . {{cite journal}}: Cite journal requires |journal= (help)
- ^ Yanase J, Triantaphyllou E (2019). “Les sept défis clés pour l’avenir du diagnostic assisté par ordinateur en médecine”. Journal international d’informatique médicale . 129 : 413–422. doi : 10.1016/j.ijmedinf.2019.06.017 . PMID 31445285 . S2CID 198287435 .
- ^ “Diplômes en Big Data : mode ou voie rapide vers la réussite professionnelle” . Forbes . Récupéré le 21 février 2016 .
- ^ “NY obtient un nouveau camp d’entraînement pour les scientifiques des données : c’est gratuit mais plus difficile d’accès que Harvard” . Venture Beat . Récupéré le 21 février 2016 .
- ^ Wedel, Michel; Kannan, PK (2016). “Marketing Analytics pour les environnements riches en données”. Revue de Marketing . 80 (6): 97–121. doi : 10.1509/jm.15.0413 . S2CID 168410284 .
- ^ Couldry, Nick; Turow, Joseph (2014). “Publicité, Big Data et dégagement du domaine public : nouvelles approches des spécialistes du marketing en matière de subvention du contenu”. Revue internationale de communication . 8 : 1710–1726.
- ^ “Pourquoi les agences de publicité numérique sucent à l’acquisition et ont un besoin urgent d’une mise à niveau assistée par l’IA” . Ishti.org . 15 avril 2018. Archivé de l’original le 12 février 2019 . Récupéré le 15 avril 2018 .
- ^ “Mégadonnées et analytique : C4 et Genius Digital” . Ibc.org . Récupéré le 8 octobre 2017 .
- ^ Marshall Allen (17 juillet 2018). “Les assureurs-maladie aspirent des détails sur vous – et cela pourrait augmenter vos tarifs” . www.propublica.org . Récupéré le 21 juillet 2018 .
- ^ “QuiO Nommé Champion de l’Innovation du Accenture HealthTech Innovation Challenge” . Businesswire.com . 10 janvier 2017 . Récupéré le 8 octobre 2017 .
- ^ “Une plate-forme logicielle pour l’innovation technologique opérationnelle” (PDF) . Predix.com . Récupéré le 8 octobre 2017 .
- ^ Z. Jenipher Wang (mars 2017). “Transport intelligent basé sur les mégadonnées : l’histoire sous-jacente de la mobilité transformée par l’IoT” .
- ^ “Cette chose Internet des objets” .
- ^ un b Solnik, rayon. “Le temps est venu : l’analytique au service des opérations informatiques” . Journal du centre de données . Récupéré le 21 juin 2016 .
- ^ Josh Rogin (2 août 2018). “Le nettoyage ethnique revient – en Chine” . Non. Washington Post. Archivé de l’original le 31 mars 2019 . Récupéré le 4 août 2018 . Ajoutez à cela l’état de sécurité et de surveillance sans précédent au Xinjiang, qui comprend une surveillance globale basée sur des cartes d’identité, des points de contrôle, la reconnaissance faciale et la collecte d’ADN de millions d’individus. Les autorités introduisent toutes ces données dans une machine à intelligence artificielle qui évalue la loyauté des gens envers le Parti communiste afin de contrôler chaque aspect de leur vie.
- ^ “Chine : les mégadonnées alimentent la répression dans la région minoritaire : le programme de police prédictive signale les individus pour les enquêtes, les détentions” . hrw.org . Human Rights Watch. 26 février 2018 . Récupéré le 4 août 2018 .
- ^ “Discipliner et Punir : La Naissance du Système de Crédit Social de la Chine” . La Nation . 23 janvier 2019.
- ^ “Le système de surveillance du comportement de la Chine interdit à certains de voyager, d’acheter une propriété” . Nouvelles de CBS . 24 avril 2018.
- ^ “La vérité compliquée sur le système de crédit social de la Chine” . FILAIRE . 21 janvier 2019.
- ^ “Nouvelles : Monnaie Vivante” . Les entreprises indiennes font-elles suffisamment sens au Big Data ? . Menthe vivante. 23 juin 2014 . Récupéré le 22 novembre 2014 .
- ^ “La startup israélienne utilise de grandes données, un matériel minimal pour traiter le diabète” . Le Times d’Israël . Récupéré le 28 février 2018 .
- ^ Singh, Gurparkash, Duane Schulthess, Nigel Hughes, Bart Vannieuwenhuyse et Dipak Kalra (2018). “Mégadonnées du monde réel pour la recherche clinique et le développement de médicaments”. Découverte de médicaments aujourd’hui . 23 (3): 652–660. doi : 10.1016/j.drudis.2017.12.002 . PMID 29294362 . {{cite journal}}: CS1 maint: multiple names: authors list (link)
- ^ “Avancées récentes fournies par Mobile Cloud Computing et Internet des objets pour les applications Big Data: une enquête” . Journal international de gestion de réseau . 11 mars 2016 . Récupéré le 14 septembre 2016 .
- ^ Kalil, Tom (29 mars 2012). “Les mégadonnées sont un gros problème” . whitehouse.gov . Récupéré le 26 septembre 2012 – via les Archives nationales .
- ^ Bureau exécutif du président (mars 2012). “Mégadonnées dans l’ensemble du gouvernement fédéral” (PDF) . Bureau de la politique scientifique et technologique . Archivé (PDF) de l’original le 21 janvier 2017 . Récupéré le 26 septembre 2012 – via les Archives nationales .
- ^ Lampitt, Andrew (14 février 2013). “La véritable histoire de la façon dont l’analyse des mégadonnées a aidé Obama à gagner” . InfoMonde . Récupéré le 31 mai 2014 .
- ^ “Novembre 2018 | Sites de superordinateurs TOP500” .
- ^ Hoover, J. Nicholas. “Les 10 superordinateurs les plus puissants du gouvernement” . Semaine d’information . UBM . Récupéré le 26 septembre 2012 .
- ^ Bamford, James (15 mars 2012). “La NSA construit le plus grand centre d’espionnage du pays (regardez ce que vous dites)” . Câblé . Récupéré le 18 mars 2013 .
- ^ “Cérémonie d’inauguration tenue pour 1,2 milliard de dollars du centre de données de l’Utah” . Service central de sécurité de l’Agence nationale de sécurité. Archivé de l’original le 5 septembre 2013 . Récupéré le 18 mars 2013 .
- ^ Colline, Cachemire. “Les plans du centre de données ridiculement cher de la NSA dans l’Utah suggèrent qu’il contient moins d’informations que prévu” . Forbes . Récupéré le 31 octobre 2013 .
- ^ Forgeron, Gerry; Hallman, Ben (12 juin 2013). “La controverse sur l’espionnage de la NSA met en évidence l’adoption du Big Data” . Huffington Post . Récupéré le 7 mai 2018 .
- ^ Wingfield, Nick (12 mars 2013). “Prédire les trajets domicile-travail avec plus de précision pour les futurs acheteurs de maison” . Le New York Times . Récupéré le 21 juillet 2013 .
- ^ “FICO® Falcon® Fraud Manager” . Fico.com . Récupéré le 21 juillet 2013 .
- ^ Alexandru, Dan. “Professeur” (PDF) . cds.cern.ch . CERN . Récupéré le 24 mars 2015 .
- ^ “Brochure LHC, version anglaise. Une présentation du plus grand et du plus puissant accélérateur de particules au monde, le Large Hadron Collider (LHC), qui a démarré en 2008. Son rôle, ses caractéristiques, ses technologies, etc. sont expliqués pour le grand public” . CERN-Brochure-2010-006-Eng. Brochure LHC, version anglaise . CERN . Récupéré le 20 janvier 2013 .
- ^ “LHC Guide, version anglaise. Une collection de faits et de chiffres sur le Large Hadron Collider (LHC) sous forme de questions et réponses” . CERN-Brochure-2008-001-Eng. Guide LHC, version anglaise . CERN . Récupéré le 20 janvier 2013 .
- ^ Brumfiel, Geoff (19 janvier 2011). “Physique des hautes énergies : sur l’autoroute du pétaoctet” . Nature . Vol. 469. pp. 282–83. Bibcode : 2011Natur.469..282B . doi : 10.1038/469282a .
- ^ “Recherche IBM – Zurich” (PDF) . Zurich.ibm.com . Récupéré le 8 octobre 2017 .
- ^ “Le futur réseau de télescopes entraîne le développement du traitement Exabyte” . Ars Technica . 2 avril 2012 . Récupéré le 15 avril 2015 .
- ^ “L’offre de l’Australie pour le Square Kilometre Array – le point de vue d’un initié” . La Conversation . 1er février 2012 . Récupéré le 27 septembre 2016 .
- ^ “Delort P., Forum de prospective technologique ICCP de l’OCDE, 2012” (PDF) . OCDE.org . Récupéré le 8 octobre 2017 .
- ^ “NASA – NASA Goddard présente le centre de la NASA pour la simulation climatique” . NASA.gov . Récupéré le 13 avril 2016 .
- ^ Webster, Phil. « Supercalculer le climat : la mission Big Data de la NASA » . SCC Monde . Société d’informatique. Archivé de l’original le 4 janvier 2013 . Récupéré le 18 janvier 2013 .
- ^ “Ces six grandes idées de neurosciences pourraient faire le saut du laboratoire au marché” . Le Globe and Mail . 20 novembre 2014 . Récupéré le 1er octobre 2016 .
- ^ “DNAstack s’attaque à des ensembles de données ADN massifs et complexes avec Google Genomics” . Plate-forme Google Cloud . Récupéré le 1er octobre 2016 .
- ^ “23andMe – Ascendance” . 23andme.com . Récupéré le 29 décembre 2016 .
- ^ un b Potenza, Alessandra (13 juillet 2016). “23andMe souhaite que les chercheurs utilisent ses kits, dans le but d’élargir sa collection de données génétiques” . La Verge . Récupéré le 29 décembre 2016 .
- ^ “Cette startup séquencera votre ADN, afin que vous puissiez contribuer à la recherche médicale” . Compagnie rapide . 23 décembre 2016 . Récupéré le 29 décembre 2016 .
- ^ Seife, Charles. “23andMe est terrifiant, mais pas pour les raisons que pense la FDA” . Scientifique américain . Récupéré le 29 décembre 2016 .
- ^ Zaleski, Andrew (22 juin 2016). “Cette start-up biotechnologique parie que vos gènes produiront le prochain médicament miracle” . CNBC . Récupéré le 29 décembre 2016 .
- ^ Régalado, Antonio. “Comment 23andMe a transformé votre ADN en une machine de découverte de médicaments d’un milliard de dollars” . Examen de la technologie MIT . Récupéré le 29 décembre 2016 .
- ^ “Les rapports de 23andMe sautent dans les demandes de données à la suite de l’étude sur la dépression de Pfizer | FierceBiotech” . férocebiotech.com . 22 août 2016 . Récupéré le 29 décembre 2016 .
- ^ Admirez Moyo (23 octobre 2015). “Les scientifiques des données prédisent la défaite de Springbok” . itweb.co.za . Récupéré le 12 décembre 2015 .
- ^ Regina Pazvakavambwa (17 novembre 2015). “L’analyse prédictive, le big data transforme le sport” . itweb.co.za . Récupéré le 12 décembre 2015 .
- ^ Dave Ryan (13 novembre 2015). “Sports : là où le Big Data a enfin du sens” . huffingtonpost.com . Récupéré le 12 décembre 2015 .
- ^ Franck Bi. “Comment les équipes de Formule 1 utilisent le Big Data pour obtenir l’avantage intérieur” . Forbes . Récupéré le 12 décembre 2015 .
- ^ Tay, Liz. “Dans l’entrepôt de données 90PB d’eBay” . ITNews . Récupéré le 12 février 2016 .
- ^ Layton, Julia (25 janvier 2006). “Technologie Amazone” . Money.howstuffworks.com . Récupéré le 5 mars 2013 .
- ^ “Mise à l’échelle de Facebook à 500 millions d’utilisateurs et au-delà” . Facebook.com . Récupéré le 21 juillet 2013 .
- ^ Constine, Josh (27 juin 2017). “Facebook compte désormais 2 milliards d’utilisateurs mensuels… et de responsabilité” . Tech Crunch . Récupéré le 3 septembre 2018 .
- ^ “Google fait toujours au moins 1 billion de recherches par an” . Terre des moteurs de recherche . 16 janvier 2015 . Récupéré le 15 avril 2015 .
- ^ Haleem, Abid; Javaid, Mohd ; Khan, Ibrahim; Vaishya, Raju (2020). “Applications significatives du Big Data dans la pandémie de COVID-19” . Journal indien d’orthopédie . 54 (4): 526–528. doi : 10.1007/s43465-020-00129-z . PMC 7204193 . PMID 32382166 .
- ^ Manancourt, Vincent (10 mars 2020). “Le coronavirus teste la détermination de l’Europe en matière de confidentialité” . Politique . Récupéré le 30 octobre 2020 .
- ^ Choudhury, Amit Roy (27 mars 2020). “Le gouvernement au temps de Corona” . Initié du gouvernement . Récupéré le 30 octobre 2020 .
- ^ Cellan-Jones, Rory (11 février 2020). “La Chine lance une application de “détecteur de contacts étroits” contre le coronavirus” . BBC . Archivé de l’original le 28 février 2020 . Récupéré le 30 octobre 2020 .
- ^ Siwach, Gautam; Esmailpour, Amir (mars 2014). Recherche chiffrée et formation de clusters dans le Big Data (PDF) . Conférence ASEE 2014 Zone I . Université de Bridgeport , Bridgeport , Connecticut, États-Unis. Archivé de l’original (PDF) le 9 août 2014 . Récupéré le 26 juillet 2014 .
- ^ “L’administration Obama dévoile l’initiative” Big Data “: annonce 200 millions de dollars de nouveaux investissements en R&D” (PDF) . Bureau de la politique scientifique et technologique . Archivé (PDF) de l’original le 21 janvier 2017 – via les Archives nationales .
- ^ “AMPLab à l’Université de Californie, Berkeley” . Amplab.cs.berkeley.edu . Récupéré le 5 mars 2013 .
- ^ “NSF Dirige les Efforts Fédéraux dans le Big Data” . Fondation nationale des sciences (NSF). 29 mars 2012.
- ^ Chasseur de Timothée; Teodor moldave; Matei Zaharia; Justin Ma; Michel Franklin; Pieter Abbeel ; Alexandre Bayen (octobre 2011). Mise à l’échelle du Mobile Millennium System dans le Cloud .
- ^ David Patterson (5 décembre 2011). “Les informaticiens peuvent avoir ce qu’il faut pour aider à guérir le cancer” . Le New York Times .
- ^ “Le secrétaire Chu annonce un nouvel institut pour aider les scientifiques à améliorer la recherche massive d’ensembles de données sur les superordinateurs du DOE” . energy.gov.
- ^ Jeune, Shannon (30 mai 2012). “Mass. Le gouverneur, le MIT annoncent une initiative de mégadonnées” . Boston.com . Récupéré le 29 juillet 2021 .
- ^ “Big Data @ CSAIL” . Bigdata.csail.mit.edu. 22 février 2013 . Récupéré le 5 mars 2013 .
- ^ “Forum privé public de mégadonnées” . cordis.europa.eu. 1er septembre 2012 . Récupéré le 16 mars 2020 .
- ^ “L’Institut Alan Turing sera mis en place pour rechercher les mégadonnées” . Nouvelles de la BBC . 19 mars 2014 . Récupéré le 19 mars 2014 .
- ^ “Journée d’inspiration à l’Université de Waterloo, Campus de Stratford” . betakit.com/. Archivé de l’original le 26 février 2014 . Récupéré le 28 février 2014 .
- ^ un bc Reips , Ulf-Dietrich; Matsat, Uwe (2014). “Explorer des “Big Data” à l’aide de Big Data Services” . Journal international des sciences de l’Internet . 1 (1): 1–8.
- ^ Preis T, Moat HS, Stanley HE, Bishop SR (2012). “Quantifier l’avantage de regarder vers l’avant” . Rapports scientifiques . 2 : 350. Bibcode : 2012NatSR…2E.350P . doi : 10.1038/srep00350 . PMC 3320057 . PMID 22482034 .
- ^ Marques, Paul (5 avril 2012). “Recherches en ligne d’avenir liées à la réussite économique” . Nouveau scientifique . Récupéré le 9 avril 2012 .
- ^ Johnston, Casey (6 avril 2012). “Google Trends révèle des indices sur la mentalité des nations les plus riches” . Ars Technica . Récupéré le 9 avril 2012 .
- ^ Tobias Preis (24 mai 2012). « Informations supplémentaires : l’indice d’orientation future est disponible en téléchargement » (PDF) . Récupéré le 24 mai 2012 .
- ^ Philip Ball (26 avril 2013). “Compter les recherches Google prédit les mouvements du marché” . Nature . doi : 10.1038/nature.2013.12879 . S2CID 167357427 . Récupéré le 9 août 2013 .
- ^ Preis T, Moat HS, Stanley HE (2013). “Quantifier le comportement commercial sur les marchés financiers à l’aide de Google Trends” . Rapports scientifiques . 3 : 1684. Bibcode : 2013NatSR…3E1684P . doi : 10.1038/srep01684 . PMC 3635219 . PMID 23619126 .
- ^ Nick Bilton (26 avril 2013). “Les termes de recherche Google peuvent prédire le marché boursier, les découvertes d’une étude” . Le New York Times . Récupéré le 9 août 2013 .
- ^ Christopher Matthews (26 avril 2013). “Problème avec votre portefeuille d’investissement ? Google It !” . Temps . Récupéré le 9 août 2013 .
- ^ Philip Ball (26 avril 2013). “Compter les recherches Google prédit les mouvements du marché” . Nature . doi : 10.1038/nature.2013.12879 . S2CID 167357427 . Récupéré le 9 août 2013 .
- ^ Bernhard Warner (25 avril 2013). ” Les chercheurs du “Big Data” se tournent vers Google pour battre les marchés” . Bloomberg Businessweek . Récupéré le 9 août 2013 .
- ^ Hamish McRae (28 avril 2013). “Hamish McRae : Besoin d’une poignée précieuse sur le sentiment des investisseurs ? Google-le” . L’Indépendant . Londres . Récupéré le 9 août 2013 .
- ^ Richard Waters (25 avril 2013). “La recherche Google s’avère être un nouveau mot dans la prédiction du marché boursier” . Financial Times . Récupéré le 9 août 2013 .
- ^ Jason Palmer (25 avril 2013). “Les recherches Google prédisent les mouvements du marché” . BBC . Récupéré le 9 août 2013 .
- ^ E. Sejdić (mars 2014). “Adapter les outils actuels pour une utilisation avec le big data”. Nature . 507 (7492): 306.
- ^ Stanford. “MMDS. Atelier sur les algorithmes pour les ensembles de données massifs modernes” .
- ^ Deepan Palguna; Vikas Joshi ; Venkatesan Chakravarthy ; Ravi Kothari et LV Subramaniam (2015). Analyse des algorithmes d’échantillonnage pour Twitter . Conférence conjointe internationale sur l’intelligence artificielle .
- ^ Chris Kimble; Giannis Milolidakis (7 octobre 2015). “Big Data et Business Intelligence : démystifier les mythes”. Excellence commerciale et organisationnelle mondiale . 35 (1): 23–34. arXiv : 1511.03085 . doi : 10.1002/JOE.21642 . ISSN 1932-2054 . Wikidata Q56532925 .
- ^ Chris Anderson (23 juin 2008). « La fin de la théorie : le déluge de données rend la méthode scientifique obsolète » . Câblé .
- ^ Graham M. (9 mars 2012). “Le big data et la fin de la théorie ?” . Le Gardien . Londres.
- ^ Shah, Shvetank; Horne, Andrew; Capella, Jaime (avril 2012). “De bonnes données ne garantissent pas de bonnes décisions” . Revue commerciale de Harvard . Récupéré le 8 septembre 2012 .
- ^ a b Big Data nécessite Big Visions pour Big Change. , Hilbert, M. (2014). Londres : TEDx UCL, x=conférences TED organisées de manière indépendante
- ^ Alemany Oliver, Mathieu; Vayre, Jean-Sébastien (2015). “Big Data et l’avenir de la production de connaissances dans la recherche marketing: éthique, traces numériques et raisonnement abductif”. Journal d’analyse marketing . 3 (1) : 5–13. doi : 10.1057/jma.2015.1 . S2CID 111360835 .
- ^ Jonathan Rauch (1er avril 2002). “Voir dans les coins” . L’Atlantique .
- ^ Epstein, JM et Axtell, RL (1996). Sociétés artificielles en croissance : les sciences sociales de bas en haut. Un livre de Bradford.
- ^ “Delort P., Big data en Biosciences, Big Data Paris, 2012” (PDF) . Bigdataparis.com . Récupéré le 8 octobre 2017 .
- ^ “Génomique de prochaine génération: une approche intégrative” (PDF) . nature. juillet 2010 . Récupéré le 18 octobre 2016 .
- ^ “Les grandes données dans les biosciences” . Octobre 2015 . Récupéré le 18 octobre 2016 .
- ^ “Big data : commettons-nous une grosse erreur ?” . Financial Times . 28 mars 2014 . Récupéré le 20 octobre 2016 .
- ^ Ohm, Paul (23 août 2012). “Ne construisez pas une base de données de ruine” . Revue commerciale de Harvard .
- ^ Bond-Graham, Darwin (2018). “La perspective sur les mégadonnées” . Le point de vue .
- ^ Al-Rodhan, Nayef (16 septembre 2014). “Le contrat social 2.0 : les mégadonnées et la nécessité de garantir la confidentialité et les libertés civiles – Harvard International Review” . Revue internationale de Harvard . Archivé de l’original le 13 avril 2017 . Récupéré le 3 avril 2017 .
- ^ Barocas, Solon; Nissenbaum, Hélène; Voie, Julia ; Stodden, Victoria; Bender, Stefan ; Nissenbaum, Helen (juin 2014). La fin du Big Data autour de l’anonymat et du consentement . La presse de l’Universite de Cambridge. p. 44–75. doi : 10.1017/cbo9781107590205.004 . ISBN 9781107067356. S2CID 152939392 .
- ^ Lugmayr, Artur; Stockleben, Bjoern; Scheib, Christoph; Mailaparampil, Mathew ; Mesia, Noora; Ranta, Hannu ; Lab, Emmi (1er juin 2016). “Une enquête complète sur la recherche sur le Big Data et ses implications – Qu’est-ce qui est vraiment ” nouveau ” dans le Big Data ? – C’est du Big Data cognitif !” . {{cite journal}}: Cite journal requires |journal= (help)
- ^ danah boyd (29 avril 2010). “La vie privée et la publicité dans le contexte du Big Data” . Conférence WWW 2010 . Récupéré le 18 avril 2011 .
- ^ Katyal, Sonia K. (2019). « Intelligence artificielle, publicité et désinformation » . Publicité et société trimestrielle . 20 (4). doi : 10.1353/asr.2019.0026 . ISSN 2475-1790 . S2CID 213397212 .
- ^ Jones, MB; Schildhauer, député ; Reichman, JO ; Bowers, S (2006). “La nouvelle bioinformatique : intégration des données écologiques du gène à la biosphère” (PDF) . Revue annuelle d’écologie, d’évolution et de systématique . 37 (1): 519-544. doi : 10.1146/annurev.ecolsys.37.091305.110031 .
- ^ un b Boyd, D.; En ligneCrawford, K. (2012). “Questions critiques pour le Big Data”. Information, Communication & Société . 15 (5): 662–679. doi : 10.1080/1369118X.2012.678878 . manche : 10983/1320 . S2CID 51843165 .
- ^ Échec du lancement : du Big Data aux grandes décisions Archivé le 6 décembre 2016 à la Wayback Machine , Forte Wares.
- ^ “15 choses folles qui sont en corrélation les unes avec les autres” .
- ^ Structures et algorithmes aléatoires
- ^ Cristian S. Calude, Giuseppe Longo, (2016), Le déluge de fausses corrélations dans le Big Data, les fondements de la science
- ^ Anja Lambrecht et Catherine Tucker (2016) “Les 4 erreurs que la plupart des managers font avec Analytics”, Harvard Business Review , 12 juillet. https://hbr.org/2016/07/the-4-mistakes-most-managers-make -avec-analyse
- ^ un b Gregory Piatetsky (12 août 2014). “Interview : Michael Berthold, fondateur de KNIME, sur la recherche, la créativité, les mégadonnées et la confidentialité, partie 2” . KDnuggets . Récupéré le 13 août 2014 .
- ^ Pelt, maçon (26 octobre 2015). ” “Big Data” est un mot à la mode surutilisé et ce bot Twitter le prouve” . Siliconangle . Récupéré le 4 novembre 2015 .
- ^ un b Harford, Tim (28 mars 2014). « Big data : commettons-nous une grosse erreur ? . Financial Times . Récupéré le 7 avril 2014 .
- ^ Ioannidis JP (août 2005). “Pourquoi la plupart des résultats de recherche publiés sont faux” . PLO Médecine . 2 (8) : e124. doi : 10.1371/journal.pmed.0020124 . PMC 1182327 . PMID 16060722 .
- ^ Lohr, Steve; Chanteuse, Natasha (10 novembre 2016). “Comment les données nous ont échoué à déclencher une élection” . Le New York Times . ISSN 0362-4331 . Récupéré le 27 novembre 2016 .
- ^ “Comment la police basée sur les données menace la liberté humaine” . L’Économiste . 4 juin 2018. ISSN 0013-0613 . Récupéré le 27 octobre 2019 .
- ^ Brayne, Sarah (29 août 2017). « Surveillance des mégadonnées : le cas du maintien de l’ordre ». Revue sociologique américaine . 82 (5): 977-1008. doi : 10.1177/0003122417725865 . S2CID 3609838 .
Lectures complémentaires
- Peter Kinnaird; Inbal Talgam-Cohen, éd. (2012). « Big Data » . XRDS : Crossroads, le magazine ACM pour les étudiants . Vol. 19, non. 1. Association pour les machines informatiques . ISSN 1528-4980 . OCLC 779657714 .
- Jure Leskovec ; Anand Rajaraman ; Jeffrey D. Ullman (2014). Exploitation d’ensembles de données massifs . La presse de l’Universite de Cambridge. ISBN 9781107077232. OCLC 888463433 .
- Viktor Mayer-Schönberger ; Kenneth Cukier (2013). Big Data : une révolution qui transformera notre façon de vivre, de travailler et de penser . Houghton Mifflin Harcourt. ISBN 9781299903029. OCLC 828620988 .
- Presse, Gil (9 mai 2013). “Une très courte histoire du Big Data” . forbes.com . Jersey City, New Jersey . Récupéré le 17 septembre 2016 .
- Stephens-Davidowitz, Seth (2017). Tout le monde ment : mégadonnées, nouvelles données et ce qu’Internet peut nous dire sur qui nous sommes vraiment . Dey Street Books. ISBN 978-0062390851.
- “Big Data : la révolution de la gestion” . Revue commerciale de Harvard . Octobre 2012.
- O’Neil, Cathy (2017). Armes de destruction des mathématiques : comment les mégadonnées augmentent les inégalités et menacent la démocratie . Livres de Broadway. ISBN 978-0553418835.
Liens externes
-
![]()
![]() Médias liés aux mégadonnées sur Wikimedia Commons
Médias liés aux mégadonnées sur Wikimedia Commons -
![]()
![]() La définition du dictionnaire des données volumineuses au Wiktionnaire
La définition du dictionnaire des données volumineuses au Wiktionnaire