Valeurs propres et vecteurs propres
En algèbre linéaire , un vecteur propre ( / ˈ aɪ ɡ ə n ˌ v ɛ k t ər / ) ou vecteur caractéristique d’une transformation linéaire est un vecteur différent de zéro qui change au plus d’un facteur scalaire lorsque cette transformation linéaire lui est appliquée. La valeur propre correspondante , souvent désignée par λ {displaystylelambda} 
Géométriquement , un vecteur propre, correspondant à une valeur propre réelle non nulle, pointe dans une direction dans laquelle il est étiré par la transformation et la valeur propre est le facteur par lequel il est étiré. Si la valeur propre est négative, le sens est inversé. [1] En gros, dans un espace vectoriel multidimensionnel , le vecteur propre n’est pas tourné.
Définition formelle
Si T est une transformation linéaire d’un espace vectoriel V sur un corps F en lui-même et v est un vecteur non nul dans V , alors v est un vecteur propre de T si T ( v ) est un multiple scalaire de v . Ceci peut être écrit comme
T ( v ) = λ v , {displaystyle T(mathbf {v} )=lambda mathbf {v} ,} 
où λ est un scalaire dans F , appelé valeur propre , valeur caractéristique ou racine caractéristique associée à v .
Il existe une correspondance directe entre les matrices carrées n sur n et les transformations linéaires d’un espace vectoriel à n dimensions en lui-même, quelle que soit la base de l’espace vectoriel. Ainsi, dans un espace vectoriel de dimension finie, il est équivalent de définir des valeurs propres et des vecteurs propres en utilisant soit le langage des matrices , soit le langage des transformations linéaires. [2] [3]
Si V est de dimension finie, l’équation ci-dessus est équivalente à [4]
A u = λ u . {displaystyle Amathbf {u} =lambda mathbf {u} .} 
où A est la représentation matricielle de T et u est le vecteur de coordonnées de v .
Aperçu
Les valeurs propres et les vecteurs propres figurent en bonne place dans l’analyse des transformations linéaires. Le préfixe eigen- est adopté du mot allemand eigen ( apparenté au mot anglais propre ) pour “propre”, “caractéristique”, “propre”. [5] [6] Utilisés à l’origine pour étudier les axes principaux du mouvement de rotation des corps rigides , les valeurs propres et les vecteurs propres ont un large éventail d’applications, par exemple dans l’analyse de la stabilité , l’analyse des vibrations , les orbitales atomiques , la reconnaissance faciale etdiagonalisation matricielle .
En substance, un vecteur propre v d’une transformation linéaire T est un vecteur non nul qui, lorsque T lui est appliqué, ne change pas de direction. L’application de T au vecteur propre ne fait que mettre à l’échelle le vecteur propre par la valeur scalaire λ , appelée valeur propre. Cette condition peut s’écrire sous la forme de l’équation
T ( v ) = λ v , {displaystyle T(mathbf {v} )=lambda mathbf {v} ,}
appelée équation aux valeurs propres ou équation propre . En général, λ peut être n’importe quel scalaire . Par exemple, λ peut être négatif, auquel cas le vecteur propre inverse la direction dans le cadre de la mise à l’échelle, ou il peut être nul ou complexe .
 Dans cette cartographie de cisaillement, la flèche rouge change de direction, mais pas la flèche bleue. La flèche bleue est un vecteur propre de cette cartographie de cisaillement car elle ne change pas de direction, et puisque sa longueur est inchangée, sa valeur propre est 1.
Dans cette cartographie de cisaillement, la flèche rouge change de direction, mais pas la flèche bleue. La flèche bleue est un vecteur propre de cette cartographie de cisaillement car elle ne change pas de direction, et puisque sa longueur est inchangée, sa valeur propre est 1. 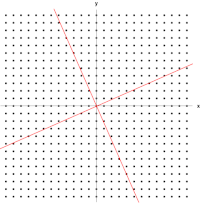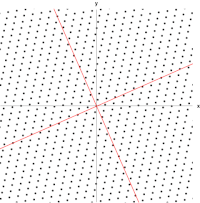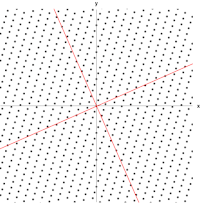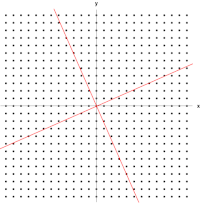 Une matrice 2×2 réelle et symétrique représentant un étirement et un cisaillement du plan. Les vecteurs propres de la matrice (lignes rouges) sont les deux directions spéciales telles que chaque point sur eux glissera simplement dessus.
Une matrice 2×2 réelle et symétrique représentant un étirement et un cisaillement du plan. Les vecteurs propres de la matrice (lignes rouges) sont les deux directions spéciales telles que chaque point sur eux glissera simplement dessus.
L’ exemple de Mona Lisa illustré ici fournit une illustration simple. Chaque point du tableau peut être représenté par un vecteur pointant du centre du tableau vers ce point. La transformation linéaire dans cet exemple est appelée une cartographie de cisaillement . Les points de la moitié supérieure sont déplacés vers la droite et les points de la moitié inférieure sont déplacés vers la gauche, proportionnellement à leur distance par rapport à l’axe horizontal qui passe par le milieu du tableau. Les vecteurs pointant vers chaque point de l’image d’origine sont donc inclinés à droite ou à gauche, et rallongés ou raccourcis par la transformation. Points le longl’axe horizontal ne bouge pas du tout lorsque cette transformation est appliquée. Par conséquent, tout vecteur qui pointe directement vers la droite ou la gauche sans composante verticale est un vecteur propre de cette transformation, car le mappage ne change pas de direction. De plus, ces vecteurs propres ont tous une valeur propre égale à un, car la cartographie ne change pas non plus leur longueur.
Les transformations linéaires peuvent prendre de nombreuses formes différentes, mappant des vecteurs dans une variété d’espaces vectoriels, de sorte que les vecteurs propres peuvent également prendre de nombreuses formes. Par exemple, la transformation linéaire pourrait être un opérateur différentiel comme d d x {displaystyle {tfrac {d}{dx}}} 
d d x e λ x = λ e λ x . {displaystyle {frac {d}{dx}}e^{lambda x}=lambda e^{lambda x}.} 
Alternativement, la transformation linéaire pourrait prendre la forme d’une matrice n par n , auquel cas les vecteurs propres sont des matrices n par 1. Si la transformation linéaire est exprimée sous la forme d’une matrice n par n A , alors l’équation aux valeurs propres pour une transformation linéaire ci-dessus peut être réécrite comme la multiplication matricielle
A v = λ v , {displaystyle Amathbf {v} =lambda mathbf {v} ,} 
où le vecteur propre v est une matrice n par 1. Pour une matrice, les valeurs propres et les vecteurs propres peuvent être utilisés pour décomposer la matrice, par exemple en la diagonalisant .
Les valeurs propres et les vecteurs propres donnent lieu à de nombreux concepts mathématiques étroitement liés, et le préfixe eigen- est appliqué généreusement pour les nommer:
- L’ensemble de tous les vecteurs propres d’une transformation linéaire, chacun associé à sa valeur propre correspondante, est appelé le système propre de cette transformation. [7] [8]
- L’ensemble de tous les vecteurs propres de T correspondant à la même valeur propre, ainsi que le Vecteur zéro, est appelé un espace propre , ou l’ espace caractéristique de T associé à cette valeur propre. [9]
- Si un ensemble de vecteurs propres de T forme une base du domaine de T , alors cette base est appelée une base propre .
Histoire
Les valeurs propres sont souvent introduites dans le contexte de l’algèbre linéaire ou de la théorie des matrices . Historiquement, cependant, ils sont apparus dans l’étude des formes quadratiques et des équations différentielles .
Au XVIIIe siècle, Leonhard Euler étudie le mouvement de rotation d’un corps rigide et découvre l’importance des axes principaux . [a] Joseph-Louis Lagrange s’est rendu compte que les axes principaux sont les vecteurs propres de la matrice d’inertie. [dix]
Au début du XIXe siècle, Augustin-Louis Cauchy a vu comment leur travail pouvait être utilisé pour classer les surfaces quadriques et l’a généralisé à des dimensions arbitraires. [11] Cauchy a également inventé le terme racine caractéristique (racine caractéristique), pour ce qu’on appelle maintenant la valeur propre ; son terme survit dans l’ équation caractéristique . [c]
Plus tard, Joseph Fourier a utilisé les travaux de Lagrange et Pierre-Simon Laplace pour résoudre l’ équation de la chaleur par séparation de variables dans son célèbre livre de 1822 Théorie analytique de la chaleur . [12] Charles-François Sturm a développé les idées de Fourier plus loin et les a portées à l’attention de Cauchy, qui les a combinées avec ses propres idées et est arrivée au fait que les vraies matrices symétriques ont de vraies valeurs propres. [11] Cela a été étendu par Charles Hermite en 1855 à ce qu’on appelle maintenant les matrices hermitiennes . [13]
À peu près à la même époque, Francesco Brioschi a prouvé que les valeurs propres des matrices orthogonales se situent sur le cercle unitaire , [11] et Alfred Clebsch a trouvé le résultat correspondant pour les matrices asymétriques . [13] Enfin, Karl Weierstrass a clarifié un aspect important de la théorie de la stabilité initiée par Laplace, en réalisant que des matrices défectueuses peuvent provoquer une instabilité. [11]
Entre-temps, Joseph Liouville a étudié des problèmes aux valeurs propres similaires à ceux de Sturm ; la discipline qui est née de leur travail s’appelle maintenant la théorie de Sturm-Liouville . [14] Schwarz a étudié la première valeur propre de l’équation de Laplace sur des domaines généraux vers la fin du XIXe siècle, tandis que Poincaré a étudié l’équation de Poisson quelques années plus tard. [15]
Au début du XXe siècle, David Hilbert a étudié les valeurs propres des opérateurs intégraux en considérant les opérateurs comme des matrices infinies. [16] Il a été le premier à utiliser le mot allemand eigen , qui signifie “propre”, [6] pour désigner les valeurs propres et les vecteurs propres en 1904, [c] bien qu’il ait pu suivre un usage connexe par Hermann von Helmholtz . Pendant un certain temps, le terme standard en anglais était “valeur propre”, mais le terme plus distinctif “valeur propre” est la norme aujourd’hui. [17]
Le premier algorithme numérique de calcul des valeurs propres et des vecteurs propres est apparu en 1929, lorsque Richard von Mises a publié la méthode de la puissance . L’une des méthodes les plus populaires aujourd’hui, l’ algorithme QR , a été proposée indépendamment par John GF Francis [18] et Vera Kublanovskaya [19] en 1961. [20] [21]
Valeurs propres et vecteurs propres des matrices
Les valeurs propres et les vecteurs propres sont souvent présentés aux étudiants dans le cadre de cours d’algèbre linéaire axés sur les matrices. [22] [23] En outre, les transformations linéaires sur un espace vectoriel de dimension finie peuvent être représentées en utilisant des matrices, [2] [3] ce qui est particulièrement courant dans les applications numériques et informatiques. [24]
 La matrice A agit en étirant le vecteur x , sans changer sa direction, donc x est un vecteur propre de A .
La matrice A agit en étirant le vecteur x , sans changer sa direction, donc x est un vecteur propre de A .
Considérez des vecteurs à n dimensions qui sont formés comme une liste de n scalaires, tels que les vecteurs à trois dimensions
x = [ 1 − 3 4 ] and y = [ − 20 60 − 80 ] . {displaystyle mathbf {x} ={begin{bmatrix}1\-3\4end{bmatrix}}quad {mbox{and}}quad mathbf {y} ={begin{ bmatrice}-20\60\-80end{bmatrice}}.} 
Ces vecteurs sont dits multiples scalaires les uns des autres, ou parallèles ou colinéaires , s’il existe un scalaire λ tel que
x = λ y . {displaystyle mathbf {x} =lambda mathbf {y} .} 
Dans ce cas λ = − 1 20 {displaystyle lambda =-{frac {1}{20}}} 
Considérons maintenant la transformation linéaire de vecteurs à n dimensions définis par une matrice n par n A ,
A v = w , {displaystyle Amathbf {v} =mathbf {w} ,} 
ou alors
[ A 11 A 12 ⋯ A 1 n A 21 A 22 ⋯ A 2 n ⋮ ⋮ ⋱ ⋮ A n 1 A n 2 ⋯ A n n ] [ v 1 v 2 ⋮ v n ] = [ w 1 w 2 ⋮ w n ] {displaystyle {begin{bmatrix}A_{11}&A_{12}&cdots &A_{1n}\A_{21}&A_{22}&cdots &A_{2n}\vdots &vdots & ddots &vdots \A_{n1}&A_{n2}&cdots &A_{nn}\end{bmatrix}}{begin{bmatrix}v_{1}\v_{2}\vdots v_{n}end{bmatrix}}={begin{bmatrix}w_{1}\w_{2}\vdots \w_{n}end{bmatrix}}} 
où, pour chaque ligne,
w i = A i 1 v 1 + A i 2 v 2 + ⋯ + A i n v n = ∑ j = 1 n A i j v j . {displaystyle w_{i}=A_{i1}v_{1}+A_{i2}v_{2}+cdots +A_{in}v_{n}=sum _{j=1}^{n} A_{ij}v_{j}.} 
S’il arrive que v et w soient des multiples scalaires, c’est-à-dire si
A v = w = λ v , {displaystyle Amathbf {v} =mathbf {w} =lambda mathbf {v} ,}  |
( 1 ) |
alors v est un vecteur propre de la transformation linéaire A et le facteur d’échelle λ est la valeur propre correspondant à ce vecteur propre. L’ équation ( 1 ) est l’ équation aux valeurs propres de la matrice A.
L’équation ( 1 ) peut être énoncée de manière équivalente comme
( A − λ I ) v = 0 , {displaystyle left(A-lambda Iright)mathbf {v} =mathbf {0} ,}  |
( 2 ) |
où I est la matrice d’identité n par n et 0 est le Vecteur zéro.
Valeurs propres et polynôme caractéristique
L’équation ( 2 ) admet une solution v non nulle si et seulement si le déterminant de la matrice ( A − λI ) est nul. Par conséquent, les valeurs propres de A sont des valeurs de λ qui satisfont l’équation
| A − λ I | = 0 {displaystyle |A-lambda I|=0}  |
( 3 ) |
En utilisant la règle de Leibniz pour le déterminant, le côté gauche de l’équation ( 3 ) est une fonction polynomiale de la variable λ et le degré de ce polynôme est n , l’ordre de la matrice A . Ses coefficients dépendent des entrées de A , sauf que son terme de degré n est toujours (−1) n λ n . Ce polynôme est appelé le polynôme caractéristique de A . L’ équation ( 3 ) est appelée équation caractéristique ouÉquation séculaire de A .
Le théorème fondamental de l’algèbre implique que le polynôme caractéristique d’une matrice n -par- n A , étant un polynôme de degré n , peut être factorisé dans le produit de n termes linéaires,
| A − λ I | = ( λ 1 − λ ) ( λ 2 − λ ) ⋯ ( λ n − λ ) , {displaystyle |A-lambda I|=(lambda _{1}-lambda )(lambda _{2}-lambda )cdots (lambda _{n}-lambda ),}  |
( 4 ) |
où chaque λ i peut être réel mais est en général un nombre complexe. Les nombres λ 1 , λ 2 , …, λ n , qui peuvent ne pas tous avoir des valeurs distinctes, sont racines du polynôme et sont les valeurs propres de A .
Comme bref exemple, qui est décrit plus en détail dans la section des exemples plus loin, considérons la matrice
A = [ 2 1 1 2 ] . {displaystyle A={begin{bmatrix}2&1\1&2end{bmatrix}}.} 
En prenant le déterminant de ( A − λI ) , le polynôme caractéristique de A est
| A − λ I | = | 2 − λ 1 1 2 − λ | = 3 − 4 λ + λ 2 . {displaystyle |A-lambda I|={begin{vmatrix}2-lambda &1\1&2-lambda end{vmatrix}}=3-4lambda +lambda ^{2}.} 
En fixant le polynôme caractéristique égal à zéro, il a pour racines λ=1 et λ=3 , qui sont les deux valeurs propres de A . Les vecteurs propres correspondant à chaque valeur propre peuvent être trouvés en résolvant les composantes de v dans l’équation ( A − λ I ) v = 0 {displaystyle left(A-lambda Iright)mathbf {v} =mathbf {0} } 
v λ = 1 = [ 1 − 1 ] , v λ = 3 = [ 1 1 ] . {displaystyle mathbf {v} _{lambda =1}={begin{bmatrix}1\-1end{bmatrix}},quad mathbf {v} _{lambda =3}={ begin{bmatrice}1\1end{bmatrice}}.} 
Si les entrées de la matrice A sont toutes des nombres réels, alors les coefficients du polynôme caractéristique seront également des nombres réels, mais les valeurs propres peuvent toujours avoir des parties imaginaires non nulles. Les entrées des vecteurs propres correspondants peuvent donc également avoir des parties imaginaires non nulles. De même, les valeurs propres peuvent être des nombres irrationnels même si toutes les entrées de A sont des nombres rationnels ou même si elles sont toutes des nombres entiers. Cependant, si les entrées de A sont toutes des nombres algébriques , qui incluent les rationnels, les valeurs propres sont des nombres algébriques complexes.
Les racines non réelles d’un polynôme réel à coefficients réels peuvent être regroupées en paires de conjugués complexes , c’est-à-dire avec les deux membres de chaque paire ayant des parties imaginaires qui ne diffèrent que par le signe et la même partie réelle. Si le degré est impair, alors par le théorème des valeurs intermédiaires au moins une des racines est réelle. Par conséquent, toute Matrice réelle d’ordre impair a au moins une valeur propre réelle, alors qu’une Matrice réelle d’ordre pair peut ne pas avoir de valeurs propres réelles. Les vecteurs propres associés à ces valeurs propres complexes sont également complexes et apparaissent également dans des paires conjuguées complexes.
Multiplicité algébrique
Soit λ i une valeur propre d’une matrice n par n A . La multiplicité algébrique μ A ( λ i ) de la valeur propre est sa multiplicité en tant que racine du polynôme caractéristique, c’est-à-dire le plus grand entier k tel que ( λ − λ i ) k divise uniformément ce polynôme. [9] [25] [26]
Supposons qu’une matrice A ait une dimension n et d ≤ n valeurs propres distinctes. Alors que l’équation ( 4 ) factorise le polynôme caractéristique de A dans le produit de n termes linéaires avec certains termes potentiellement répétitifs, le polynôme caractéristique peut plutôt être écrit comme le produit de d termes correspondant chacun à une valeur propre distincte et élevé à la puissance de la multiplicité algébrique,
| A − λ I | = ( λ 1 − λ ) μ A ( λ 1 ) ( λ 2 − λ ) μ A ( λ 2 ) ⋯ ( λ d − λ ) μ A ( λ d ) . {displaystyle |A-lambda I|=(lambda _{1}-lambda )^{mu _{A}(lambda _{1})}(lambda _{2}-lambda) ^{mu _{A}(lambda _{2})}cdots (lambda _{d}-lambda )^{mu _{A}(lambda _{d})}.} 
Si d = n alors le membre de droite est le produit de n termes linéaires et c’est la même chose que l’équation ( 4 ). La taille de la multiplicité algébrique de chaque valeur propre est liée à la dimension n comme
1 ≤ μ A ( λ i ) ≤ n , μ A = ∑ i = 1 d μ A ( λ i ) = n . {displaystyle {begin{aligned}1&leq mu _{A}(lambda _{i})leq n,\mu _{A}&=sum _{i=1}^{ d}mu _{A}left(lambda _{i}right)=n.end{aligned}}} 
Si μ A ( λ i ) = 1, on dit que λ i est une valeur propre simple . [26] Si μ A ( λ i ) est égal à la multiplicité géométrique de λ i , γ A ( λ i ), définie dans la section suivante, on dit que λ i est une valeur propre semi -simple .
Espaces propres, multiplicité géométrique et base propre des matrices
Étant donné une valeur propre particulière λ de la matrice n par n A , définissez l’ ensemble E comme étant tous les vecteurs v qui satisfont l’équation ( 2 ),
E = { v : ( A − λ I ) v = 0 } . {displaystyle E=left{mathbf {v} :left(A-lambda Iright)mathbf {v} =mathbf {0} right}.} 
D’une part, cet ensemble est précisément le noyau ou espace nul de la matrice ( A − λI ). Par contre, par définition, tout vecteur non nul qui satisfait à cette condition est un vecteur propre de A associé à λ . Ainsi, l’ensemble E est l’ union du Vecteur zéro avec l’ensemble de tous les vecteurs propres de A associés à λ , et E est égal à l’espace nul de ( A − λI ). E est appelé espace propre ou espace caractéristique de A associé àλ . [27] [9] En général λ est un nombre complexe et les vecteurs propres sont complexes n par 1 matrices. Une propriété de l’espace nul est qu’il s’agit d’un sous- espace linéaire , donc E est un sous-espace linéaire de C n .
Parce que l’espace propre E est un sous-espace linéaire, il est fermé par addition. Autrement dit, si deux vecteurs u et v appartiennent à l’ensemble E , noté u , v ∈ E , alors ( u + v ) ∈ E ou de manière équivalente A ( u + v ) = λ ( u + v ) . Ceci peut être vérifié en utilisant la propriété distributive de la multiplication matricielle. De même, parce que Eest un sous-espace linéaire, il est fermé par multiplication scalaire. Autrement dit, si v ∈ E et α est un nombre complexe, ( α v ) ∈ E ou de manière équivalente A ( α v ) = λ ( α v ) . Ceci peut être vérifié en notant que la multiplication de matrices complexes par des nombres complexes est commutative . Tant que u + v et α v ne sont pas nuls, ce sont aussi des vecteurs propres de A associés à λ .
La dimension de l’espace propre E associé à λ , ou de manière équivalente le nombre maximal de vecteurs propres linéairement indépendants associés à λ , est appelée multiplicité géométrique de la valeur propre γ A ( λ ). Comme E est aussi l’espace nul de ( A − λI ), la multiplicité géométrique de λ est la dimension de l’espace nul de ( A − λI ), aussi appelée nullité de ( A − λI ), qui se rapporte à la dimension et au rang de ( UNE –λI ) comme
γ A ( λ ) = n − rank ( A − λ I ) . {displaystyle gamma _{A}(lambda )=n-operatorname {rang} (A-lambda I).} 
En raison de la définition des valeurs propres et des vecteurs propres, la multiplicité géométrique d’une valeur propre doit être d’au moins un, c’est-à-dire que chaque valeur propre a au moins un vecteur propre associé. De plus, la multiplicité géométrique d’une valeur propre ne peut excéder sa multiplicité algébrique. De plus, rappelez-vous que la multiplicité algébrique d’une valeur propre ne peut pas dépasser n .
1 ≤ γ A ( λ ) ≤ μ A ( λ ) ≤ n {displaystyle 1leq gamma _{A}(lambda )leq mu _{A}(lambda )leq n} 
Pour prouver l’inégalité γ A ( λ ) ≤ μ A ( λ ) {displaystyle gamma _{A}(lambda )leq mu _{A}(lambda )} 
















Supposer A {displaystyle A} 



γ A = ∑ i = 1 d γ A ( λ i ) , d ≤ γ A ≤ n , {displaystyle {begin{aligned}gamma _{A}&=sum _{i=1}^{d}gamma _{A}(lambda _{i}),\d&leq gamma _{A}leq n,end{aligné}}} 
est la dimension de la somme de tous les espaces propres de A {displaystyle A} 
- La somme directe des espaces propres de tous A {displaystyle A}
les valeurs propres de sont l’ensemble de l’espace vectoriel C n {displaystyle mathbb{C} ^{n}}
.
- Une base de C n {displaystyle mathbb{C} ^{n}}
peut être formé à partir n {displaystyle n}
vecteurs propres linéairement indépendants de A {displaystyle A}
; une telle base s’appelle une base propre
- Tout vecteur dans C n {displaystyle mathbb{C} ^{n}}
peut être écrit comme une combinaison linéaire de vecteurs propres de A {displaystyle A}
.

Propriétés supplémentaires des valeurs propres
Laisser A {displaystyle A} 


- La trace de A {displaystyle A}
, défini comme la somme de ses éléments diagonaux, est aussi la somme de toutes les valeurs propres, [28] [29] [30] tr ( A ) = ∑ i = 1 n a i i = ∑ i = 1 n λ i = λ 1 + λ 2 + ⋯ + λ n . {displaystyle operatorname {tr} (A)=sum _{i=1}^{n}a_{ii}=sum _{i=1}^{n}lambda _{i}=lambda _{1}+lambda _{2}+cdots +lambda _{n}.}
- Le déterminant de A {displaystyle A}
est le produit de toutes ses valeurs propres, [28] [31] [32] det ( A ) = ∏ i = 1 n λ i = λ 1 λ 2 ⋯ λ n . {displaystyle det(A)=prod _{i=1}^{n}lambda _{i}=lambda _{1}lambda _{2}cdots lambda _{n}.}
- Les valeurs propres des k {displaystyle k}
ème puissance de A {displaystyle A}
; c’est-à-dire les valeurs propres de A k {displaystyle A^{k}}
, pour tout entier positif k {displaystyle k}
, sont λ 1 k , … , λ n k {displaystyle lambda _{1}^{k},ldots ,lambda _{n}^{k}}
.
- La matrice A {displaystyle A}
est inversible si et seulement si chaque valeur propre est non nulle.
- Si A {displaystyle A}
est inversible, alors les valeurs propres de A − 1 {displaystyle A^{-1}}
sont 1 λ 1 , … , 1 λ n {textstyle {frac {1}{lambda _{1}}},ldots ,{frac {1}{lambda _{n}}}}
et la multiplicité géométrique de chaque valeur propre coïncide. De plus, puisque le polynôme caractéristique de l’inverse est le polynôme réciproque de l’original, les valeurs propres partagent la même multiplicité algébrique.
- Si A {displaystyle A}
est égal à sa transposée conjuguée A ∗ {displaystyle A^{*}}
, ou de manière équivalente si A {displaystyle A}
est hermitienne , alors toute valeur propre est réelle. Il en va de même pour toute Matrice réelle symétrique .
- Si A {displaystyle A}
n’est pas seulement hermitienne mais aussi positive-définie , positive-semi-définie, négative-définie ou négative-semi-définie, alors chaque valeur propre est respectivement positive, non négative, négative ou non positive.
- Si A {displaystyle A}
est unitaire , chaque valeur propre a une valeur absolue | λ i | = 1 {displaystyle |lambda _{i}|=1}
.
- si A {displaystyle A}
est un n × n {displaystyle nfois n}
matrice et { λ 1 , … , λ k } {displaystyle {lambda _{1},ldots ,lambda _{k}}}
sont ses valeurs propres, alors les valeurs propres de matrice I + A {displaystyle I+A}
(où I {displaystyle I}
est la matrice identité) sont { λ 1 + 1 , … , λ k + 1 } {displaystyle {lambda _{1}+1,ldots ,lambda _{k}+1}}
. De plus, si α ∈ C {displaystyle alpha in mathbb {C} }
, les valeurs propres de α I + A {displaystyle alpha I+A}
sont { λ 1 + α , … , λ k + α } {displaystyle {lambda _{1}+alpha ,ldots ,lambda _{k}+alpha }}
. Plus généralement, pour un polynôme P {displaystyle P}
les valeurs propres de matrice P ( A ) {displaystyle P(A)}
sont { P ( λ 1 ) , … , P ( λ k ) } {displaystyle {P(lambda _{1}),ldots ,P(lambda _{k})}}
.






 , ou de manière équivalente si A {displaystyle A}
, ou de manière équivalente si A {displaystyle A} 










vecteurs propres gauche et droite
De nombreuses disciplines représentent traditionnellement les vecteurs comme des matrices à une seule colonne plutôt que comme des matrices à une seule ligne. Pour cette raison, le mot “vecteur propre” dans le contexte des matrices fait presque toujours référence à un vecteur propre droit , à savoir un vecteur colonne qui multiplie à droite le n × n {displaystyle nfois n}
A v = λ v . {displaystyle Amathbf {v} =lambda mathbf {v} .} 
Le problème des valeurs propres et des vecteurs propres peut également être défini pour les vecteurs de ligne qui ont laissé la matrice de multiplication A {displaystyle A}
u A = κ u , {displaystyle mathbf {u} A=kappa mathbf {u} ,} 
où κ {displaystylekappa} 


A T u T = κ u T . {displaystyle A^{textsf {T}}mathbf {u} ^{textsf {T}}=kappa mathbf {u} ^{textsf {T}}.} 
En comparant cette équation à l’équation ( 1 ), il s’ensuit immédiatement qu’un vecteur propre gauche de A {displaystyle A} 
Diagonalisation et décomposition propre
Supposons que les vecteurs propres de A forment une base, ou de manière équivalente A a n vecteurs propres linéairement indépendants v 1 , v 2 , …, v n avec des valeurs propres associées λ 1 , λ 2 , …, λ n . Les valeurs propres n’ont pas besoin d’être distinctes. Définissons une matrice carrée Q dont les colonnes sont les n vecteurs propres linéairement indépendants de A ,
Q = [ v 1 v 2 ⋯ v n ] . {displaystyle Q={begin{bmatrix}mathbf {v} _{1}&mathbf {v} _{2}&cdots &mathbf {v} _{n}end{bmatrix}}. } 
Puisque chaque colonne de Q est un vecteur propre de A , la multiplication à droite de A par Q met à l’échelle chaque colonne de Q par sa valeur propre associée,
A Q = [ λ 1 v 1 λ 2 v 2 ⋯ λ n v n ] . {displaystyle AQ={begin{bmatrix}lambda _{1}mathbf {v} _{1}&lambda _{2}mathbf {v} _{2}&cdots &lambda _{ n}mathbf {v} _{n}end{bmatrice}}.} 
Dans cet esprit, définissons une matrice diagonale Λ où chaque élément diagonal Λ ii est la valeur propre associée à la i ème colonne de Q . Puis
A Q = Q Λ . {displaystyle AQ=QLambda .} 
Comme les colonnes de Q sont linéairement indépendantes, Q est inversible. Multipliant à droite les deux membres de l’équation par Q −1 ,
A = Q Λ Q − 1 , {displaystyle A=QLambda Q^{-1},} 
ou en multipliant plutôt à gauche les deux côtés par Q −1 ,
Q − 1 A Q = Λ . {displaystyle Q^{-1}AQ=Lambda .} 
A peut donc être décomposé en une matrice composée de ses vecteurs propres, une matrice diagonale avec ses valeurs propres le long de la diagonale, et l’inverse de la matrice des vecteurs propres. C’est ce qu’on appelle la décomposition propre et c’est une transformation de similarité . Une telle matrice A est dite semblable à la matrice diagonale Λ ou diagonalisable . La matrice Q est la matrice de changement de base de la transformation de similarité. Essentiellement, les matrices A et Λ représentent la même transformation linéaire exprimée dans deux bases différentes. Les vecteurs propres sont utilisés comme base lors de la représentation de la transformation linéaire en tant que Λ.
Inversement, supposons qu’une matrice A soit diagonalisable. Soit P une matrice carrée non singulière telle que P −1 AP est une matrice diagonale D . En multipliant à gauche les deux par P , AP = PD . Chaque colonne de P doit donc être un vecteur propre de A dont la valeur propre est l’élément diagonal correspondant de D . Puisque les colonnes de P doivent être linéairement indépendantes pour que P soit inversible, il existe n vecteurs propres linéairement indépendants de A . Il s’ensuit que les vecteurs propres deA forme une base si et seulement si A est diagonalisable.
Une matrice non diagonalisable est dite défectueuse . Pour les matrices défectueuses, la notion de vecteurs propres se généralise aux vecteurs propres généralisés et la matrice diagonale des valeurs propres se généralise à la forme normale de Jordan . Sur un corps algébriquement clos, toute matrice A a une forme normale de Jordan et admet donc une base de vecteurs propres généralisés et une décomposition en espaces propres généralisés .
Caractérisation variationnelle
Dans le cas hermitien , les valeurs propres peuvent recevoir une caractérisation variationnelle. La plus grande valeur propre de H {displaystyle H} 


Exemples de matrice
Exemple de matrice bidimensionnelle 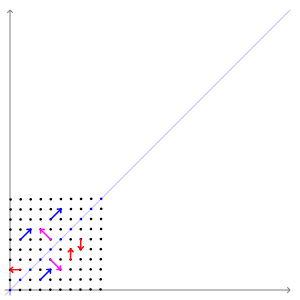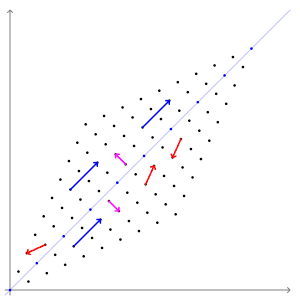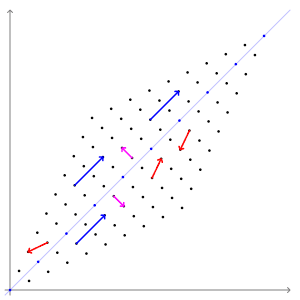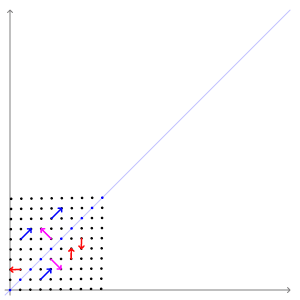 La matrice de transformation A = [ 2 1 1 2 ] {displaystyle left[{begin{smallmatrix}2&1\1&2end{smallmatrix}}right]}
La matrice de transformation A = [ 2 1 1 2 ] {displaystyle left[{begin{smallmatrix}2&1\1&2end{smallmatrix}}right]} ![{displaystyle left[{begin{smallmatrix}2&1\1&2end{smallmatrix}}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/838a30dc9d065ec434dff490bd84061ed569db3b)
Considérez la matrice
A = [ 2 1 1 2 ] . {displaystyle A={begin{bmatrix}2&1\1&2end{bmatrix}}.}
La figure de droite montre l’effet de cette transformation sur les coordonnées des points dans le plan. Les vecteurs propres v de cette transformation satisfont l’équation ( 1 ), et les valeurs de λ pour lesquelles le déterminant de la matrice ( A − λI ) vaut zéro sont les valeurs propres.
En prenant le déterminant pour trouver le polynôme caractéristique de A ,
| A − λ I | = | [ 2 1 1 2 ] − λ [ 1 0 0 1 ] | = | 2 − λ 1 1 2 − λ | = 3 − 4 λ + λ 2 = ( λ − 3 ) ( λ − 1 ) . {displaystyle {begin{aligned}|A-lambda I|&=left|{begin{bmatrix}2&1\1&2end{bmatrix}}-lambda {begin{bmatrix}1&0\0&1 end{bmatrix}}right|={begin{vmatrix}2-lambda &1\1&2-lambda end{vmatrix}}\[6pt]&=3-4lambda +lambda ^{ 2}\[6pt]&=(lambda -3)(lambda -1).end{aligné}}} ![{displaystyle {begin{aligned}|A-lambda I|&=left|{begin{bmatrix}2&1\1&2end{bmatrix}}-lambda {begin{bmatrix}1&0\0&1end{bmatrix}}right|={begin{vmatrix}2-lambda &1\1&2-lambda end{vmatrix}}\[6pt]&=3-4lambda +lambda ^{2}\[6pt]&=(lambda -3)(lambda -1).end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0084c80ab8c7637830cdf01f1c754f92a6598ac0)
En fixant le polynôme caractéristique égal à zéro, il a pour racines λ =1 et λ =3 , qui sont les deux valeurs propres de A .
Pour λ =1 , l’équation ( 2 ) devient,
( A − I ) v λ = 1 = [ 1 1 1 1 ] [ v 1 v 2 ] = [ 0 0 ] {displaystyle (AI)mathbf {v} _{lambda =1}={begin{bmatrix}1&1\1&1end{bmatrix}}{begin{bmatrix}v_{1}\v_{2 }end{bmatrix}}={begin{bmatrix}0\0end{bmatrix}}} 

Tout vecteur non nul avec v 1 = − v 2 résout cette équation. Donc,
v λ = 1 = [ v 1 − v 1 ] = [ 1 − 1 ] {displaystyle mathbf {v} _{lambda =1}={begin{bmatrix}v_{1}\-v_{1}end{bmatrix}}={begin{bmatrix}1\- 1end{bmatrice}}} 
est un vecteur propre de A correspondant à λ = 1, comme l’est tout multiple scalaire de ce vecteur.
Pour λ =3 , l’équation ( 2 ) devient
( A − 3 I ) v λ = 3 = [ − 1 1 1 − 1 ] [ v 1 v 2 ] = [ 0 0 ] − 1 v 1 + 1 v 2 = 0 ; 1 v 1 − 1 v 2 = 0 {displaystyle {begin{aligned}(A-3I)mathbf {v} _{lambda =3}&={begin{bmatrix}-1&1\1&-1end{bmatrix}}{begin {bmatrix}v_{1}\v_{2}end{bmatrix}}={begin{bmatrix}0\0end{bmatrix}}\-1v_{1}+1v_{2}&= 0;\1v_{1}-1v_{2}&=0end{aligné}}} 
Tout vecteur non nul avec v 1 = v 2 résout cette équation. Donc,
v λ = 3 = [ v 1 v 1 ] = [ 1 1 ] {displaystyle mathbf {v} _{lambda =3}={begin{bmatrix}v_{1}\v_{1}end{bmatrix}}={begin{bmatrix}1\1 fin{bmatrice}}} 
est un vecteur propre de A correspondant à λ = 3, comme l’est tout multiple scalaire de ce vecteur.
Ainsi, les vecteurs v λ =1 et v λ =3 sont des vecteurs propres de A associés respectivement aux valeurs propres λ =1 et λ =3 .
Formule générale des valeurs propres d’une matrice bidimensionnelle
Les valeurs propres de la Matrice réelle A = [ a b c d ] {displaystyle A={begin{bmatrix}a&b\c&dend{bmatrix}}} 
λ = 1 2 ( a + d ) ± ( 1 2 ( a − d ) ) 2 + b c = 1 2 ( tr ( A ) ± ( tr ( A ) ) 2 − 4 det ( A ) ) . {displaystyle lambda ={frac {1}{2}}(a+d)pm {sqrt {left({frac {1}{2}}(ad)right)^{2} +bc}}={frac {1}{2}}left(operatorname {tr} (A)pm {sqrt {left(operatorname {tr} (A)right)^{2} -4det(A)}}right).} 
Une autre représentation est : λ = 1 2 tr ( A ) ± ( 1 2 tr ( A ) ) 2 − det ( A ) . {displaystyle lambda ={frac {1}{2}}operatorname {tr} (A)pm {sqrt {left({frac {1}{2}}operatorname {tr} (A )right)^{2}-det(A)}}.} 
Notez que les valeurs propres sont toujours réelles si b et c ont le même signe, car la quantité sous le radical doit être positive.
Exemple de matrice tridimensionnelle
Considérez la matrice
A = [ 2 0 0 0 3 4 0 4 9 ] . {displaystyle A={begin{bmatrix}2&0&0\0&3&4\0&4&9end{bmatrix}}.} 
Le polynôme caractéristique de A est
| A − λ I | = | [ 2 0 0 0 3 4 0 4 9 ] − λ [ 1 0 0 0 1 0 0 0 1 ] | = | 2 − λ 0 0 0 3 − λ 4 0 4 9 − λ | , = ( 2 − λ ) [ ( 3 − λ ) ( 9 − λ ) − 16 ] = − λ 3 + 14 λ 2 − 35 λ + 22. {displaystyle {begin{aligned}|A-lambda I|&=left|{begin{bmatrix}2&0&0\0&3&4\0&4&9end{bmatrix}}-lambda {begin{bmatrix}1&0&0 \0&1&0\0&0&1end{bmatrix}}right|={begin{vmatrix}2-lambda &0&0\0&3-lambda &4\0&4&9-lambda end{vmatrix}},\[ 6pt]&=(2-lambda ){bigl [}(3-lambda )(9-lambda )-16{bigr ]}=-lambda ^{3}+14lambda ^{2} -35lambda +22.end{aligné}}} ![{displaystyle {begin{aligned}|A-lambda I|&=left|{begin{bmatrix}2&0&0\0&3&4\0&4&9end{bmatrix}}-lambda {begin{bmatrix}1&0&0\0&1&0\0&0&1end{bmatrix}}right|={begin{vmatrix}2-lambda &0&0\0&3-lambda &4\0&4&9-lambda end{vmatrix}},\[6pt]&=(2-lambda ){bigl [}(3-lambda )(9-lambda )-16{bigr ]}=-lambda ^{3}+14lambda ^{2}-35lambda +22.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/30165fb86a7e23644d2e3373a1c2c68af4756523)
Les racines du polynôme caractéristique sont 2, 1 et 11, qui sont les trois seules valeurs propres de A . Ces valeurs propres correspondent aux vecteurs propres [ 1 0 0 ] T {displaystyle {begin{bmatrix}1&0&0end{bmatrix}}^{textsf {T}}} 


Exemple de matrice tridimensionnelle avec des valeurs propres complexes
Considérons la matrice de permutation cyclique
A = [ 0 1 0 0 0 1 1 0 0 ] . {displaystyle A={begin{bmatrix}0&1&0\0&0&1\1&0&0end{bmatrix}}.} 
Cette matrice décale les coordonnées du vecteur d’une position vers le haut et déplace la première coordonnée vers le bas. Son polynôme caractéristique est 1 − λ 3 , dont les racines sont
λ 1 = 1 λ 2 = − 1 2 + i 3 2 λ 3 = λ 2 ∗ = − 1 2 − i 3 2 {displaystyle {begin{aligned}lambda _{1}&=1\lambda _{2}&=-{frac {1}{2}}+i{frac {sqrt {3} }{2}}\lambda _{3}&=lambda _{2}^{*}=-{frac {1}{2}}-i{frac {sqrt {3}}{ 2}}end{aligné}}} 
où i {displaystyle i} 

Pour la valeur propre réelle λ 1 = 1, tout vecteur avec trois entrées égales non nulles est un vecteur propre. Par example,
A [ 5 5 5 ] = [ 5 5 5 ] = 1 ⋅ [ 5 5 5 ] . {displaystyle A{begin{bmatrix}5\5\5end{bmatrix}}={begin{bmatrix}5\5\5end{bmatrix}}=1cdot {begin {bmatrice}5\5\5end{bmatrice}}.} 
Pour la paire conjuguée complexe de valeurs propres imaginaires,
λ 2 λ 3 = 1 , λ 2 2 = λ 3 , λ 3 2 = λ 2 . {displaystyle lambda _{2}lambda _{3}=1,quad lambda _{2}^{2}=lambda _{3},quad lambda _{3}^{2} =lambda _{2}.} 
Puis
A [ 1 λ 2 λ 3 ] = [ λ 2 λ 3 1 ] = λ 2 ⋅ [ 1 λ 2 λ 3 ] , {displaystyle A{begin{bmatrix}1\lambda _{2}\lambda _{3}end{bmatrix}}={begin{bmatrix}lambda _{2}\lambda _{3}\1end{bmatrix}}=lambda _{2}cdot {begin{bmatrix}1\lambda _{2}\lambda _{3}end{bmatrix} },} 
et
A [ 1 λ 3 λ 2 ] = [ λ 3 λ 2 1 ] = λ 3 ⋅ [ 1 λ 3 λ 2 ] . {displaystyle A{begin{bmatrix}1\lambda _{3}\lambda _{2}end{bmatrix}}={begin{bmatrix}lambda _{3}\lambda _{2}\1end{bmatrix}}=lambda _{3}cdot {begin{bmatrix}1\lambda _{3}\lambda _{2}end{bmatrix} }.} 
Par conséquent, les deux autres vecteurs propres de A sont complexes et sont v λ 2 = [ 1 λ 2 λ 3 ] T {displaystyle mathbf {v} _{lambda _{2}}={begin{bmatrix}1&lambda _{2}&lambda _{3}end{bmatrix}}^{textsf {T }}} 

v λ 2 = v λ 3 ∗ . {displaystyle mathbf {v} _{lambda _{2}}=mathbf {v} _{lambda _{3}}^{*}.} 
Les matrices avec des entrées uniquement le long de la diagonale principale sont appelées Matrices diagonales . Les valeurs propres d’une matrice diagonale sont les éléments diagonaux eux-mêmes. Considérez la matrice
A = [ 1 0 0 0 2 0 0 0 3 ] . {displaystyle A={begin{bmatrix}1&0&0\0&2&0\0&0&3end{bmatrix}}.} 
Le polynôme caractéristique de A est
| A − λ I | = ( 1 − λ ) ( 2 − λ ) ( 3 − λ ) , {displaystyle |A-lambda I|=(1-lambda )(2-lambda )(3-lambda ),} 
qui a pour racines λ 1 = 1 , λ 2 = 2 et λ 3 = 3 . Ces racines sont les éléments diagonaux ainsi que les valeurs propres de A .
Chaque élément diagonal correspond à un vecteur propre dont la seule composante non nulle est dans la même ligne que cet élément diagonal. Dans l’exemple, les valeurs propres correspondent aux vecteurs propres,
v λ 1 = [ 1 0 0 ] , v λ 2 = [ 0 1 0 ] , v λ 3 = [ 0 0 1 ] , {displaystyle mathbf {v} _{lambda _{1}}={begin{bmatrix}1\0\0end{bmatrix}},quad mathbf {v} _{lambda _ {2}}={begin{bmatrix}0\1\0end{bmatrix}},quad mathbf {v} _{lambda _{3}}={begin{bmatrix}0 �\1end{bmatrice}},} 
respectivement, ainsi que des multiples scalaires de ces vecteurs.
Exemple de matrice triangulaire
Une matrice dont les éléments au-dessus de la diagonale principale sont tous nuls est appelée matrice triangulaire inférieure , tandis qu’une matrice dont les éléments au-dessous de la diagonale principale sont tous nuls est appelée matrice triangulaire supérieure . Comme pour les Matrices diagonales, les valeurs propres des matrices triangulaires sont les éléments de la diagonale principale.
Considérons la matrice triangulaire inférieure,
A = [ 1 0 0 1 2 0 2 3 3 ] . {displaystyle A={begin{bmatrix}1&0&0\1&2&0\2&3&3end{bmatrix}}.} 
Le polynôme caractéristique de A est
| A − λ I | = ( 1 − λ ) ( 2 − λ ) ( 3 − λ ) , {displaystyle |A-lambda I|=(1-lambda )(2-lambda )(3-lambda ),}
qui a pour racines λ 1 = 1 , λ 2 = 2 et λ 3 = 3 . Ces racines sont les éléments diagonaux ainsi que les valeurs propres de A .
Ces valeurs propres correspondent aux vecteurs propres,
v λ 1 = [ 1 − 1 1 2 ] , v λ 2 = [ 0 1 − 3 ] , v λ 3 = [ 0 0 1 ] , {displaystyle mathbf {v} _{lambda _{1}}={begin{bmatrix}1\-1\{frac {1}{2}}end{bmatrix}},quad mathbf {v} _{lambda _{2}}={begin{bmatrix}0\1\-3end{bmatrix}},quad mathbf {v} _{lambda _{3 }}={begin{bmatrice}0\0\1end{bmatrice}},} 
respectivement, ainsi que des multiples scalaires de ces vecteurs.
Exemple de matrice avec valeurs propres répétées
Comme dans l’exemple précédent, la matrice triangulaire inférieure
A = [ 2 0 0 0 1 2 0 0 0 1 3 0 0 0 1 3 ] , {displaystyle A={begin{bmatrix}2&0&0&0\1&2&0&0\0&1&3&0\0&0&1&3end{bmatrix}},} 
a un polynôme caractéristique qui est le produit de ses éléments diagonaux,
| A − λ I | = | 2 − λ 0 0 0 1 2 − λ 0 0 0 1 3 − λ 0 0 0 1 3 − λ | = ( 2 − λ ) 2 ( 3 − λ ) 2 . {displaystyle |A-lambda I|={begin{vmatrix}2-lambda &0&0&0\1&2-lambda &0&0\0&1&3-lambda &0\0&0&1&3-lambda end{vmatrix}}=( 2-lambda )^{2}(3-lambda )^{2}.} 
Les racines de ce polynôme, et donc les valeurs propres, sont 2 et 3. La multiplicité algébrique de chaque valeur propre est 2 ; en d’autres termes, ce sont toutes deux des racines doubles. La somme des multiplicités algébriques de toutes les valeurs propres distinctes est μ A = 4 = n , l’ordre du polynôme caractéristique et la dimension de A .
D’autre part, la multiplicité géométrique de la valeur propre 2 n’est que de 1, car son espace propre est couvert par un seul vecteur [ 0 1 − 1 1 ] T {displaystyle {begin{bmatrix}0&1&-1&1end{bmatrix}}^{textsf {T}}} 

Identité vecteur propre-valeur propre
Pour une matrice hermitienne , la norme au carré de la j ème composante d’ un vecteur propre normalisé peut être calculée en utilisant uniquement les valeurs propres de la matrice et les valeurs propres de la matrice mineure correspondante ,
| v i , j | 2 = ∏ k ( λ i − λ k ( M j ) ) ∏ k ≠ i ( λ i − λ k ) , {displaystyle |v_{i,j}|^{2}={frac {prod _{k}{(lambda _{i}-lambda _{k}(M_{j}))}} {prod _{kneq i}{(lambda _{i}-lambda _{k})}}},} 

Valeurs propres et fonctions propres des opérateurs différentiels
Les définitions de valeur propre et de vecteurs propres d’une transformation linéaire T restent valables même si l’espace vectoriel sous-jacent est un espace de Hilbert ou de Banach de dimension infinie . Une classe largement utilisée de transformations linéaires agissant sur des espaces de dimension infinie sont les opérateurs différentiels sur les espaces fonctionnels . Soit D un opérateur différentiel linéaire sur l’espace C ∞ des fonctions réelles infiniment différentiables d’un argument réel t . L’équation aux valeurs propres pour D est l’ équation différentielle
D f ( t ) = λ f ( t ) {displaystyle Df(t)=lambda f(t)} 
Les fonctions qui satisfont cette équation sont des vecteurs propres de D et sont communément appelées fonctions propres .
Exemple d’opérateur dérivé
Considérez l’opérateur dérivé d d t {displaystyle {tfrac {d}{dt}}} 
d d t f ( t ) = λ f ( t ) . {displaystyle {frac {d}{dt}}f(t)=lambda f(t).} 
Cette équation différentielle peut être résolue en multipliant les deux côtés par dt / f ( t ) et en intégrant. Sa solution, la fonction exponentielle
f ( t ) = f ( 0 ) e λ t , {displaystyle f(t)=f(0)e^{lambda t},} 
est la fonction propre de l’opérateur dérivé. Dans ce cas, la fonction propre est elle-même fonction de sa valeur propre associée. En particulier, pour λ = 0 la fonction propre f ( t ) est une constante.
L’article principal sur les fonctions propres donne d’autres exemples.
Définition générale
Le concept de valeurs propres et de vecteurs propres s’étend naturellement aux transformations linéaires arbitraires sur des espaces vectoriels arbitraires. Soit V un espace vectoriel quelconque sur un corps K de scalaires , et soit T une transformation linéaire appliquant V dans V ,
T : V → V . {displaystyle T:Và V.} 
On dit qu’un vecteur non nul v ∈ V est un vecteur propre de T si et seulement s’il existe un scalaire λ ∈ K tel que
T ( v ) = λ v . {displaystyle T(mathbf {v} )=lambda mathbf {v} .}  |
( 5 ) |
Cette équation est appelée équation aux valeurs propres pour T , et le scalaire λ est la valeur propre de T correspondant au vecteur propre v . T ( v ) est le résultat de l’application de la transformation T au vecteur v , tandis que λ v est le produit du scalaire λ avec v . [36] [37]
Espaces propres, multiplicité géométrique et base propre
Étant donné une valeur propre λ , considérons l’ensemble
E = { v : T ( v ) = λ v } , {displaystyle E=left{mathbf {v} :T(mathbf {v} )=lambda mathbf {v} right},} 
qui est l’union du vecteur nul avec l’ensemble de tous les vecteurs propres associés à λ . E est appelé espace propre ou espace caractéristique de T associé à λ .
Par définition d’une transformation linéaire,
T ( x + y ) = T ( x ) + T ( y ) , T ( α x ) = α T ( x ) , {displaystyle {begin{aligned}T(mathbf {x} +mathbf {y} )&=T(mathbf {x} )+T(mathbf {y} ),\T(alpha mathbf {x} )&=alpha T(mathbf {x} ),end{aligné}}} 
pour x , y ∈ V et α ∈ K . Donc, si u et v sont des vecteurs propres de T associés à la valeur propre λ , soit u , v ∈ E , alors
T ( u + v ) = λ ( u + v ) , T ( α v ) = λ ( α v ) . {displaystyle {begin{aligned}T(mathbf {u} +mathbf {v} )&=lambda (mathbf {u} +mathbf {v} ),\T(alpha mathbf { v} )&=lambda (alpha mathbf {v} ).end{aligné}}} 
Ainsi, u + v et α v sont soit nuls, soit des vecteurs propres de T associés à λ , à savoir u + v , α v ∈ E , et E est fermé par addition et multiplication scalaire. L’espace propre E associé à λ est donc un sous-espace linéaire de V . [38] Si ce sous-espace a la dimension 1, on l’appelle parfois une ligne propre . [39]
La multiplicité géométrique γ T ( λ ) d’une valeur propre λ est la dimension de l’espace propre associé à λ , c’est-à-dire le nombre maximum de vecteurs propres linéairement indépendants associés à cette valeur propre. [9] [26] Selon la définition des valeurs propres et des vecteurs propres, γ T ( λ ) ≥ 1 car chaque valeur propre a au moins un vecteur propre.
Les espaces propres de T forment toujours une somme directe . Par conséquent, les vecteurs propres de différentes valeurs propres sont toujours linéairement indépendants. Par conséquent, la somme des dimensions des espaces propres ne peut pas dépasser la dimension n de l’espace vectoriel sur lequel T opère, et il ne peut y avoir plus de n valeurs propres distinctes. [e]
Tout sous-espace couvert par des vecteurs propres de T est un sous- espace invariant de T , et la restriction de T à un tel sous-espace est diagonalisable. De plus, si l’ensemble de l’espace vectoriel V peut être couvert par les vecteurs propres de T , ou de manière équivalente si la somme directe des espaces propres associés à toutes les valeurs propres de T est l’ensemble de l’espace vectoriel V , alors une base de V appelée base propre peut être formé de vecteurs propres linéairement indépendants de T . Lorsque T admet une base propre, T est diagonalisable.
Théorie spectrale
Si λ est une valeur propre de T , alors l’opérateur ( T − λI ) n’est pas univoque, et donc son inverse ( T − λI ) −1 n’existe pas. L’inverse est vrai pour les espaces vectoriels de dimension finie, mais pas pour les espaces vectoriels de dimension infinie. En général, l’opérateur ( T − λI ) peut ne pas avoir d’inverse même si λ n’est pas une valeur propre.
Pour cette raison, dans l’analyse fonctionnelle, les valeurs propres peuvent être généralisées au spectre d’un opérateur linéaire T comme l’ensemble de tous les scalaires λ pour lesquels l’opérateur ( T – λI ) n’a pas d’ inverse borné . Le spectre d’un opérateur contient toujours toutes ses valeurs propres mais n’est pas limité à elles.
Algèbres associatives et théorie des représentations
On peut généraliser l’objet algébrique qui agit sur l’espace vectoriel, en remplaçant un seul opérateur agissant sur un espace vectoriel par une représentation algébrique – une algèbre associative agissant sur un module . L’étude de telles actions est du domaine de la théorie des représentations .
Le concept théorique de représentation du poids est un analogue des valeurs propres, tandis que les vecteurs de poids et les espaces de poids sont les analogues des vecteurs propres et des espaces propres, respectivement.
Équations dynamiques
Les équations aux différences les plus simples ont la forme
x t = a 1 x t − 1 + a 2 x t − 2 + ⋯ + a k x t − k . {displaystyle x_{t}=a_{1}x_{t-1}+a_{2}x_{t-2}+cdots +a_{k}x_{tk}.} 
La solution de cette équation pour x en fonction de t est trouvée en utilisant son équation caractéristique
λ k − a 1 λ k − 1 − a 2 λ k − 2 − ⋯ − a k − 1 λ − a k = 0 , {displaystyle lambda ^{k}-a_{1}lambda ^{k-1}-a_{2}lambda ^{k-2}-cdots -a_{k-1}lambda -a_{ k}=0,} 
qui peuvent être trouvés en empilant dans une matrice un ensemble d’équations composé de l’Équation de différence ci-dessus et des k – 1 équations x t − 1 = x t − 1 , … , x t − k + 1 = x t − k + 1 , {displaystyle x_{t-1}=x_{t-1}, dots , x_{t-k+1}=x_{t-k+1},} 


x t = c 1 λ 1 t + ⋯ + c k λ k t . {displaystyle x_{t}=c_{1}lambda _{1}^{t}+cdots +c_{k}lambda _{k}^{t}.} 
Une procédure similaire est utilisée pour résoudre une équation différentielle de la forme
d k x d t k + a k − 1 d k − 1 x d t k − 1 + ⋯ + a 1 d x d t + a 0 x = 0. {displaystyle {frac {d^{k}x}{dt^{k}}}+a_{k-1}{frac {d^{k-1}x}{dt^{k-1} }}+cdots +a_{1}{frac {dx}{dt}}+a_{0}x=0.} 
Calcul
Le calcul des valeurs propres et des vecteurs propres est un sujet où la théorie, telle qu’elle est présentée dans les manuels élémentaires d’algèbre linéaire, est souvent très éloignée de la pratique.
Méthode classique
La méthode classique consiste à trouver d’abord les valeurs propres, puis à calculer les vecteurs propres pour chaque valeur propre. Il est à plusieurs égards mal adapté à l’arithmétique non exacte telle que la virgule flottante .
Valeurs propres
Les valeurs propres d’une matrice A {displaystyle A} 
En théorie, les coefficients du polynôme caractéristique peuvent être calculés exactement, puisqu’il s’agit de sommes de produits d’éléments de matrice ; et il existe des algorithmes qui peuvent trouver toutes les racines d’un polynôme de degré arbitraire avec n’importe quelle Précision requise . [40] Cependant, cette approche n’est pas viable en pratique car les coefficients seraient contaminés par des erreurs d’arrondi inévitables , et les racines d’un polynôme peuvent être une fonction extrêmement sensible des coefficients (comme illustré par le polynôme de Wilkinson ). [40] Même pour les matrices dont les éléments sont des entiers, le calcul devient non trivial, car les sommes sont très longues ; le terme constant est le déterminant , qui pour un n × n {displaystyle nfois n} 
Les formules algébriques explicites pour les racines d’un polynôme n’existent que si le degré n {displaystyle n} 
Vecteurs propres
Une fois que la valeur (exacte) d’une valeur propre est connue, les vecteurs propres correspondants peuvent être trouvés en trouvant des solutions non nulles de l’équation aux valeurs propres, qui devient un système d’équations linéaires à coefficients connus. Par exemple, une fois que l’on sait que 6 est une valeur propre de la matrice
A = [ 4 1 6 3 ] {displaystyle A={begin{bmatrix}4&1\6&3end{bmatrix}}} 
on peut trouver ses vecteurs propres en résolvant l’équation A v = 6 v {displaystyle Av=6v} 
[ 4 1 6 3 ] [ x y ] = 6 ⋅ [ x y ] {displaystyle {begin{bmatrix}4&1\6&3end{bmatrix}}{begin{bmatrix}x\yend{bmatrix}}=6cdot {begin{bmatrix}x\y fin{bmatrice}}} 
Cette équation matricielle est équivalente à deux équations linéaires
{ 4 x + y = 6 x 6 x + 3 y = 6 y {displaystyle left{{begin{aligned}4x+y&=6x\6x+3y&=6yend{aligned}}right.} 

Les deux équations se réduisent à la seule équation linéaire y = 2 x {displaystyle y=2x} 



La matrice A {displaystyle A} 



Méthodes itératives simples
L’approche inverse, consistant à rechercher d’abord les vecteurs propres, puis à déterminer chaque valeur propre à partir de son vecteur propre, s’avère beaucoup plus facile à gérer pour les ordinateurs. L’algorithme le plus simple ici consiste à choisir un vecteur de départ arbitraire, puis à le multiplier à plusieurs reprises avec la matrice (en normalisant éventuellement le vecteur pour conserver ses éléments de taille raisonnable); cela fait converger le vecteur vers un vecteur propre. Une variante consiste à multiplier le vecteur par ( A − μ I ) − 1 {displaystyle (A-mu I)^{-1}} 

Si v {displaystyle mathbf {v} } 
λ = v ∗ A v v ∗ v {displaystyle lambda ={frac {mathbf {v} ^{*}Amathbf {v} }{mathbf {v} ^{*}mathbf {v} }}} 
où v ∗ {displaystyle mathbf {v} ^{*}} 
Méthodes modernes
Des méthodes efficaces et précises pour calculer les valeurs propres et les vecteurs propres de matrices arbitraires n’étaient pas connues jusqu’à la conception de l’ algorithme QR en 1961. [40] La combinaison de la transformation Householder avec la décomposition LU donne un algorithme avec une meilleure convergence que l’algorithme QR. [ citation nécessaire ] Pour les grandes matrices clairsemées hermitiennes , l’ algorithme de Lanczos est un exemple d’une méthode itérative efficace pour calculer les valeurs propres et les vecteurs propres, parmi plusieurs autres possibilités. [40]
La plupart des méthodes numériques qui calculent les valeurs propres d’une matrice déterminent également un ensemble de vecteurs propres correspondants en tant que sous-produit du calcul, bien que parfois les implémenteurs choisissent de supprimer les informations de vecteur propre dès qu’elles ne sont plus nécessaires.
Applications
Valeurs propres des transformations géométriques
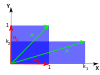
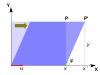
Le tableau suivant présente quelques exemples de transformations dans le plan avec leurs matrices 2 × 2, leurs valeurs propres et leurs vecteurs propres.
| Mise à l’échelle | Mise à l’échelle inégale | Rotation | Cisaillement horizontal | Rotation hyperbolique | |
|---|---|---|---|---|---|
| Illustration |  |
 |
 |
 |
 |
| Matrice | [ k 0 0 k ] {displaystyle {begin{bmatrix}k&0\0&kend{bmatrix}}}  |
[ k 1 0 0 k 2 ] {displaystyle {begin{bmatrix}k_{1}&0\0&k_{2}end{bmatrix}}}  |
[ cos θ − sin θ sin θ cos θ ] {displaystyle {begin{bmatrix}cos theta &-sin theta \sin theta &cos theta end{bmatrix}}}  |
[ 1 k 0 1 ] {displaystyle {begin{bmatrix}1&k\0&1end{bmatrix}}}  |
[ cosh φ sinh φ sinh φ cosh φ ] {displaystyle {begin{bmatrix}cosh varphi &sinh varphi \sinh varphi &cosh varphi end{bmatrix}}}  |
| Polynôme caractéristique | ( λ − k ) 2 { style d’affichage ( lambda -k) ^ {2}}  |
( λ − k 1 ) ( λ − k 2 ) {displaystyle (lambda -k_{1})(lambda -k_{2})}  |
λ 2 − 2 cos ( θ ) λ + 1 {displaystyle lambda ^{2}-2cos(theta)lambda +1}  |
( λ − 1 ) 2 {displaystyle (lambda -1)^{2}}  |
λ 2 − 2 cosh ( φ ) λ + 1 {displaystyle lambda ^{2}-2cosh(varphi)lambda +1}  |
| Valeurs propres, λ i {displaystyle lambda _{i}} |
λ 1 = λ 2 = k {displaystyle lambda _{1}=lambda _{2}=k}  |
λ 1 = k 1 λ 2 = k 2 {displaystyle {begin{aligned}lambda _{1}&=k_{1}\lambda _{2}&=k_{2}end{aligned}}}  |
λ 1 = e i θ = cos θ + i sin θ λ 2 = e − i θ = cos θ − i sin θ {displaystyle {begin{aligned}lambda _{1}&=e^{itheta }\&=cos theta +isin theta \lambda _{2}&=e^ {-itheta }\&=cos theta -isin theta end{aligné}}}  |
λ 1 = λ 2 = 1 {displaystyle lambda _{1}=lambda _{2}=1}  |
λ 1 = e φ = cosh φ + sinh φ λ 2 = e − φ = cosh φ − sinh φ {displaystyle {begin{aligned}lambda _{1}&=e^{varphi }\&=cosh varphi +sinh varphi \lambda _{2}&=e^{- varphi }\&=cosh varphi -sinh varphi end{aligné}}}  |
| Multi algébrique . , μ i = μ ( λ i ) {displaystyle mu _{i}=mu (lambda _{i})}  |
μ 1 = 2 {displaystylemu _{1}=2}  |
μ 1 = 1 μ 2 = 1 {displaystyle {begin{aligné}mu _{1}&=1\mu _{2}&=1end{aligné}}}  |
μ 1 = 1 μ 2 = 1 {displaystyle {begin{aligné}mu _{1}&=1\mu _{2}&=1end{aligné}}} |
μ 1 = 2 {displaystylemu _{1}=2} |
μ 1 = 1 μ 2 = 1 {displaystyle {begin{aligné}mu _{1}&=1\mu _{2}&=1end{aligné}}} |
| Multi géométrique . , γ i = γ ( λ i ) {displaystyle gamma _{i}=gamma (lambda _{i})}  |
γ 1 = 2 {displaystylegamma _{1}=2}  |
γ 1 = 1 γ 2 = 1 {displaystyle {begin{aligné}gamma _{1}&=1\gamma _{2}&=1end{aligné}}}  |
γ 1 = 1 γ 2 = 1 {displaystyle {begin{aligné}gamma _{1}&=1\gamma _{2}&=1end{aligné}}} |
γ 1 = 1 {displaystylegamma _{1}=1}  |
γ 1 = 1 γ 2 = 1 {displaystyle {begin{aligné}gamma _{1}&=1\gamma _{2}&=1end{aligné}}} |
| Vecteurs propres | Tous les vecteurs non nuls | u 1 = [ 1 0 ] u 2 = [ 0 1 ] {displaystyle {begin{aligned}mathbf {u} _{1}&={begin{bmatrix}1\0end{bmatrix}}\mathbf {u} _{2}&={ begin{bmatrix}0\1end{bmatrix}}end{aligné}}}  |
u 1 = [ 1 − i ] u 2 = [ 1 + i ] {displaystyle {begin{aligned}mathbf {u} _{1}&={begin{bmatrix}1\-iend{bmatrix}}\mathbf {u} _{2}&= {begin{bmatrix}1\+iend{bmatrix}}end{aligned}}}  |
u 1 = [ 1 0 ] {displaystyle mathbf {u} _{1}={begin{bmatrix}1\0end{bmatrix}}}  |
u 1 = [ 1 1 ] u 2 = [ 1 − 1 ] {displaystyle {begin{aligned}mathbf {u} _{1}&={begin{bmatrix}1\1end{bmatrix}}\mathbf {u} _{2}&={ begin{bmatrice}1\-1end{bmatrice}}end{aligné}}}  |
L’équation caractéristique d’une rotation est une équation quadratique à discriminant D = − 4 ( sin θ ) 2 {displaystyle D=-4(sin theta )^{2}} 

Une transformation linéaire qui transforme un carré en un rectangle de la même zone (un squeeze mapping ) a des valeurs propres réciproques.
Équation de Schrödinger
![]()
![]() Les fonctions d’ onde associées aux états liés d’un électron dans un atome d’hydrogène peuvent être considérées comme les vecteurs propres de l’ hamiltonien de l’atome d’hydrogène ainsi que de l’ opérateur de moment cinétique . Ils sont associés à des valeurs propres interprétées comme leurs énergies (croissantes vers le bas : n = 1 , 2 , 3 , … {displaystyle n=1,,2,,3,,ldots }
Les fonctions d’ onde associées aux états liés d’un électron dans un atome d’hydrogène peuvent être considérées comme les vecteurs propres de l’ hamiltonien de l’atome d’hydrogène ainsi que de l’ opérateur de moment cinétique . Ils sont associés à des valeurs propres interprétées comme leurs énergies (croissantes vers le bas : n = 1 , 2 , 3 , … {displaystyle n=1,,2,,3,,ldots } 
Un exemple d’équation aux valeurs propres où la transformation T {displaystyle T} 
H ψ E = E ψ E {displaystyle Hpsi _{E}=Epsi _{E},} 
où H {displaystyle H} 

Cependant, dans le cas où l’on ne s’intéresse qu’aux solutions des états liés de l’équation de Schrödinger, on cherche ψ E {displaystyle psi _{E}}
La notation bra–ket est souvent utilisée dans ce contexte. Un vecteur, qui représente un état du système, dans l’espace de Hilbert des fonctions carrées intégrables est représenté par | Ψ E ⟩ {displaystyle |Psi _{E}rangle } 
H | Ψ E ⟩ = E | Ψ E ⟩ {displaystyle H|Psi _{E}rangle =E|Psi _{E}rangle } 
où | Ψ E ⟩ {displaystyle |Psi _{E}rangle } 
Transport des vagues
La lumière , les ondes acoustiques et les micro – ondes sont dispersées au hasard de nombreuses fois lorsqu’elles traversent un système statique désordonné . Même si la diffusion multiple randomise à plusieurs reprises les ondes, le transport d’ondes finalement cohérent à travers le système est un processus déterministe qui peut être décrit par une matrice de transmission de champ t {displaystyle mathbf {t} } 




Orbitales moléculaires
En mécanique quantique , et en particulier en physique atomique et moléculaire , au sein de la théorie Hartree-Fock , les orbitales atomiques et moléculaires peuvent être définies par les vecteurs propres de l’ opérateur de Fock . Les valeurs propres correspondantes sont interprétées comme des potentiels d’ionisation via le théorème de Koopmans . Dans ce cas, le terme vecteur propre est utilisé dans un sens un peu plus général, puisque l’opérateur de Fock dépend explicitement des orbitales et de leurs valeurs propres. Ainsi, si l’on veut souligner cet aspect, on parle de problèmes aux valeurs propres non linéaires. Ces équations sont généralement résolues par une itérationprocédure, appelée dans ce cas méthode de champ auto-cohérente . En chimie quantique , on représente souvent l’équation de Hartree-Fock dans un ensemble de bases non orthogonales . Cette représentation particulière est un problème généralisé aux valeurs propres appelé équations de Roothaan .
Géologie et glaciologie
En géologie , en particulier dans l’étude du till glaciaire , les vecteurs propres et les valeurs propres sont utilisés comme méthode par laquelle une masse d’informations sur l’orientation et le pendage des constituants d’un tissu clastique peut être résumée dans un espace 3D par six nombres. Sur le terrain, un géologue peut collecter de telles données pour des centaines ou des milliers de clastes dans un échantillon de sol, qui ne peuvent être comparées que graphiquement, comme dans un diagramme Tri-Plot (Sneed et Folk), [44] [45] ou comme un Stéréonet sur un Wulff Net. [46]
La sortie du tenseur d’orientation est dans les trois axes orthogonaux (perpendiculaires) de l’espace. Les trois vecteurs propres sont ordonnés v 1 , v 2 , v 3 {displaystyle mathbf {v} _{1},mathbf {v} _{2},mathbf {v} _{3}} 










Analyse des composants principaux
 PCA de la distribution gaussienne multivariée centrée sur ( 1 , 3 ) {displaystyle (1,3)}
PCA de la distribution gaussienne multivariée centrée sur ( 1 , 3 ) {displaystyle (1,3)} 

La décomposition propre d’une matrice semi-définie positive symétrique (PSD) donne une base orthogonale de vecteurs propres, dont chacun a une valeur propre non négative. La décomposition orthogonale d’une matrice PSD est utilisée dans l’analyse multivariée , où les matrices de covariance d’échantillon sont PSD. Cette décomposition orthogonale est appelée analyse en composantes principales (ACP) en statistique. L’ACP étudie les relations linéaires entre les variables. L’ACP est effectuée sur la matrice de covariance ou la matrice de corrélation (dans laquelle chaque variable est mise à l’échelle pour avoir son variance de l’échantillon égale à un). Pour la matrice de covariance ou de corrélation, les vecteurs propres correspondent aux composantes principales et les valeurs propres à la variance expliquée par les composantes principales. L’analyse en composantes principales de la matrice de corrélation fournit une base orthogonale pour l’espace des données observées : dans cette base, les valeurs propres les plus grandes correspondent aux composantes principales qui sont associées à la plupart de la covariabilité entre un certain nombre de données observées.
L’ analyse en composantes principales est utilisée comme moyen de réduction de la dimensionnalité dans l’ étude de grands ensembles de données , tels que ceux rencontrés en bio – informatique . Dans la méthodologie Q , les valeurs propres de la matrice de corrélation déterminent le jugement de signification pratique du Q-méthodologiste (qui diffère de la signification statistique des tests d’ hypothèses ; cf. critères de détermination du nombre de facteurs ). Plus généralement, l’analyse en composantes principales peut être utilisée comme méthode d’ analyse factorielle dans la modélisation par équation structurelle .
Analyse vibratoire
 Forme modale d’un diapason à fréquence propre 440,09 Hz
Forme modale d’un diapason à fréquence propre 440,09 Hz
Les problèmes de valeurs propres surviennent naturellement dans l’Analyse vibratoire des structures mécaniques à plusieurs degrés de liberté . Les valeurs propres sont les fréquences propres (ou fréquences propres) de vibration, et les vecteurs propres sont les formes de ces modes vibrationnels. En particulier, les vibrations non amorties sont régies par
m x ̈ + k x = 0 {displaystyle m{ddot {x}}+kx=0} 
ou alors
m x ̈ = − k x {displaystyle m{ddot {x}}=-kx} 
c’est-à-dire que l’accélération est proportionnelle à la position (c’est-à-dire que nous nous attendons à x {style d’affichage x} 
Dans n {displaystyle n} 

k x = ω 2 m x {displaystyle kx=omega ^{2}mx} 
où ω 2 {displaystyle oméga ^{2}} 

m x ̈ + c x ̇ + k x = 0 {displaystyle m{ddot {x}}+c{dot {x}}+kx=0} 
conduit à un problème aux valeurs propres dit quadratique ,
( ω 2 m + ω c + k ) x = 0. {displaystyle left(omega ^{2}m+omega c+kright)x=0.} 
Cela peut être réduit à un problème de valeur propre généralisé par manipulation algébrique au prix de la résolution d’un système plus grand.
Les propriétés d’orthogonalité des vecteurs propres permettent de découpler les équations différentielles afin que le système puisse être représenté comme une sommation linéaire des vecteurs propres. Le problème des valeurs propres des structures complexes est souvent résolu à l’aide d’ une analyse par éléments finis , mais généralisez soigneusement la solution aux problèmes de vibration à valeur scalaire.
Visages propres
 Eigenfaces comme exemples de vecteurs propres
Eigenfaces comme exemples de vecteurs propres
En traitement d’images , les images traitées de visages peuvent être vues comme des vecteurs dont les composantes sont les luminosités de chaque pixel . [49] La dimension de cet espace vectoriel est le nombre de pixels. Les vecteurs propres de la matrice de covariance associée à un large ensemble d’images normalisées de visages sont appelés faces propres ; ceci est un exemple d’ analyse en composantes principales . Ils sont très utiles pour exprimer n’importe quelle image de visage comme une combinaison linéaire de certains d’entre eux. Dans la branche de la reconnaissance faciale de la biométrie , les faces propres fournissent un moyen d’appliquer la compression des données aux visages pour l’ identification . Des recherches liées aux systèmes de vision propres déterminant les gestes de la main ont également été menées.
Semblable à ce concept, les eigenvoices représentent la direction générale de la variabilité des prononciations humaines d’un énoncé particulier, tel qu’un mot dans une langue. Sur la base d’une combinaison linéaire de tels eigenvoices, une nouvelle prononciation vocale du mot peut être construite. Ces concepts se sont avérés utiles dans les systèmes de reconnaissance automatique de la parole pour l’adaptation au locuteur.
Tenseur du moment d’inertie
En mécanique , les vecteurs propres du tenseur des moments d’inertie définissent les axes principaux d’un corps rigide . Le tenseur du moment d’ inertie est une grandeur clé nécessaire pour déterminer la rotation d’un corps rigide autour de son centre de masse .
Tenseur de stress
En mécanique des solides , le tenseur des contraintes est symétrique et peut donc être décomposé en un tenseur diagonal avec les valeurs propres sur la diagonale et les vecteurs propres comme base. Parce qu’il est diagonal, dans cette orientation, le tenseur des contraintes n’a pas de composantes de cisaillement ; les composants qu’il a sont les composants principaux.
Graphiques
Dans la théorie des graphes spectraux , une valeur propre d’un graphe est définie comme une valeur propre de la matrice d’adjacence du graphe A {displaystyle A} 





Le vecteur propre principal est utilisé pour mesurer la centralité de ses sommets. Un exemple est l’ algorithme PageRank de Google . Le vecteur propre principal d’une matrice de contiguïté modifiée du graphe du World Wide Web donne les rangs de page comme composants. Ce vecteur correspond à la distribution stationnaire de la chaîne de Markov représentée par la matrice d’adjacence normalisée en ligne ; cependant, la matrice de contiguïté doit d’abord être modifiée pour s’assurer qu’une distribution stationnaire existe. Le deuxième plus petit vecteur propre peut être utilisé pour partitionner le graphique en clusters, via le clustering spectral . D’autres méthodes sont également disponibles pour le regroupement.
Numéro de reproduction de base
Le numéro de reproduction de base ( R 0 {displaystyle R_{0}} 

Voir également
- Théorie des antivaleurs propres
- Opérateur propre
- Plan propre
- Algorithme de valeur propre
- Introduction aux états propres
- Forme normale de la Jordanie
- Liste des logiciels d’analyse numérique
- Problème propre non linéaire
- Valeur propre normale
- Problème de valeur propre quadratique
- Valeur singulière
- Spectre d’une matrice
Remarques
- ^ Remarque :
- En 1751, Leonhard Euler prouve que tout corps possède un axe principal de rotation : Leonhard Euler (présenté : octobre 1751 ; publié : 1760) “Du mouvement d’un corps solide lorsqu’il tourne autour d’un axe mobile” (On le mouvement de tout corps solide pendant qu’il tourne autour d’un axe mobile), Histoire de l’Académie royale des sciences et des belles lettres de Berlin , pp. 176-227. Dans. 212 , Euler prouve que tout corps contient un axe principal de rotation : “Théorem. 44. De quelque figure que soit le corps, on y peut toujours assigner un tel axe, qui passe par son centre de gravité, autour permettant le corps peut tourner librement & d’un mouvement uniforme.”(Théorème. 44. Quelle que soit la forme du corps, on peut toujours lui assigner tel axe, qui passe par son centre de gravité, autour duquel il puisse tourner librement et d’un mouvement uniforme.)
- En 1755, Johann Andreas Segner a prouvé que tout corps a trois axes principaux de rotation : Johann Andreas Segner, Specimen theoriae turbinum [Essai sur la théorie des toupies (c’est-à-dire, les corps en rotation)] ( Halle (“Halae”), (Allemagne) : Gebauer, 1755). ( https://books.google.com/books?id=29 p. xxviii [29]), Segner dérive une équation du troisième degré en t , qui prouve qu’un corps a trois axes principaux de rotation. Il déclare ensuite (sur la même page) : “Non autem repugnat tres esse eiusmodi positiones plani HM, quia in aequatione cubica radices tres esse possunt, et tres tangentis t valores.”(Cependant, il n’est pas incohérent [qu’il] y ait trois positions du plan HM, car dans les équations cubiques, [il] peut y avoir trois racines et trois valeurs de la tangente t.)
- Le passage pertinent du travail de Segner a été brièvement discuté par Arthur Cayley . Voir : A. Cayley (1862) « Rapport sur les progrès de la solution de certains problèmes spéciaux de dynamique », Rapport de la trente-deuxième réunion de l’Association britannique pour l’avancement des sciences ; tenu à Cambridge en octobre 1862 , 32 : 184–252 ; voir en particulier pp. 225–226.
- ^ Kline 1972 , pp. 807–808 Augustin Cauchy (1839) “Mémoire sur l’intégration des équations linéaires” (Mémoire sur l’intégration des équations linéaires), Comptes rendus , 8 : 827–830, 845–865, 889–907 , 931–937. De p. 827 : “On sait d’ailleurs qu’en suivant la méthode de Lagrange, sur l’instantané pour la valeur générale de la variable principale une fonction dans laquelle entrent avec la variable principale les racines d’une certaine équation que j’appellerai l’ équation caractéristique , le degré de cette équation étant précisément l’ordre de l’équation différentielle qu’il s’agit d’intégrer.”(On sait d’ailleurs qu’en suivant la méthode de Lagrange, on obtient pour la valeur générale de la variable principale une fonction dans laquelle apparaissent, avec la variable principale, les racines d’une certaine équation que j’appellerai “l’équation caractéristique” , le degré de cette équation étant précisément l’ordre de l’équation différentielle qu’il faut intégrer.)
- ^ Voir :
- David Hilbert (1904) “Grundzüge einer allgemeinen Theorie der linearen Integralgleichungen. (Erste Mitteilung)” (Principes fondamentaux d’une théorie générale des équations intégrales linéaires. (Premier rapport)), Nachrichten von der Gesellschaft der Wissenschaften zu Göttingen, Mathematisch-Physikalische Klasse ( Nouvelles de la Société philosophique de Göttingen, section mathématique-physique), pp. 49–91. De p. 51 : « Insbesondere in dieser ersten Mitteilung gelange ich zu Formeln, die die Entwickelung einer willkürlichen Funktion nach gewissen ausgezeichneten Funktionen, die ich ‘Eigenfunktionen’ nenne, liefern : … »(En particulier, dans ce premier rapport, j’arrive à des formules qui fournissent le développement [en série] d’une fonction arbitraire en termes de certaines fonctions distinctives, que j’appelle des fonctions propres : … ) Plus loin sur la même page : “Dieser Erfolg ist wesentlich durch den Umstand bedingt, daß ich nicht, wie es bisher geschah, in erster Linie auf den Beweis für die Existenz der Eigenwerte ausgehe, … “ (Ce succès est principalement attribuable au fait que je n’ai pas, comme cela s’est produit jusqu’à présent, d’abord visent tous à une preuve de l’existence de valeurs propres, …)
- Pour l’origine et l’évolution des termes valeur propre, valeur caractéristique, etc., voir : Early Known Uses of Some of the Words of Mathematics (E)
- ^ Déterminer le polynôme caractéristique de A : | A − λ I | = | a − λ b c d − λ | = ( a − λ ) ( d − λ ) − b c = a d − a λ − d λ + λ 2 − b c = λ 2 − ( a + d ) λ + ( a d − b c ) {displaystyle {begin{aligned}|A-lambda I|&={begin{vmatrix}a-lambda &b\c&d-lambda end{vmatrix}}\&=(a-lambda )(d-lambda )-bc\&=ad-alambda -dlambda +lambda ^{2}-bc\&=lambda ^{2}-(a+d)lambda + (ad-bc)\end{aligné}}}
Utilisez la formule quadratique pour trouver les valeurs de λ : λ = ( a + d ) ± ( a + d ) 2 − 4 ( a d − b c ) 2 = a + d 2 ± ( a + d ) 2 − 4 ( a d − b c ) 2 {displaystyle {begin{aligned}lambda &={frac {(a+d)pm {sqrt {(a+d)^{2}-4(ad-bc)}}}{2} }\&={frac {a+d}{2}}pm {frac {sqrt {(a+d)^{2}-4(ad-bc)}}{2}}end {aligné}}}
Radicande simplifié : ( a + d ) 2 − 4 ( a d − b c ) = a 2 + 2 a d + d 2 − 4 a d + 4 b c = a 2 − 2 a d + d 2 + 4 b c = ( a − d ) 2 + 4 b c {displaystyle {begin{aligned}&(a+d)^{2}-4(ad-bc)\={}&a^{2}+2ad+d^{2}-4ad+4bc\ ={}&a^{2}-2ad+d^{2}+4bc\={}&(ad)^{2}+4bcend{aligned}}}
Amenez le dénominateur dans la racine carrée : λ = a + d 2 ± ( a − d ) 2 + 4 b c 4 = a + d 2 ± 1 4 ( a − d ) 2 + b c {displaystyle {begin{aligned}lambda &={frac {a+d}{2}}pm {sqrt {frac {(ad)^{2}+4bc}{4}}} &={frac {a+d}{2}}pm {sqrt {{frac {1}{4}}(ad)^{2}+bc}}end{aligned}}}
- ↑ Pour une preuve de ce lemme, voir Roman 2008 , Théorème 8.2 à la p. 186 ; Shilov 1977 , p. 109; Hefferon 2001 , p. 364 ; Beezer 2006 , Théorème EDELI à la p. 469 ; et Lemme pour l’indépendance linéaire des vecteurs propres
- ^ En faisant une élimination gaussienne sur des séries de puissance formelles tronquées à n {displaystyle n}
termes, il est possible de s’en tirer O ( n 4 ) {displaystyle O(n^{4})}
opérations, mais cela ne tient pas compte de l’explosion combinatoire .





Citations
- ^ Fardeau & Faires 1993 , p. 401.
- ^ un b Herstein 1964 , pp. 228, 229.
- ^ un b Nering 1970 , p. 38.
- ^ Weisstein, Eric W. “Valeur propre” . mathworld.wolfram.com . Récupéré le 19 août 2020 .
- ^ Bettridge 1965 .
- ^ un b “Eigenvector et Eigenvalue” . www.mathsisfun.com . Récupéré le 19 août 2020 .
- ^ Appuyez sur et al. 2007 , p. 536.
- ^ Wolfram.com : vecteur propre .
- ^ un bcd Nering 1970 , p. 107.
- ^ Hawkins 1975 , §2.
- ^ un bcd Hawkins 1975 , §3 .
- ^ Kline 1972 , p. 673.
- ^ un b Kline 1972 , pp. 807-808.
- ^ Kline 1972 , pp. 715–716.
- ^ Kline 1972 , pp. 706–707.
- ^ Kline 1972 , p. 1063, p..
- ^ Aldrich 2006 .
- ^ François 1961 , pp. 265-271.
- ^ Kublanovskaïa 1962 .
- ^ Golub & Van Loan 1996 , §7.3.
- ^ Meyer 2000 , §7.3.
- ^ Département de mathématiques de l’Université Cornell (2016) Cours de niveau inférieur pour étudiants de première année et étudiants de deuxième année . Consulté le 2016-03-27.
- ^ Catalogue de cours de mathématiques de l’Université du Michigan (2016) Archivé le 01/11/2015 à la Wayback Machine . Consulté le 2016-03-27.
- ^ Appuyez sur et al. 2007 , p. 38.
- ^ Fraleigh 1976 , p. 358.
- ^ un bc Golub & Van Loan 1996 , p. 316.
- ^ Anton 1987 , pp. 305, 307.
- ^ un b Beauregard & Fraleigh 1973 , p. 307.
- ^ Herstein 1964 , p. 272.
- ^ Nering 1970 , pp. 115-116.
- ^ Herstein 1964 , p. 290.
- ^ Nering 1970 , p. 116.
- ^ Wolchover 2019 .
- ^ un b Denton et autres. 2022 .
- ^ Van Mieghem 2014 .
- ^ Korn & Korn 2000 , Section 14.3.5a.
- ^ Friedberg, Insel & Spence 1989 , p. 217.
- ^ Nering 1970 , p. 107 ; Shilov 1977 , p. 109 Lemme de l’espace propre
- ^ Lipschutz & Lipson 2002 , p. 111.
- ^ un bcd Trefethen & Bau 1997 .
- ^ Vellekoop, IM; Mosk, AP (15 août 2007). “Focalisation d’une lumière cohérente à travers des supports opaques fortement diffusants” . Lettres d’optique . 32 (16): 2309–2311. Bibcode : 2007OptL…32.2309V . doi : 10.1364/OL.32.002309 . ISSN 1539-4794 . PMID 17700768 .
- ^ un b Rotter, Stefan; Gigan, Sylvain (2 mars 2017). “Champs lumineux dans les milieux complexes : la diffusion mésoscopique rencontre le contrôle des ondes” . Revues de physique moderne . 89 (1) : 015005. arXiv : 1702.05395 . Bibcode : 2017RvMP…89a5005R . doi : 10.1103/RevModPhys.89.015005 . S2CID 119330480 .
- ^ Bender, Nicolas; Yamilov, Alexeï; Yılmaz, Hasan ; Cao, Hui (14 octobre 2020). “Fluctuations et corrélations des canaux propres de transmission dans les milieux diffusants” . Lettres d’examen physique . 125 (16) : 165901. arXiv : 2004.12167 . Bibcode : 2020PhRvL.125p5901B . doi : 10.1103/physrevlett.125.165901 . ISSN 0031-9007 . PMID 33124845 . S2CID 216553547 .
- ^ Graham & Midgley 2000 , pp. 1473–1477.
- ^ Sneed & Folk 1958 , pp. 114–150.
- ^ Knox-Robinson & Gardoll 1998 , p. 243.
- ^ Busche, chrétien; Schiller, Beate. “Endogene Geologie – Ruhr-Universität Bochum” . www.ruhr-uni-bochum.de .
- ^ Benn & Evans 2004 , pp. 103–107.
- ^ Xirouhakis, Votsis & Delopoulus 2004 .
- ^ Journal of Mathematical Biology 1990 , pp. 365–382.
- ^ Heesterbeek & Diekmann 2000 .
Sources
- Aldrich, John (2006), “Valeur propre, fonction propre, vecteur propre et termes associés” , dans Miller, Jeff (éd.), Premières utilisations connues de certains mots de mathématiques
- Anton, Howard (1987), Algèbre linéaire élémentaire (5e éd.), New York : Wiley , ISBN 0-471-84819-0
- Beauregard, Raymond A.; Fraleigh, John B. (1973), Un premier cours d’algèbre linéaire: avec introduction facultative aux groupes, anneaux et champs , Boston: Houghton Mifflin Co. , ISBN 0-395-14017-X
- Beezer, Robert A. (2006), A first course in linear algebra , Livre en ligne gratuit sous licence GNU, University of Puget Sound
- Benn, D.; Evans, D. (2004), Un guide pratique pour l’étude des sédiments glaciaires , Londres : Arnold, pp. 103-107
- Betteridge, Harold T. (1965), Dictionnaire allemand de New Cassell , New York: Funk & Wagnall , LCCN 58-7924
- Fardeau, Richard L.; Faires, J. Douglas (1993), Numerical Analysis (5e éd.), Boston : Prindle, Weber et Schmidt , ISBN 0-534-93219-3
- Denton, Peter B.; Parke, Stephen J.; Tao, Térence; Zhang, Xining (janvier 2022). “Vecteurs propres à partir de valeurs propres: une enquête sur une identité de base en algèbre linéaire” (PDF) . Bulletin de l’American Mathematical Society . 59 (1): 31–58. arXiv : 1908.03795 . doi : 10.1090/taureau/1722 . S2CID 213918682 . Archivé (PDF) de l’original le 19 janvier 2022.
- Diekmann O, Heesterbeek JA, Metz JA (1990), “Sur la définition et le calcul du taux de reproduction de base R0 dans les modèles de maladies infectieuses dans des populations hétérogènes” , Journal of Mathematical Biology , 28 (4): 365–382, doi : 10.1007/BF00178324 , hdl : 1874/8051 , PMID 2117040 , S2CID 22275430
- Fraleigh, John B. (1976), A First Course In Abstract Algebra (2e éd.), Lecture: Addison-Wesley , ISBN 0-201-01984-1
- Francis, JGF (1961), “La transformation QR, I (partie 1)”, The Computer Journal , 4 (3): 265–271, doi : 10.1093/comjnl/4.3.265
- Francis, JGF (1962), “La transformation QR, II (partie 2)”, The Computer Journal , 4 (4): 332–345, doi : 10.1093/comjnl/4.4.332
- Friedberg, Stephen H.; Insel, Arnold J.; Spence, Lawrence E. (1989), Algèbre linéaire (2e éd.), Englewood Cliffs, NJ: Prentice Hall, ISBN 0-13-537102-3
- Golub, Gene H. ; Van Loan, Charles F. (1996), Calculs matriciels (3e éd.), Baltimore, MD: Johns Hopkins University Press, ISBN 978-0-8018-5414-9
- Graham, D.; Midgley, N. (2000), “Représentation graphique de la forme des particules à l’aide de diagrammes triangulaires : une méthode de feuille de calcul Excel”, Earth Surface Processes and Landforms , 25 (13): 1473–1477, Bibcode : 2000ESPL…25.1473G , doi : 10.1002/1096-9837(200012)25:13<1473 ::AID-ESP158>3.0.CO;2-C , S2CID 128825838
- Hawkins, T. (1975), “Cauchy et la théorie spectrale des matrices”, Historia Mathematica , 2 : 1–29, doi : 10.1016/0315-0860(75)90032-4
- Heesterbeek, JAP ; Diekmann, Odo (2000), Épidémiologie mathématique des maladies infectieuses , série Wiley en biologie mathématique et computationnelle, West Sussex, Angleterre : John Wiley & Sons
- Hefferon, Jim (2001), Linear Algebra , Colchester, VT: Livre en ligne, St Michael’s College
- Herstein, IN (1964), Sujets en algèbre , Waltham: Blaisdell Publishing Company , ISBN 978-1114541016
- Kline, Morris (1972), La pensée mathématique des temps anciens aux temps modernes , Oxford University Press, ISBN 0-19-501496-0
- Knox-Robinson, C.; Gardoll, Stephen J. (1998), “GIS-stereoplot: an interactive stereonet plotting module for ArcView 3.0 geographic information system”, Computers & Geosciences , 24 (3): 243, Bibcode : 1998CG…..24..243K , doi : 10.1016/S0098-3004(97)00122-2
- Korn, Granino A.; Korn, Theresa M. (2000), “Mathematical Handbook for Scientists and Engineers: Definitions, Theorems, and Formulas for Reference and Review”, New York: McGraw-Hill (2e édition révisée), Bibcode : 1968mhse.book… ..K , ISBN 0-486-41147-8
- Kublanovskaya, Vera N. (1962), “Sur certains algorithmes pour la solution du problème complet des valeurs propres”, USSR Computational Mathematics and Mathematical Physics , 1 (3): 637–657, doi : 10.1016 / 0041-5553 (63) 90168 -X
- Lipschutz, Seymour; Lipson, Marc (12 août 2002). Esquisse facile de l’algèbre linéaire de Schaum . Professionnel McGraw Hill. p. 111. ISBN 978-007139880-0.
- Meyer, Carl D. (2000), Analyse matricielle et algèbre linéaire appliquée , Philadelphie : Society for Industrial and Applied Mathematics (SIAM), ISBN 978-0-89871-454-8
- Nering, Evar D. (1970), Algèbre linéaire et théorie matricielle (2e éd.), New York : Wiley , LCCN 76091646
- Presse, William H. ; Teukolsky, Saül A. ; Vetterling, William T.; Flannery, Brian P. (2007), Recettes numériques: L’art du calcul scientifique (3e éd.), ISBN 978-0521880688
- Roman, Steven (2008), Algèbre linéaire avancée (3e éd.), New York: Springer Science + Business Media, ISBN 978-0-387-72828-5
- Shilov, Georgi E. (1977), Algèbre linéaire , Traduit et édité par Richard A. Silverman, New York: Dover Publications, ISBN 0-486-63518-X
- Sneed, ED ; Folk, RL (1958), “Pebbles in the lower Colorado River, Texas, a study of particule morphogenese”, Journal of Geology , 66 (2): 114–150, Bibcode : 1958JG…..66..114S , doi : 10.1086/626490 , S2CID 129658242
- Trefethen, Lloyd N.; Bau, David (1997), Algèbre linéaire numérique , SIAM
- Van Mieghem, Piet (18 janvier 2014). “Graphe des vecteurs propres, des poids fondamentaux et des métriques de centralité pour les nœuds dans les réseaux”. arXiv : 1401.4580 [ math.SP ].
- Weisstein, Eric W. “vecteur propre” . mathworld.wolfram.com . Récupéré le 4 août 2019 .
- Wolchover, Natalie (13 novembre 2019). “Les neutrinos conduisent à une découverte inattendue en mathématiques de base” . Revue Quanta . Récupéré le 27 novembre 2019 .
- Xirouhakis, A.; Votsis, G.; Delopoulus, A. (2004), Estimation du mouvement 3D et de la structure des visages humains (PDF) , Université technique nationale d’Athènes
Lectures complémentaires
- Golub, Gene F.; van der Vorst, Henk A. (2000), “Eigenvalue Computation in the 20th Century” (PDF) , Journal of Computational and Applied Mathematics , 123 (1–2): 35–65, Bibcode : 2000JCoAM.123…35G , doi : 10.1016/S0377-0427(00)00413-1 , hdl : 1874/2663
- Colline, Roger (2009). “λ – Valeurs propres” . Soixante Symboles . Brady Haran pour l’ Université de Nottingham .
- Kuttler, Kenneth (2017), Une introduction à l’algèbre linéaire (PDF) , Université Brigham Young
- Strang, Gilbert (1993), Introduction à l’algèbre linéaire , Wellesley, MA : Wellesley-Cambridge Press, ISBN 0-9614088-5-5
- Strang, Gilbert (2006), L’algèbre linéaire et ses applications , Belmont, CA : Thomson, Brooks/Cole, ISBN 0-03-010567-6
Liens externes
| Apprendre encore plus L’ utilisation de liens externes par cet article peut ne pas suivre les politiques ou les directives de Wikipedia . ( décembre 2019 ) Please improve this article by removing excessive or inappropriate external links, and converting useful links where appropriate into footnote references. (Learn how and when to remove this template message) |
| Le Wikibook Linear Algebra a une page sur le thème : Valeurs propres et vecteurs propres |
- Que sont les valeurs propres ? – introduction non technique de “Demandez aux experts” de PhysLink.com
- Valeurs propres et exemples numériques de vecteurs propres – Tutoriel et programme interactif de Revoledu.
- Introduction aux vecteurs propres et aux valeurs propres – conférence de la Khan Academy
- Vecteurs propres et valeurs propres | Essence of linear algebra, chapitre 10 – Une explication visuelle avec 3Blue1Brown
- Calculateur de vecteurs propres matriciels de Symbolab (Cliquez sur le bouton en bas à droite de la grille 2×12 pour sélectionner une taille de matrice. Sélectionnez un n × n {displaystyle nfois n}
size (pour une matrice carrée), puis remplissez les entrées numériquement et cliquez sur le bouton Go. Il peut également accepter des nombres complexes.)
La théorie
- Calcul des valeurs propres
- Solution numérique de problèmes aux valeurs propres Édité par Zhaojun Bai, James Demmel , Jack Dongarra, Axel Ruhe et Henk van der Vorst