Base de données
En informatique , une base de données est une collection organisée de données stockées et accessibles électroniquement. Les petites bases de données peuvent être stockées sur un système de fichiers , tandis que les grandes bases de données sont hébergées sur des Grappes d’ordinateurs ou un stockage en nuage . La conception des bases de données couvre les techniques formelles et les considérations pratiques, y compris la modélisation des données, la représentation et le stockage efficaces des données, les langages de requête , la sécurité et la confidentialité des données sensibles, et les problèmes informatiques distribués , y compris la prise en charge de l’accès simultané ettolérance aux pannes .
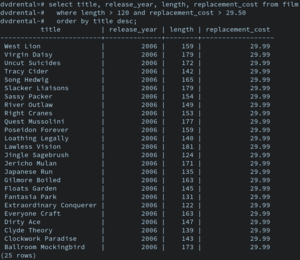 Une instruction de sélection SQL et son résultat
Une instruction de sélection SQL et son résultat
Un système de gestion de base de données ( SGBD ) est le logiciel qui interagit avec les utilisateurs finaux , les applications et la base de données elle-même pour capturer et analyser les données. Le logiciel SGBD comprend en outre les installations de base fournies pour administrer la base de données. La somme totale de la base de données, du SGBD et des applications associées peut être qualifiée de système de base de données. Souvent, le terme “base de données” est également utilisé au sens large pour désigner l’un des SGBD, le système de base de données ou une application associée à la base de données.
Les informaticiens peuvent classer les systèmes de gestion de bases de données selon les modèles de base de données qu’ils prennent en charge. Les bases de données relationnelles sont devenues dominantes dans les années 1980. Ces données de modèle sous forme de lignes et de colonnes dans une série de tables , et la grande majorité utilise SQL pour écrire et interroger les données. Dans les années 2000, les bases de données non relationnelles sont devenues populaires, collectivement appelées NoSQL car elles utilisent différents langages de requête .
Terminologie et aperçu
Formellement, une “base de données” fait référence à un ensemble de données liées et à la manière dont elles sont organisées. L’accès à ces données est généralement assuré par un “système de gestion de base de données” (SGBD) constitué d’un ensemble intégré de logiciels informatiques permettant aux utilisateurs d’interagir avec une ou plusieurs bases de données et donnant accès à l’ensemble des données contenues dans la base de données (bien que des restrictions peuvent exister qui limitent l’accès à des données particulières). Le SGBD fournit diverses fonctions qui permettent la saisie, le stockage et la récupération de grandes quantités d’informations et fournit des moyens de gérer la façon dont ces informations sont organisées.
En raison de la relation étroite qui les unit, le terme “base de données” est souvent utilisé avec désinvolture pour désigner à la fois une base de données et le SGBD utilisé pour la manipuler.
En dehors du monde des technologies de l’information professionnelles , le terme base de données est souvent utilisé pour désigner toute collection de données connexes (telles qu’une feuille de calcul ou un index sur fiches) car les exigences de taille et d’utilisation nécessitent généralement l’utilisation d’un système de gestion de base de données. [1]
Les SGBD existants proposent diverses fonctions permettant de gérer une base de données et ses données qui peuvent être classées en quatre grands groupes fonctionnels :
- Définition des données – Création, modification et suppression des définitions qui définissent l’organisation des données.
- Mise à jour – Insertion, modification et suppression des données réelles. [2]
- Récupération – Fournir des informations sous une forme directement utilisable ou pour un traitement ultérieur par d’autres applications. Les données extraites peuvent être rendues disponibles sous une forme fondamentalement identique à celle qui est stockée dans la base de données ou sous une nouvelle forme obtenue en modifiant ou en combinant des données existantes de la base de données. [3]
- Administration – Enregistrement et surveillance des utilisateurs, application de la sécurité des données, surveillance des performances, maintien de l’intégrité des données, gestion du contrôle de la concurrence et récupération des informations qui ont été corrompues par un événement tel qu’une défaillance inattendue du système. [4]
Une base de données et son SGBD sont conformes aux principes d’un modèle de base de données particulier . [5] « Système de base de données » désigne collectivement le modèle de base de données, le système de gestion de base de données et la base de données. [6]
Physiquement, les serveurs de base de données sont des ordinateurs dédiés qui contiennent les bases de données réelles et exécutent uniquement le SGBD et les logiciels associés. Les serveurs de base de données sont généralement des ordinateurs multiprocesseurs , avec une mémoire généreuse et des matrices de disques RAID utilisées pour un stockage stable. Les accélérateurs matériels de base de données, connectés à un ou plusieurs serveurs via un canal haut débit, sont également utilisés dans les environnements de traitement de transactions à grand volume. Les SGBD se trouvent au cœur de la plupart des applications de bases de données . Les SGBD peuvent être construits autour d’un noyau multitâche personnalisé avec une prise en charge réseau intégrée , mais les SGBD modernes s’appuient généralement sur un système d’ exploitation standard pour fournir ces fonctions.[ citation nécessaire ]
Étant donné que les SGBD constituent un marché important , les fournisseurs d’ordinateurs et de stockage tiennent souvent compte des exigences des SGBD dans leurs propres plans de développement. [7]
Les bases de données et les SGBD peuvent être classés en fonction du ou des modèles de base de données qu’ils prennent en charge (tels que relationnel ou XML), du ou des types d’ordinateurs sur lesquels ils s’exécutent (d’un cluster de serveurs à un téléphone mobile), du langage de requête ( s) utilisés pour accéder à la base de données (comme SQL ou XQuery ) et leur ingénierie interne, qui affecte les performances, l’ évolutivité , la résilience et la sécurité.
Histoire
La taille, les capacités et les performances des bases de données et de leurs SGBD respectifs ont augmenté de plusieurs ordres de grandeur. Ces augmentations de performances ont été rendues possibles par les progrès technologiques dans les domaines des processeurs , de la mémoire informatique , du stockage informatique et des réseaux informatiques . Le concept de base de données a été rendu possible par l’émergence de supports de stockage à accès direct tels que les disques magnétiques, qui sont devenus largement disponibles au milieu des années 1960 ; les systèmes antérieurs reposaient sur le stockage séquentiel des données sur bande magnétique. Le développement ultérieur de la technologie des bases de données peut être divisé en trois époques basées sur le modèle ou la structure des données : navigation , [8] SQL/ relationnel, et post-relationnel.
Les deux principaux premiers modèles de données de navigation étaient le modèle hiérarchique et le modèle CODASYL (modèle de réseau ). Celles-ci étaient caractérisées par l’utilisation de pointeurs (souvent des adresses de disques physiques) pour suivre les relations d’un enregistrement à l’autre.
Le modèle relationnel , proposé pour la première fois en 1970 par Edgar F. Codd , s’est écarté de cette tradition en insistant sur le fait que les applications doivent rechercher des données par contenu plutôt qu’en suivant des liens. Le modèle relationnel utilise des ensembles de tables de style grand livre, chacune utilisée pour un type d’entité différent. Ce n’est qu’au milieu des années 1980 que le matériel informatique est devenu suffisamment puissant pour permettre le déploiement à grande échelle de systèmes relationnels (SGBD plus applications). Au début des années 1990, cependant, les systèmes relationnels dominaient dans toutes les applications de traitement de données à grande échelle , et à partir de 2018, [mettre à jour]ils restent dominants : IBM Db2 , Oracle , MySQL et Microsoft SQL Server sont les plus recherchés .SGBD . [9] Le langage de base de données dominant, SQL standardisé pour le modèle relationnel, a influencé les langages de base de données pour d’autres modèles de données. [ citation nécessaire ]
Les bases de données d’objets ont été développées dans les années 1980 pour surmonter les inconvénients de la non-concordance d’impédance objet-relationnelle , ce qui a conduit à la création du terme «post-relationnel» et également au développement de bases de données hybrides objet-relationnel .
La prochaine génération de bases de données post-relationnelles à la fin des années 2000 est devenue connue sous le nom de bases de données NoSQL , introduisant des magasins clé-valeur rapides et des bases de données orientées document . Une “nouvelle génération” concurrente connue sous le nom de bases de données NewSQL a tenté de nouvelles implémentations qui conservaient le modèle relationnel/SQL tout en visant à égaler les hautes performances de NoSQL par rapport aux SGBD relationnels disponibles dans le commerce.
1960, SGBD de navigation
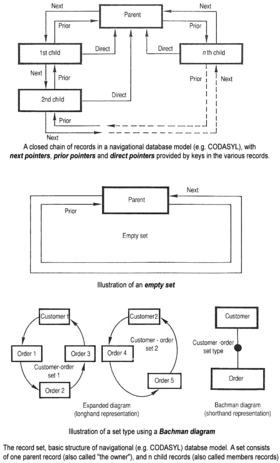 Structure de base du modèle de base de données de navigation CODASYL
Structure de base du modèle de base de données de navigation CODASYL
L’introduction du terme base de données a coïncidé avec la disponibilité du stockage à accès direct (disques et tambours) à partir du milieu des années 1960. Le terme représentait un contraste avec les systèmes à bande du passé, permettant une utilisation interactive partagée plutôt qu’un traitement par lots quotidien . L’ Oxford English Dictionary cite un rapport de 1962 de la System Development Corporation of California comme le premier à utiliser le terme «base de données» dans un sens technique spécifique. [dix]
Au fur et à mesure que les ordinateurs gagnaient en vitesse et en capacité, un certain nombre de systèmes de bases de données à usage général ont émergé; au milieu des années 1960, un certain nombre de ces systèmes étaient entrés dans le commerce. L’intérêt pour une norme a commencé à croître et Charles Bachman , auteur de l’un de ces produits, l’ Integrated Data Store (IDS), a fondé le Database Task Group au sein de CODASYL , le groupe responsable de la création et de la normalisation de COBOL . En 1971, le groupe de travail sur les bases de données a livré sa norme, généralement connue sous le nom d’ approche CODASYL , et bientôt un certain nombre de produits commerciaux basés sur cette approche sont entrés sur le marché.
L’approche CODASYL a offert aux applications la possibilité de naviguer dans un ensemble de données liées qui a été formé dans un vaste réseau. Les applications peuvent trouver des enregistrements par l’une des trois méthodes suivantes :
- Utilisation d’une clé primaire (appelée clé CALC, généralement implémentée par hachage )
- Naviguer dans les relations (appelées ensembles ) d’un enregistrement à un autre
- Numérisation de tous les enregistrements dans un ordre séquentiel
Les systèmes ultérieurs ont ajouté des arbres B pour fournir des chemins d’accès alternatifs. De nombreuses bases de données CODASYL ont également ajouté un langage de requête déclaratif pour les utilisateurs finaux (distinct de l’API de navigation). Cependant, les bases de données CODASYL étaient complexes et nécessitaient une formation et des efforts importants pour produire des applications utiles.
IBM avait également son propre SGBD en 1966, connu sous le nom de système de gestion de l’information (IMS). IMS était un développement de logiciel écrit pour le programme Apollo sur le System/360 . IMS était généralement similaire dans son concept à CODASYL, mais utilisait une hiérarchie stricte pour son modèle de navigation de données au lieu du modèle de réseau de CODASYL. Les deux concepts sont devenus plus tard connus sous le nom de bases de données de navigation en raison de la manière dont les données étaient accessibles: le terme a été popularisé par la présentation du prix Turing de Bachman en 1973, The Programmer as Navigator . IMS est classé par IBM comme une Base de données hiérarchique . TOTAL IDMS et Cincom Systemsles bases de données sont classées comme bases de données réseau. IMS est toujours utilisé depuis 2014 [mettre à jour]. [11]
Années 1970, SGBD relationnel
Edgar F. Codd a travaillé chez IBM à San Jose, en Californie , dans l’un de leurs bureaux annexes qui étaient principalement impliqués dans le développement de systèmes de disques durs . Il n’était pas satisfait du modèle de navigation de l’approche CODASYL, notamment de l’absence d’une fonction de “recherche”. En 1970, il a écrit un certain nombre d’articles décrivant une nouvelle approche de la construction de bases de données qui a finalement abouti au révolutionnaire A Relational Model of Data for Large Shared Data Banks . [12]
Dans cet article, il décrit un nouveau système pour stocker et travailler avec de grandes bases de données. Au lieu que les enregistrements soient stockés dans une sorte de liste liée d’enregistrements de forme libre comme dans CODASYL, l’idée de Codd était d’organiser les données en un certain nombre de ” tables “, chaque table étant utilisée pour un type d’entité différent. Chaque tableau contiendrait un nombre fixe de colonnes contenant les attributs de l’entité. Une ou plusieurs colonnes de chaque table ont été désignées comme une clé primaire par laquelle les lignes de la table pourraient être identifiées de manière unique ; les références croisées entre les tables utilisaient toujours ces clés primaires, plutôt que les adresses de disque, et les requêtes joignaient les tables en fonction de ces relations de clés, en utilisant un ensemble d’opérations basées sur le système mathématique du calcul relationnel(d’où le modèle tire son nom). Le découpage des données en un ensemble de tables (ou relations ) normalisées visait à s’assurer que chaque “fait” n’était stocké qu’une seule fois, simplifiant ainsi les opérations de mise à jour. Les tables virtuelles appelées vues pouvaient présenter les données de différentes manières pour différents utilisateurs, mais les vues ne pouvaient pas être directement mises à jour.
Codd a utilisé des termes mathématiques pour définir le modèle : relations, tuples et domaines plutôt que tables, lignes et colonnes. La terminologie qui est maintenant familière provient des premières implémentations. Codd critiquera plus tard la tendance des implémentations pratiques à s’écarter des fondements mathématiques sur lesquels le modèle était basé.
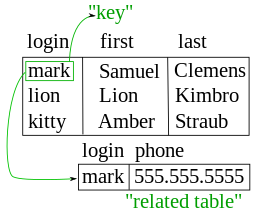 Dans le modèle relationnel , les enregistrements sont “liés” à l’aide de clés virtuelles non stockées dans la base de données mais définies au besoin entre les données contenues dans les enregistrements.
Dans le modèle relationnel , les enregistrements sont “liés” à l’aide de clés virtuelles non stockées dans la base de données mais définies au besoin entre les données contenues dans les enregistrements.
L’utilisation de clés primaires (identificateurs orientés utilisateur) pour représenter les relations entre tables, plutôt que les adresses de disque, avait deux motivations principales. D’un point de vue technique, cela a permis de déplacer et de redimensionner les tables sans réorganisation coûteuse de la base de données. Mais Codd était plus intéressé par la différence de sémantique : l’utilisation d’identificateurs explicites facilitait la définition des opérations de mise à jour avec des définitions mathématiques propres, et elle permettait également de définir les opérations de requête en termes de la discipline établie du Calcul des prédicats du premier ordre.; étant donné que ces opérations ont des propriétés mathématiques propres, il devient possible de réécrire les requêtes de manière prouvée correcte, ce qui est la base de l’optimisation des requêtes. Il n’y a pas de perte d’expressivité par rapport aux modèles hiérarchiques ou en réseau, même si les connexions entre tables ne sont plus aussi explicites.
Dans les modèles hiérarchiques et en réseau, les enregistrements pouvaient avoir une structure interne complexe. Par exemple, l’historique des salaires d’un employé peut être représenté sous la forme d’un « groupe répétitif » dans l’enregistrement de l’employé. Dans le modèle relationnel, le processus de normalisation a conduit à remplacer ces structures internes par des données contenues dans plusieurs tables, reliées uniquement par des clés logiques.
Par exemple, une utilisation courante d’un système de base de données consiste à suivre les informations sur les utilisateurs, leur nom, leurs informations de connexion, diverses adresses et numéros de téléphone. Dans l’approche de navigation, toutes ces données seraient placées dans un seul enregistrement de longueur variable. Dans l’approche relationnelle, les données seraient normalisées dans une table d’utilisateurs, une table d’adresses et une table de numéros de téléphone (par exemple). Les enregistrements ne seraient créés dans ces tables facultatives que si l’adresse ou les numéros de téléphone étaient réellement fournis.
En plus d’identifier les lignes/enregistrements à l’aide d’identificateurs logiques plutôt que d’adresses de disque, Codd a modifié la manière dont les applications assemblaient les données à partir de plusieurs enregistrements. Plutôt que d’exiger que les applications collectent les données un enregistrement à la fois en naviguant sur les liens, elles utiliseraient un langage de requête déclaratif qui exprimerait les données requises, plutôt que le chemin d’accès par lequel elles devraient être trouvées. Trouver un chemin d’accès efficace aux données est devenu la responsabilité du système de gestion de base de données, plutôt que du programmeur d’application. Ce processus, appelé optimisation des requêtes, dépendait du fait que les requêtes étaient exprimées en termes de logique mathématique.
Le papier de Codd a été repris par deux personnes à Berkeley, Eugene Wong et Michael Stonebraker . Ils ont lancé un projet appelé INGRES en utilisant des fonds déjà alloués pour un projet de base de données géographiques et des étudiants programmeurs pour produire du code. À partir de 1973, INGRES a livré ses premiers produits de test qui étaient généralement prêts à être largement utilisés en 1979. INGRES était similaire au système R à plusieurs égards, y compris l’utilisation d’un “langage” pour l’accès aux données , connu sous le nom de QUEL . Au fil du temps, INGRES est passé à la norme SQL émergente.
IBM lui-même a réalisé une implémentation test du modèle relationnel, PRTV , et une implémentation de production, Business System 12 , toutes deux désormais abandonnées. Honeywell a écrit MRDS pour Multics , et maintenant il y a deux nouvelles implémentations : Alphora Dataphor et Rel . La plupart des autres implémentations de SGBD généralement appelées relationnelles sont en fait des SGBD SQL.
En 1970, l’Université du Michigan a commencé le développement du système de gestion de l’information MICRO [13] basé sur le modèle de données théoriques ensemblistes de DL Childs . [14] [15] [16] MICRO a été utilisé pour gérer de très grands ensembles de données par le Département américain du travail , l’ Agence américaine de protection de l’environnement et des chercheurs de l’ Université de l’Alberta , de l’ Université du Michigan et de l’Université Wayne State . Il fonctionnait sur des ordinateurs centraux IBM utilisant le Michigan Terminal System . [17] Le système est resté en production jusqu’en 1998.
Approche intégrée
Dans les années 1970 et 1980, des tentatives ont été faites pour construire des systèmes de bases de données avec du matériel et des logiciels intégrés. La philosophie sous-jacente était qu’une telle intégration fournirait de meilleures performances à moindre coût. Les exemples étaient IBM System / 38 , la première offre de Teradata et la machine de base de données Britton Lee, Inc. .
L’accélérateur CAFS d’ ICL , un contrôleur de disque matériel doté de capacités de recherche programmables, constitue une autre approche de prise en charge matérielle de la gestion des bases de données . À long terme, ces efforts ont généralement échoué car les machines de bases de données spécialisées ne pouvaient pas suivre le rythme du développement et des progrès rapides des ordinateurs à usage général. Ainsi, la plupart des systèmes de bases de données sont aujourd’hui des systèmes logiciels fonctionnant sur du matériel à usage général, utilisant un stockage de données informatiques à usage général. Cependant, cette idée est toujours poursuivie dans certaines applications par certaines sociétés comme Netezza et Oracle ( Exadata ).
Fin des années 1970, SGBD SQL
IBM a commencé à travailler sur un système prototype vaguement basé sur les concepts de Codd sous le nom de System R au début des années 1970. La première version était prête en 1974/5, et les travaux ont alors commencé sur des systèmes multi-tables dans lesquels les données pouvaient être divisées afin que toutes les données d’un enregistrement (dont certaines sont facultatives) n’aient pas à être stockées dans un seul grand “morceau”. Des versions multi-utilisateurs ultérieures ont été testées par des clients en 1978 et 1979, date à laquelle un langage de requête standardisé – SQL [ citation nécessaire ] – avait été ajouté. Les idées de Codd s’imposaient à la fois comme réalisables et supérieures à CODASYL, poussant IBM à développer une véritable version de production de System R, connue sous le nom de SQL/DS , et, plus tard, Database 2 (IBM DB2 ).
La Base de données Oracle de Larry Ellison (ou plus simplement, Oracle ) a commencé à partir d’une chaîne différente, basée sur les articles d’IBM sur System R. Bien que les implémentations d’Oracle V1 aient été achevées en 1978, ce n’est qu’avec la version 2 d’Oracle qu’Ellison a battu IBM sur le marché. en 1979. [18]
Stonebraker a ensuite appliqué les leçons d’INGRES pour développer une nouvelle base de données, Postgres, désormais connue sous le nom de PostgreSQL . PostgreSQL est souvent utilisé pour des applications stratégiques mondiales (les registres de noms de domaine .org et .info l’utilisent comme principal magasin de données , comme le font de nombreuses grandes entreprises et institutions financières).
En Suède, l’article de Codd a également été lu et Mimer SQL a été développé au milieu des années 1970 à l’Université d’Uppsala . En 1984, ce projet a été consolidé en une entreprise indépendante.
Un autre modèle de données, le modèle entité-relation , est apparu en 1976 et a gagné en popularité pour la conception de bases de données car il mettait l’accent sur une description plus familière que le modèle relationnel antérieur. Plus tard, les constructions entité-relation ont été adaptées en tant que construction de modélisation de données pour le modèle relationnel, et la différence entre les deux est devenue sans objet. [ citation nécessaire ]
années 1980, sur le bureau
Les années 1980 ont inauguré l’ère de l’informatique de bureau . Les nouveaux ordinateurs dotaient leurs utilisateurs de tableurs comme Lotus 1-2-3 et de logiciels de base de données comme DBASE . Le produit DBASE était léger et facile à comprendre pour tout utilisateur d’ordinateur. C. Wayne Ratliff , le créateur de DBASE, a déclaré : “DBASE était différent de programmes comme BASIC, C, FORTRAN et COBOL en ce sens qu’une grande partie du sale boulot avait déjà été fait. La manipulation des données est effectuée par DBASE au lieu de par l’utilisateur, afin que l’utilisateur puisse se concentrer sur ce qu’il fait, plutôt que d’avoir à se soucier des détails sales de l’ouverture, de la lecture et de la fermeture des fichiers, et de la gestion de l’allocation de l’espace.” [19]DBASE était l’un des logiciels les plus vendus dans les années 1980 et au début des années 1990.
années 1990, orienté objet
Les années 1990, parallèlement à l’essor de la programmation orientée objet , ont vu une croissance de la manière dont les données de diverses bases de données étaient traitées. Les programmeurs et les concepteurs ont commencé à traiter les données de leurs bases de données comme des objets . C’est-à-dire que si les données d’une personne se trouvaient dans une base de données, les attributs de cette personne, tels que son adresse, son numéro de téléphone et son âge, étaient désormais considérés comme appartenant à cette personne au lieu d’être des données étrangères. Cela permet aux relations entre les données d’être liées aux objets et à leurs attributs et non à des champs individuels. [20] Le terme « non-concordance d’impédance relationnelle objet » décrit l’inconvénient de la traduction entre les objets programmés et les tables de base de données. Bases de données d’objets etLes bases de données relationnelles objet tentent de résoudre ce problème en fournissant un langage orienté objet (parfois sous forme d’extensions de SQL) que les programmeurs peuvent utiliser comme alternative au SQL purement relationnel. Du côté de la programmation, les bibliothèques connues sous le nom de mappages objet-relationnel (ORM) tentent de résoudre le même problème.
Années 2000, NoSQL et NewSQL
Les Bases de données XML sont un type de base de données orientée document structurée qui permet d’effectuer des requêtes basées sur des attributs de document XML . Les Bases de données XML sont principalement utilisées dans des applications où les données sont commodément considérées comme une collection de documents, avec une structure qui peut varier de très flexible à très rigide : par exemple, les articles scientifiques, les brevets, les déclarations de revenus et les dossiers du personnel.
Les bases de données NoSQL sont souvent très rapides, ne nécessitent pas de schémas de table fixes, évitent les opérations de jointure en stockant des données dénormalisées et sont conçues pour évoluer horizontalement .
Ces dernières années, il y a eu une forte demande pour des bases de données massivement distribuées avec une tolérance de partition élevée, mais selon le théorème CAP , il est impossible pour un système distribué de fournir simultanément des garanties de cohérence , de disponibilité et de tolérance de partition. Un système distribué peut satisfaire deux de ces garanties en même temps, mais pas les trois. Pour cette raison, de nombreuses bases de données NoSQL utilisent ce qu’on appelle la cohérence éventuelle pour fournir à la fois des garanties de disponibilité et de tolérance de partition avec un niveau réduit de cohérence des données.
NewSQL est une classe de bases de données relationnelles modernes qui vise à fournir les mêmes performances évolutives que les systèmes NoSQL pour les charges de travail de traitement des transactions en ligne (lecture-écriture) tout en utilisant SQL et en maintenant les garanties ACID d’un système de base de données traditionnel.
Cas d’utilisation
| Cette section ne cite aucune source . ( mars 2013 ) Please help improve this section by adding citations to reliable sources. Unsourced material may be challenged and removed. (Learn how and when to remove this template message) |
Les bases de données sont utilisées pour soutenir les opérations internes des organisations et pour étayer les interactions en ligne avec les clients et les fournisseurs (voir Logiciels d’entreprise ).
Les bases de données sont utilisées pour contenir des informations administratives et des données plus spécialisées, telles que des données d’ingénierie ou des modèles économiques. Les exemples incluent les systèmes de bibliothèque informatisés, les systèmes de réservation de vols, les systèmes informatisés d’ inventaire des pièces et de nombreux systèmes de gestion de contenu qui stockent les sites Web sous forme de collections de pages Web dans une base de données.
Classification
Une façon de classer les bases de données implique le type de leur contenu, par exemple : objets bibliographiques , document-texte, statistiques ou multimédias. Une autre façon est par leur domaine d’application, par exemple : comptabilité, compositions musicales, films, banque, fabrication ou assurance. Une troisième méthode consiste à utiliser certains aspects techniques, tels que la structure de la base de données ou le type d’interface. Cette section énumère quelques-uns des adjectifs utilisés pour caractériser différents types de bases de données.
- Une base de données en mémoire est une base de données qui réside principalement dans la mémoire principale , mais qui est généralement sauvegardée par un stockage de données informatiques non volatile. Les bases de données de la mémoire principale sont plus rapides que les bases de données sur disque et sont donc souvent utilisées lorsque le temps de réponse est critique, comme dans les équipements de réseau de télécommunications.
- Une base de données active comprend une architecture pilotée par les événements qui peut répondre à des conditions à la fois à l’intérieur et à l’extérieur de la base de données. Les utilisations possibles incluent la surveillance de la sécurité, les alertes, la collecte de statistiques et l’autorisation. De nombreuses bases de données fournissent des fonctionnalités de base de données actives sous la forme de déclencheurs de base de données .
- Une base de données cloud s’appuie sur la technologie cloud . La base de données et la plupart de ses SGBD résident à distance, “dans le cloud”, tandis que ses applications sont à la fois développées par des programmeurs, puis maintenues et utilisées par les utilisateurs finaux via un navigateur Web et des API ouvertes .
- Les entrepôts de données archivent les données des bases de données opérationnelles et souvent de sources externes telles que les sociétés d’études de marché. L’entrepôt devient la source centrale de données à l’usage des gestionnaires et autres utilisateurs finaux qui n’ont peut-être pas accès aux données opérationnelles. Par exemple, les données de vente peuvent être agrégées en totaux hebdomadaires et converties à partir de codes de produits internes pour utiliser des UPC afin de pouvoir les comparer aux données ACNielsen . Certains composants de base et essentiels de l’entreposage de données comprennent l’extraction, l’analyse et l’exploration de données, la transformation, le chargement et la gestion des données afin de les rendre disponibles pour une utilisation ultérieure.
- Une base de données déductive combine la programmation logique avec une base de données relationnelle.
- Une base de données distribuée est une base de données dans laquelle les données et le SGBD s’étendent sur plusieurs ordinateurs.
- Une base de données orientée document est conçue pour stocker, récupérer et gérer des informations orientées document ou semi-structurées. Les bases de données orientées document sont l’une des principales catégories de bases de données NoSQL.
- Un système de base de données intégré est un SGBD étroitement intégré à un logiciel d’application qui nécessite un accès aux données stockées de telle manière que le SGBD est caché aux utilisateurs finaux de l’application et nécessite peu ou pas de maintenance continue. [21]
- Les bases de données d’utilisateurs finaux sont constituées de données développées par des utilisateurs finaux individuels. Il s’agit par exemple de collections de documents, de feuilles de calcul, de présentations, de fichiers multimédias et d’autres fichiers. Plusieurs produits existent pour prendre en charge ces bases de données. Certains d’entre eux sont beaucoup plus simples que les SGBD à part entière, avec des fonctionnalités de SGBD plus élémentaires.
- Un système de bases de données fédérées comprend plusieurs bases de données distinctes, chacune avec son propre SGBD. Il est géré comme une base de données unique par un système de gestion de base de données fédérée (FDBMS), qui intègre de manière transparente plusieurs SGBD autonomes, éventuellement de types différents (auquel cas il s’agirait également d’un système de base de données hétérogène ), et leur fournit une vue conceptuelle intégrée .
- Parfois, le terme multi-base de données est utilisé comme synonyme de base de données fédérée, bien qu’il puisse faire référence à un groupe de bases de données moins intégré (par exemple, sans FDBMS ni schéma intégré géré) qui coopèrent dans une seule application. Dans ce cas, un middleware est généralement utilisé pour la distribution, qui comprend généralement un protocole de validation atomique (ACP), par exemple, le protocole de validation en deux phases , pour permettre des transactions distribuées (globales) entre les bases de données participantes.
- Une base de données de graphes est une sorte de base de données NoSQL qui utilise des structures de graphes avec des nœuds, des arêtes et des propriétés pour représenter et stocker des informations. Les bases de données de graphes générales qui peuvent stocker n’importe quel graphe sont distinctes des bases de données de graphes spécialisées telles que les triplestores et les bases de données réseau .
- Un SGBD de tableau est une sorte de SGBD NoSQL qui permet la modélisation, le stockage et la récupération de tableaux multidimensionnels (généralement volumineux) tels que des images satellites et des résultats de simulation climatique.
- Dans une base de données hypertexte ou hypermédia , tout mot ou morceau de texte représentant un objet, par exemple un autre morceau de texte, un article, une image ou un film, peut être lié par hyperlien à cet objet. Les bases de données hypertextes sont particulièrement utiles pour organiser de grandes quantités d’informations disparates. Par exemple, ils sont utiles pour organiser des encyclopédies en ligne , où les utilisateurs peuvent facilement parcourir le texte. Le World Wide Web est donc une grande base de données hypertexte distribuée.
- Une base de connaissances (en abrégé KB , kb ou Δ [22] [23] ) est un type particulier de base de données pour la gestion des connaissances , fournissant les moyens pour la collecte, l’organisation et la récupération informatisées des connaissances . Également une collection de données représentant des problèmes avec leurs solutions et expériences connexes.
- Une base de données mobile peut être transportée ou synchronisée à partir d’un dispositif informatique mobile.
- Les bases de données opérationnelles stockent des données détaillées sur les opérations d’une organisation. Ils traitent généralement des volumes relativement élevés de mises à jour à l’aide de transactions . Les exemples incluent les bases de données clients qui enregistrent les informations de contact, de crédit et démographiques sur les clients d’une entreprise, les bases de données du personnel qui contiennent des informations telles que le salaire, les avantages, les données sur les compétences des employés, les systèmes de planification des ressources d’entreprise qui enregistrent des détails sur les composants du produit, l’inventaire des pièces et les informations financières. des bases de données qui gardent une trace de l’argent, de la comptabilité et des transactions financières de l’organisation.
- Une base de données parallèle cherche à améliorer les performances grâce à la parallélisation pour des tâches telles que le chargement de données, la création d’index et l’évaluation de requêtes.
Les principales architectures de SGBD parallèles induites par l’ architecture matérielle sous-jacente sont :
- Architecture de mémoire partagée , où plusieurs processeurs partagent l’espace mémoire principal, ainsi que d’autres stockages de données.
- Architecture de disque partagé , où chaque unité de traitement (généralement constituée de plusieurs processeurs) possède sa propre mémoire principale, mais toutes les unités partagent l’autre stockage.
- Architecture sans partage , où chaque unité de traitement a sa propre mémoire principale et d’autres stockages.
- Les bases de données probabilistes utilisent la logique floue pour tirer des conclusions à partir de données imprécises.
- Les bases de données en temps réel traitent les transactions suffisamment rapidement pour que le résultat revienne et soit immédiatement utilisé.
- Une base de données spatiale peut stocker les données avec des caractéristiques multidimensionnelles. Les requêtes sur ces données incluent des requêtes basées sur la localisation, telles que “Où se trouve l’hôtel le plus proche dans ma région ?”.
- Une base de données temporelle a des aspects temporels intégrés, par exemple un modèle de données temporelles et une version temporelle de SQL . Plus précisément, les aspects temporels incluent généralement le temps de validité et le temps de transaction.
- Une base de données terminologique s’appuie sur une base de données orientée objet , souvent personnalisée pour un domaine spécifique.
- Une base de données de données non structurées est destinée à stocker de manière gérable et protégée divers objets qui ne s’intègrent pas naturellement et commodément dans des bases de données communes. Il peut s’agir de messages électroniques, de documents, de journaux, d’objets multimédias, etc. Le nom peut être trompeur car certains objets peuvent être très structurés. Cependant, toute la collection d’objets possible ne rentre pas dans un cadre structuré prédéfini. La plupart des SGBD établis prennent désormais en charge les données non structurées de diverses manières, et de nouveaux SGBD dédiés font leur apparition.
Système de gestion de base de données
Connolly et Begg définissent le système de gestion de base de données (SGBD) comme un “système logiciel qui permet aux utilisateurs de définir, créer, maintenir et contrôler l’accès à la base de données”. [24] Parmi les exemples de SGBD figurent MySQL , PostgreSQL , Microsoft SQL Server , Oracle Database et Microsoft Access .
L’acronyme SGBD est parfois étendu pour indiquer le modèle de base de données sous-jacent , avec RDBMS pour le relationnel , OODBMS pour l’ objet (orienté) et ORDBMS pour le modèle objet-relationnel . D’autres extensions peuvent indiquer d’autres caractéristiques, telles que DDBMS pour un système de gestion de base de données distribué.
Les fonctionnalités fournies par un SGBD peuvent varier énormément. La fonctionnalité principale est le stockage, la récupération et la mise à jour des données. Codd a proposé les fonctions et services suivants qu’un SGBD à usage général à part entière devrait fournir : [25]
- Stockage, récupération et mise à jour des données
- Catalogue accessible à l’utilisateur ou dictionnaire de données décrivant les métadonnées
- Prise en charge des transactions et de la concurrence
- Installations pour récupérer la base de données si elle est endommagée
- Prise en charge de l’autorisation d’accès et de la mise à jour des données
- Accéder à l’assistance à distance
- Appliquer des contraintes pour s’assurer que les données de la base de données respectent certaines règles
Il faut aussi généralement s’attendre à ce que le SGBD fournisse un ensemble d’utilitaires nécessaires à l’administration efficace de la base de données, notamment des utilitaires d’importation, d’exportation, de surveillance, de défragmentation et d’analyse. [26] La partie centrale du SGBD interagissant entre la base de données et l’interface de l’application, parfois appelée moteur de base de données .
Souvent, les SGBD auront des paramètres de configuration qui peuvent être réglés de manière statique et dynamique, par exemple la quantité maximale de mémoire principale sur un serveur que la base de données peut utiliser. La tendance est de minimiser la quantité de configuration manuelle, et pour des cas tels que les bases de données embarquées, la nécessité de viser l’absence d’administration est primordiale.
Les SGBD des grandes entreprises ont eu tendance à augmenter en taille et en fonctionnalités et peuvent avoir impliqué des milliers d’années humaines d’efforts de développement tout au long de leur vie. [un]
Les premiers SGBD multi-utilisateurs permettaient généralement uniquement à l’application de résider sur le même ordinateur avec un accès via des terminaux ou un logiciel d’émulation de terminal. L’ architecture client-serveur était un développement où l’application résidait sur un poste client et la base de données sur un serveur permettant de répartir les traitements. Cela a évolué vers une architecture multiniveau incorporant des serveurs d’ applications et des serveurs Web avec l’interface utilisateur final via un navigateur Web avec la base de données uniquement directement connectée au niveau adjacent. [27]
Un SGBD à usage général fournira des interfaces de programmation d’application (API) publiques et éventuellement un processeur pour les langages de base de données tels que SQL pour permettre aux applications d’être écrites pour interagir avec la base de données. Un SGBD à usage spécifique peut utiliser une API privée et être spécifiquement personnalisé et lié à une seule application. Par exemple, un système de messagerie exécute de nombreuses fonctions d’un SGBD à usage général telles que l’insertion de messages, la suppression de messages, la gestion des pièces jointes, la recherche de listes de blocage, l’association de messages à une adresse e-mail, etc., mais ces fonctions sont limitées à ce qui est nécessaire pour gérer e-mail.
Application
L’interaction externe avec la base de données se fera via un programme d’application qui s’interface avec le SGBD. [28] Cela peut aller d’un outil de base de données qui permet aux utilisateurs d’exécuter des requêtes SQL textuellement ou graphiquement, à un site Web qui utilise une base de données pour stocker et rechercher des informations.
Interface du programme d’application
Un programmeur codera les interactions avec la base de données (parfois appelée source de données ) via une interface de programme d’application (API) ou via un langage de base de données . L’API ou le langage particulier choisi devra être pris en charge par le SGBD, éventuellement indirectement via un préprocesseur ou une API de pontage. Certaines API visent à être indépendantes de la base de données, ODBC étant un exemple communément connu. Les autres API courantes incluent JDBC et ADO.NET .
Langues de la base de données
Les langages de base de données sont des langages à usage spécifique, qui permettent une ou plusieurs des tâches suivantes, parfois distinguées en tant que sous – langages :
- Langage de contrôle des données (DCL) – contrôle l’accès aux données ;
- Langage de définition de données (DDL) – définit les types de données tels que la création, la modification ou la suppression de tables et les relations entre elles ;
- Langage de manipulation de données (DML) – effectue des tâches telles que l’insertion, la mise à jour ou la suppression d’occurrences de données ;
- Langage de requête de données (DQL) – permet de rechercher des informations et de calculer des informations dérivées.
Les langages de base de données sont spécifiques à un modèle de données particulier. Les exemples notables incluent:
- SQL combine les rôles de définition de données, de manipulation de données et de requête dans un seul langage. C’était l’un des premiers langages commerciaux pour le modèle relationnel, bien qu’il s’écarte à certains égards du modèle relationnel tel que décrit par Codd (par exemple, les lignes et les colonnes d’un tableau peuvent être ordonnées). SQL est devenu une norme de l’ American National Standards Institute (ANSI) en 1986 et de l’ Organisation internationale de normalisation (ISO) en 1987. Les normes ont été régulièrement améliorées depuis et sont prises en charge (avec divers degrés de conformité) par toutes les SGBD relationnels. [29] [30]
- OQL est une norme de langage de modèle objet (de l’ Object Data Management Group ). Il a influencé la conception de certains des langages de requête les plus récents tels que JDOQL et EJB QL .
- XQuery est un langage de requête XML standard implémenté par des systèmes de Bases de données XML tels que MarkLogic et eXist , par des bases de données relationnelles avec capacité XML telles qu’Oracle et Db2, ainsi que par des processeurs XML en mémoire tels que Saxon .
- SQL/XML combine XQuery avec SQL. [31]
Un langage de base de données peut également intégrer des fonctionnalités telles que :
- Configuration spécifique au SGBD et gestion du moteur de stockage
- Calculs pour modifier les résultats des requêtes, comme le comptage, la sommation, la moyenne, le tri, le regroupement et les références croisées
- Application de contraintes (par exemple, dans une base de données automobile, n’autorisant qu’un seul type de moteur par voiture)
- Version d’interface de programmation d’application du langage de requête, pour la commodité du programmeur
Stockage
Le stockage de base de données est le conteneur de la matérialisation physique d’une base de données. Il comprend le niveau interne ( physique) de l’architecture de la base de données. Il contient également toutes les informations nécessaires (par exemple, les métadonnées , les “données sur les données” et les structures de données internes ) pour reconstruire le niveau conceptuel et le niveau externe à partir du niveau interne en cas de besoin. Les bases de données en tant qu’objets numériques contiennent trois couches d’informations qui doivent être stockées : les données, la structure et la sémantique. Un stockage approprié des trois couches est nécessaire pour la préservation future et la longévité de la base de données. [32]Le stockage permanent des données relève généralement de la responsabilité du moteur de base de données, également appelé “moteur de stockage”. Bien que généralement accessible par un SGBD via le système d’exploitation sous-jacent (et souvent en utilisant les systèmes de fichiers des systèmes d’exploitationen tant qu’intermédiaires pour la disposition du stockage), les propriétés de stockage et les paramètres de configuration sont extrêmement importants pour le fonctionnement efficace du SGBD et sont donc étroitement gérés par les administrateurs de base de données. Un SGBD, lorsqu’il est en fonctionnement, a toujours sa base de données résidant dans plusieurs types de stockage (par exemple, mémoire et stockage externe). Les données de la base de données et les informations supplémentaires nécessaires, éventuellement en très grande quantité, sont codées en bits. Les données résident généralement dans le stockage dans des structures qui semblent complètement différentes de la façon dont les données se présentent aux niveaux conceptuel et externe, mais de manière à tenter d’optimiser (le mieux possible) la reconstruction de ces niveaux lorsque les utilisateurs et les programmes en ont besoin, ainsi que quant au calcul de types supplémentaires d’informations nécessaires à partir des données (par exemple, lors de l’interrogation de la base de données).
Certains SGBD prennent en charge la spécification du codage de caractères utilisé pour stocker les données, de sorte que plusieurs codages peuvent être utilisés dans la même base de données.
Diverses structures de stockage de base de données de bas niveau sont utilisées par le moteur de stockage pour sérialiser le modèle de données afin qu’il puisse être écrit sur le support de votre choix. Des techniques telles que l’indexation peuvent être utilisées pour améliorer les performances. Le stockage conventionnel est orienté lignes, mais il existe également des bases de données orientées colonnes et de corrélation .
Vues matérialisées
Souvent, la redondance du stockage est utilisée pour augmenter les performances. Un exemple courant est le stockage des vues matérialisées , qui consistent en des vues externes ou des résultats de requête fréquemment utilisés. Le stockage de ces vues permet d’économiser le coût de leur calcul à chaque fois qu’elles sont nécessaires. Les inconvénients des vues matérialisées sont la surcharge encourue lors de leur mise à jour pour les maintenir synchronisées avec leurs données de base de données mises à jour d’origine, et le coût de la redondance du stockage.
Réplication
Parfois, une base de données utilise la redondance de stockage par réplication d’objets de base de données (avec une ou plusieurs copies) pour augmenter la disponibilité des données (à la fois pour améliorer les performances des accès simultanés de plusieurs utilisateurs finaux au même objet de base de données et pour assurer la résilience en cas de défaillance partielle de une base de données distribuée). Les mises à jour d’un objet répliqué doivent être synchronisées sur les copies d’objet. Dans de nombreux cas, la base de données entière est répliquée.
Sécurité
| Cet article semble contredire l’article Sécurité de la base de données . ( mars 2013 ) Please see discussion on the linked talk page. (Learn how and when to remove this template message) |
La sécurité de la base de données traite de tous les aspects de la protection du contenu de la base de données, de ses propriétaires et de ses utilisateurs. Cela va de la protection contre les utilisations intentionnelles non autorisées de la base de données aux accès non intentionnels à la base de données par des entités non autorisées (par exemple, une personne ou un programme informatique).
Le contrôle d’accès à la base de données consiste à contrôler qui (une personne ou un certain programme informatique) est autorisé à accéder à quelles informations de la base de données. Les informations peuvent comprendre des objets de base de données spécifiques (par exemple, des types d’enregistrements, des enregistrements spécifiques, des structures de données), certains calculs sur certains objets (par exemple, des types de requêtes ou des requêtes spécifiques), ou l’utilisation de chemins d’accès spécifiques aux premiers (par exemple, l’utilisation d’index spécifiques ou d’autres structures de données pour accéder aux informations). Les contrôles d’accès à la base de données sont définis par un personnel spécialement autorisé (par le propriétaire de la base de données) qui utilise des interfaces de SGBD de sécurité protégées dédiées.
Cela peut être géré directement sur une base individuelle, ou par l’attribution d’individus et de privilèges à des groupes, ou (dans les modèles les plus élaborés) par l’attribution d’individus et de groupes à des rôles auxquels sont ensuite attribués des droits. La sécurité des données empêche les utilisateurs non autorisés de consulter ou de mettre à jour la base de données. À l’aide de mots de passe, les utilisateurs sont autorisés à accéder à l’ensemble de la base de données ou à des sous-ensembles de celle-ci appelés “sous-schémas”. Par exemple, une base de données d’employés peut contenir toutes les données d’un employé individuel, mais un groupe d’utilisateurs peut être autorisé à afficher uniquement les données de paie, tandis que d’autres n’ont accès qu’aux antécédents professionnels et aux données médicales. Si le SGBD offre un moyen d’entrer et de mettre à jour la base de données de manière interactive, ainsi que de l’interroger, cette capacité permet de gérer des bases de données personnelles.
La sécurité des données en général traite de la protection de blocs de données spécifiques, à la fois physiquement (c’est-à-dire contre la corruption, la destruction ou la suppression ; par exemple, voir la sécurité physique ), ou leur interprétation, ou des parties d’entre eux, en informations significatives (par exemple, par en regardant les chaînes de bits qu’ils comprennent, en concluant des numéros de carte de crédit valides spécifiques ; par exemple, voir le cryptage des données ).
Modifiez et accédez aux enregistrements de journalisation qui ont accédé à quels attributs, ce qui a été modifié et quand cela a été modifié. Les services de journalisation permettent un audit ultérieur de la base de données médico-légale en conservant un enregistrement des occurrences d’accès et des modifications. Parfois, le code au niveau de l’application est utilisé pour enregistrer les modifications plutôt que de les laisser dans la base de données. La surveillance peut être configurée pour tenter de détecter les failles de sécurité. Par conséquent, les organisations doivent prendre au sérieux la sécurité des bases de données en raison des nombreux avantages qu’elle offre. Les organisations seront protégées contre les failles de sécurité et les activités de piratage telles que l’intrusion de pare-feu, la propagation de virus et les logiciels de rançon. Cela aide à protéger les informations essentielles de l’entreprise, qui ne peuvent en aucun cas être partagées avec des tiers. [33]
Transactions et simultanéité
Les transactions de base de données peuvent être utilisées pour introduire un certain niveau de tolérance aux pannes et d’intégrité des données après la récupération après une panne . Une transaction de base de données est une unité de travail, encapsulant généralement un certain nombre d’opérations sur une base de données (par exemple, lire un objet de base de données, écrire, acquérir ou libérer un verrou , etc.), une abstraction prise en charge dans la base de données et également dans d’autres systèmes. Chaque transaction a des limites bien définies en termes d’exécutions de programme/code incluses dans cette transaction (déterminées par le programmeur de la transaction via des commandes de transaction spéciales).
L’acronyme ACID décrit certaines propriétés idéales d’une transaction de base de données : atomicité , cohérence , isolation et durabilité .
Migration
Une base de données construite avec un SGBD n’est pas portable vers un autre SGBD (c’est-à-dire que l’autre SGBD ne peut pas l’exécuter). Cependant, dans certaines situations, il est souhaitable de migrer une base de données d’un SGBD vers un autre. Les raisons sont principalement économiques (différents SGBD peuvent avoir des coûts totaux de possession différentsou TCO), fonctionnels et opérationnels (différents SGBD peuvent avoir des capacités différentes). La migration implique la transformation de la base de données d’un type de SGBD à un autre. La transformation doit conserver (si possible) l’application liée à la base de données (c’est-à-dire tous les programmes d’application associés) intacte. Ainsi, les niveaux conceptuels et architecturaux externes de la base de données doivent être conservés dans la transformation. Il peut être souhaitable que certains aspects du niveau interne de l’architecture soient également conservés. Une migration de base de données complexe ou volumineuse peut être un projet compliqué et coûteux (ponctuel) en soi, qui doit être pris en compte dans la décision de migrer. Ceci en dépit du fait que des outils peuvent exister pour faciliter la migration entre des SGBD spécifiques. Généralement, un fournisseur de SGBD fournit des outils pour aider à importer des bases de données à partir d’autres SGBD populaires.
Construire, entretenir et régler
Après avoir conçu une base de données pour une application, l’étape suivante consiste à créer la base de données. En règle générale, un SGBD à usage général approprié peut être sélectionné pour être utilisé à cette fin. Un SGBD fournit les interfaces utilisateur nécessaires à utiliser par les administrateurs de base de données pour définir les structures de données de l’application nécessaire dans le modèle de données respectif du SGBD. D’autres interfaces utilisateur sont utilisées pour sélectionner les paramètres de SGBD nécessaires (comme la sécurité, les paramètres d’allocation de stockage, etc.).
Lorsque la base de données est prête (toutes ses structures de données et les autres composants nécessaires sont définis), elle est généralement remplie avec les données initiales de l’application (initialisation de la base de données, qui est généralement un projet distinct ; dans de nombreux cas, l’utilisation d’interfaces SGBD spécialisées prenant en charge l’insertion en bloc) avant le rendre opérationnel. Dans certains cas, la base de données devient opérationnelle alors qu’elle est vide de données d’application, et des données sont accumulées pendant son fonctionnement.
Une fois la base de données créée, initialisée et remplie, elle doit être maintenue. Divers paramètres de base de données peuvent avoir besoin d’être modifiés et la base de données peut avoir besoin d’être ajustée ( tuning ) pour de meilleures performances ; les structures de données de l’application peuvent être modifiées ou ajoutées, de nouveaux programmes d’application connexes peuvent être écrits pour ajouter à la fonctionnalité de l’application, etc.
Sauvegarde et restauration
Parfois, on souhaite ramener une base de données à un état antérieur (pour de nombreuses raisons, par exemple, les cas où la base de données est trouvée corrompue en raison d’une erreur logicielle, ou si elle a été mise à jour avec des données erronées). Pour ce faire, une opération de sauvegarde est effectuée occasionnellement ou en continu, où chaque état de base de données souhaité (c’est-à-dire les valeurs de ses données et leur intégration dans les structures de données de la base de données) est conservé dans des fichiers de sauvegarde dédiés (de nombreuses techniques existent pour le faire efficacement). Lorsqu’il est décidé par un administrateur de base de données de ramener la base de données à cet état (par exemple, en spécifiant cet état par un moment souhaité où la base de données était dans cet état), ces fichiers sont utilisés pour restaurer cet état.
Analyse statique
Les techniques d’analyse statique pour la vérification de logiciels peuvent également être appliquées dans le scénario des langages de requête. En particulier, le cadre d’ interprétation abstraite a été étendu au domaine des langages d’interrogation pour les bases de données relationnelles afin de prendre en charge des techniques d’approximation solides. [34] La sémantique des langages de requête peut être ajustée en fonction d’abstractions appropriées du domaine concret des données. L’abstraction des systèmes de bases de données relationnelles a de nombreuses applications intéressantes, notamment à des fins de sécurité, telles que le contrôle d’accès fin, le tatouage, etc.
Fonctionnalités diverses
Les autres fonctionnalités du SGBD peuvent inclure :
- Journaux de base de données – Cela aide à conserver un historique des fonctions exécutées.
- Composant graphique pour produire des graphiques et des diagrammes, en particulier dans un système d’entrepôt de données.
- Optimiseur de requête – Effectue une optimisation de requête sur chaque requête pour choisir un plan de requête efficace (un ordre partiel (arbre) d’opérations) à exécuter pour calculer le résultat de la requête. Peut être spécifique à un moteur de stockage particulier.
- Outils ou crochets pour la conception de bases de données, la programmation d’applications, la maintenance des programmes d’application, l’analyse et la surveillance des performances des bases de données, la surveillance de la configuration des bases de données, la configuration matérielle du SGBD (un SGBD et la base de données associée peuvent couvrir des ordinateurs, des réseaux et des unités de stockage) et le mappage de base de données associé (en particulier pour un SGBD distribué), surveillance de l’allocation de stockage et de la configuration de la base de données, migration de stockage, etc.
De plus en plus, il y a des appels pour un système unique qui intègre toutes ces fonctionnalités de base dans le même cadre de construction, de test et de déploiement pour la gestion de la base de données et le contrôle des sources. Empruntant à d’autres développements de l’industrie du logiciel, certains commercialisent des offres telles que « DevOps pour base de données ». [35]
Conception et modélisation

La première tâche d’un concepteur de base de données est de produire un modèle de données conceptuel qui reflète la structure des informations à conserver dans la base de données. Une approche courante consiste à développer un modèle entité-relation , souvent à l’aide d’outils de dessin. Une autre approche populaire est le langage de modélisation unifié. Un modèle de données réussi reflétera avec précision l’état possible du monde extérieur modélisé : par exemple, si les gens peuvent avoir plus d’un numéro de téléphone, cela permettra de capturer ces informations. La conception d’un bon modèle conceptuel de données nécessite une bonne compréhension du domaine d’application ; cela implique généralement de poser des questions approfondies sur les éléments qui intéressent une organisation, comme « un client peut-il également être un fournisseur ? » ou « si un produit est vendu avec deux formes d’emballage différentes, s’agit-il du même produit ou de produits différents ? », ou « si un avion vole de New York à Dubaï via Francfort, est-ce un vol ou deux (ou peut-être même trois) ? ». Les réponses à ces questions établissent des définitions de la terminologie utilisée pour les entités (clients, produits, vols,
La production du modèle conceptuel de données implique parfois des apports de processus métier ou l’analyse du flux de travail dans l’organisation. Cela peut aider à déterminer quelles informations sont nécessaires dans la base de données et celles qui peuvent être omises. Par exemple, cela peut aider à décider si la base de données doit contenir des données historiques ainsi que des données actuelles.
Après avoir produit un modèle de données conceptuel qui satisfait les utilisateurs, l’étape suivante consiste à le traduire en un schéma qui implémente les structures de données pertinentes dans la base de données. Ce processus est souvent appelé conception de base de données logique et le résultat est un modèle de données logique exprimé sous la forme d’un schéma. Alors que le modèle de données conceptuel est (en théorie du moins) indépendant du choix de la technologie de base de données, le modèle de données logique sera exprimé en termes d’un modèle de base de données particulier pris en charge par le SGBD choisi. (Les termes modèle de données et modèle de base de données sont souvent utilisés de manière interchangeable, mais dans cet article, nous utilisons le modèle de données pour la conception d’une base de données spécifique et le modèle de base de donnéespour la notation de modélisation utilisée pour exprimer cette conception).
Le modèle de base de données le plus populaire pour les bases de données à usage général est le modèle relationnel, ou plus précisément, le modèle relationnel tel que représenté par le langage SQL. Le processus de création d’une conception de base de données logique à l’aide de ce modèle utilise une approche méthodique connue sous le nom de normalisation . L’objectif de la normalisation est de s’assurer que chaque “fait” élémentaire n’est enregistré qu’à un seul endroit, de sorte que les insertions, les mises à jour et les suppressions conservent automatiquement la cohérence.
La dernière étape de la conception de la base de données consiste à prendre les décisions qui affectent les performances, l’évolutivité, la récupération, la sécurité, etc., qui dépendent du SGBD particulier. Ceci est souvent appelé conception de base de données physique et la sortie est le modèle de données physique . Un objectif clé au cours de cette étape est l’indépendance des données , ce qui signifie que les décisions prises à des fins d’optimisation des performances doivent être invisibles pour les utilisateurs finaux et les applications. Il existe deux types d’indépendance des données : l’indépendance des données physiques et l’indépendance des données logiques. La conception physique est principalement guidée par les exigences de performance et nécessite une bonne connaissance de la charge de travail et des modèles d’accès attendus, ainsi qu’une compréhension approfondie des fonctionnalités offertes par le SGBD choisi.
Un autre aspect de la conception d’une base de données physique est la sécurité. Cela implique à la fois de définir le contrôle d’accès aux objets de la base de données et de définir les niveaux de sécurité et les méthodes pour les données elles-mêmes.
Des modèles
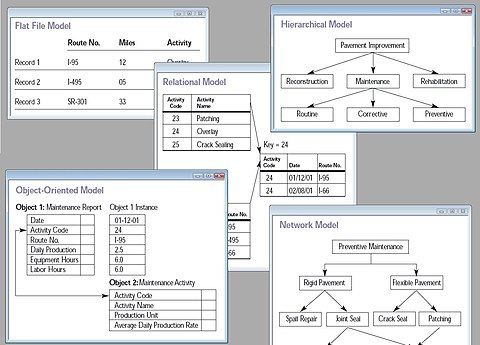 Collage de cinq types de modèles de base de données
Collage de cinq types de modèles de base de données
Un modèle de base de données est un type de modèle de données qui détermine la structure logique d’une base de données et détermine fondamentalement de quelle manière les données peuvent être stockées, organisées et manipulées. L’exemple le plus populaire d’un modèle de base de données est le modèle relationnel (ou l’approximation SQL de relationnel), qui utilise un format basé sur des tables.
Les modèles de données logiques courants pour les bases de données incluent :
- Bases de données de navigation
- Modèle de Base de données hiérarchique
- Modèle de réseau
- Base de données graphique
- Modèle relationnel
- Modèle entité-relation
- Modèle de relation entité-relation amélioré
- Modèle d’objet
- Modèle de document
- Modèle entité-attribut-valeur
- Schéma en étoile
Une base de données objet-relationnelle combine les deux structures liées.
Les modèles de données physiques incluent :
- Indice inversé
- Fichier plat
D’autres modèles incluent:
- Modèle multidimensionnel
- Modèle de tableau
- Modèle multivaleur
Les modèles spécialisés sont optimisés pour des types de données particuliers :
- Base de données XML
- Modèle sémantique
- Magasin de contenu
- Boutique événementielle
- Modèle de série chronologique
Vues externes, conceptuelles et internes
 Vue traditionnelle des données [36]
Vue traditionnelle des données [36]
Un système de gestion de base de données fournit trois vues des données de la base de données :
- Le niveau externe définit comment chaque groupe d’utilisateurs finaux voit l’organisation des données dans la base de données. Une seule base de données peut avoir n’importe quel nombre de vues au niveau externe.
- Le niveau conceptuel unifie les différentes vues externes en une vue globale compatible. [37] Il fournit la synthèse de tous les regards extérieurs. Il est hors de portée des divers utilisateurs finaux de bases de données et intéresse plutôt les développeurs d’applications de bases de données et les administrateurs de bases de données.
- Le niveau interne (ou niveau physique ) est l’organisation interne des données à l’intérieur d’un SGBD. Il est concerné par le coût, les performances, l’évolutivité et d’autres questions opérationnelles. Il traite de la disposition du stockage des données, en utilisant des structures de stockage telles que des index pour améliorer les performances. Parfois, il stocke les données de vues individuelles (vues matérialisées ), calculées à partir de données génériques, si une justification de performance existe pour une telle redondance. Il équilibre toutes les exigences de performance des vues externes, éventuellement contradictoires, dans le but d’optimiser les performances globales de toutes les activités.
Bien qu’il n’y ait généralement qu’une seule vue conceptuelle (ou logique) et physique (ou interne) des données, il peut y avoir un certain nombre de vues externes différentes. Cela permet aux utilisateurs de voir les informations de la base de données d’une manière plus professionnelle plutôt que d’un point de vue technique et de traitement. Par exemple, le service financier d’une entreprise a besoin des détails de paiement de tous les employés dans le cadre des dépenses de l’entreprise, mais n’a pas besoin de détails sur les employés qui sont dans l’intérêt du service des ressources humaines . Ainsi, différents départements ont besoin de différentes vues de la base de données de l’entreprise.
L’architecture de base de données à trois niveaux est liée au concept d’ indépendance des données qui était l’un des principaux moteurs initiaux du modèle relationnel. L’idée est que les modifications apportées à un certain niveau n’affectent pas la vue à un niveau supérieur. Par exemple, les modifications au niveau interne n’affectent pas les programmes d’application écrits à l’aide d’interfaces de niveau conceptuel, ce qui réduit l’impact des modifications physiques apportées pour améliorer les performances.
La vue conceptuelle fournit un niveau d’indirection entre l’interne et l’externe. D’une part, il fournit une vue commune de la base de données, indépendante des différentes structures de vue externes, et d’autre part, il fait abstraction des détails sur la manière dont les données sont stockées ou gérées (niveau interne). En principe, chaque niveau, et même chaque vue externe, peut être présenté par un modèle de données différent. En pratique, un SGBD donné utilise généralement le même modèle de données pour les niveaux externe et conceptuel (par exemple, modèle relationnel). Le niveau interne, qui est caché à l’intérieur du SGBD et dépend de son implémentation, nécessite un niveau de détail différent et utilise ses propres types de types de structure de données.
La séparation des niveaux externe , conceptuel et interne était une caractéristique majeure des implémentations de modèles de bases de données relationnelles qui dominent les bases de données du 21e siècle. [37]
Rechercher
La technologie des bases de données est un sujet de recherche actif depuis les années 1960, tant dans le milieu universitaire que dans les groupes de recherche et développement des entreprises (par exemple IBM Research ). L’activité de recherche comprend la théorie et le développement de prototypes . Les sujets de recherche notables ont inclus les modèles , le concept de transaction atomique, les techniques de contrôle de concurrence associées, les langages de requête et les méthodes d’optimisation des requêtes , RAID , etc.
Le domaine de recherche sur les bases de données compte plusieurs revues académiques dédiées (par exemple, ACM Transactions on Database Systems -TODS, Data and Knowledge Engineering -DKE) et des conférences annuelles (par exemple, ACM SIGMOD , ACM PODS , VLDB , IEEE ICDE).
Voir également
- Comparaison des outils de base de données
- Comparaison des systèmes de gestion de bases de données d’objets
- Comparaison des systèmes de gestion de bases de données relationnelles objet
- Comparaison des systèmes de gestion de bases de données relationnelles
- Hiérarchie des données
- Banque de données
- Magasin de données
- Théorie des bases de données
- Test de base de données
- Architecture centrée sur la base de données
- Base de données de fichiers plats
- INP (base de données)
- Journal de gestion de bases de données
- Ensemble de données axé sur les questions
Remarques
- ^ Cet article cite un temps de développement de 5 ans impliquant 750 personnes pour la seule version 9 de DB2. ( Chong et al. 2007 )
Références
- ^ Ullman & Widom 1997 , p. 1.
- ^ “Mise à jour – Définition de la mise à jour par Merriam-Webster” . merriam-webster.com .
- ^ “Récupération – Définition de la récupération par Merriam-Webster” . merriam-webster.com .
- ^ “Administration – Définition de l’administration par Merriam-Webster” . merriam-webster.com .
- ^ Tsitchizris & Lochovsky 1982 .
- ^ Beynon-Davies 2003 .
- ^ Nelson & Nelson 2001 .
- ^ Bachman 1973 .
- ^ “Indice de base de données TOPDB Top” . pypl.github.io .
- ^ “base de données, n” . ODE en ligne . Presse universitaire d’Oxford. juin 2013 . Consulté le 12 juillet 2013 . (Abonnement requis.)
- ^ IBM Corporation (octobre 2013). « IBM Information Management System (IMS) 13 Transaction and Database Servers offre des performances élevées et un faible coût total de possession » . Consulté le 20 février 2014 .
- ^ Codd 1970 .
- ^ Hershey & Easthope 1972 .
- ^ Nord 2010 .
- ^ Childs 1968a .
- ^ Childs 1968b .
- ^ Manuel de référence du système de gestion de l’information MICRO (version 5.0) , MA Kahn, DL Rumelhart et BL Bronson, octobre 1977, Institut du travail et des relations industrielles (ILIR), Université du Michigan et Wayne State University
- ^ “Chronologie du 30e anniversaire d’Oracle” (PDF) . Récupéré le 23 août 2017 .
- ^ Entretien avec Wayne Ratliff . L’histoire de FoxPro. Consulté le 12/07/2013.
- ^ Développement d’un SGBD orienté objet ; Portland, Oregon, États-Unis ; Pages : 472–482 ; 1986; ISBN 0-89791-204-7
- ^ Graves, Steve. “COTS Databases For Embedded Systems” Archivé le 14/11/2007 à la Wayback Machine , magazine Embedded Computing Design , janvier 2007. Récupéré le 13 août 2008.
- ^ Argumentation en intelligence artificielle par Iyad Rahwan, Guillermo R. Simari
- ^ “Sémantique OWL DL” . Récupéré le 10 décembre 2010 .
- ^ Connolly & Begg 2014 , p. 64.
- ^ Connolly & Begg 2014 , p. 97-102.
- ^ Connolly & Begg 2014 , p. 102.
- ^ Connolly & Begg 2014 , p. 106-113.
- ^ Connolly & Begg 2014 , p. 65.
- ^ Chapitre 2005 .
- ^ “Langage de requête structuré (SQL)” . International Business Machines. 27 octobre 2006 . Récupéré le 10/06/2007 .
- ^ Wagner 2010 .
- ^ Ramalho, JC, Faria, L., Helder, S. et Coutada, M. (2013, 31 décembre). Database Preservation Toolkit : un outil flexible pour normaliser et donner accès aux bases de données. Université du Minho. https://core.ac.uk/display/55635702?source=1&algorithmId=15&similarToDoc=55614406&similarToDocKey=CORE&recSetID=f3ffea4d-1504-45e9-bfd6-a0495f5c8f9c&position=2&recommendation_type=same_repo&otherRecs=55614407,55635702,55607961,55613627,2255664
- ^ Audit continu : théorie et application . David Y. Chan, Victoria Chiu, Miklos A. Vasarhelyi (1ère éd.). Bingley, Royaume-Uni. 2018. ISBN 978-1-78743-413-4. OCLC 1029759767 .{{cite book}}: CS1 maint: others (link)
- ^ Halder & Cortesi 2011 .
- ^ Ben Linders (28 janvier 2016). “Comment l’administration de la base de données s’intègre dans DevOps” . Consulté le 15 avril 2017 .
- ^ itl.nist.gov (1993) Définition d’intégration pour la modélisation de l’information (IDEFIX) Archivé le 03/12/2013 à la Wayback Machine . 21 décembre 1993.
- ^ une date b 2003 , pp. 31–32.
Sources
- Bachman, Charles W. (1973). “Le programmeur comme navigateur” . Communications de l’ACM . 16 (11): 653–658. doi : 10.1145/355611.362534 .
- Beynon-Davies, Paul (2003). Systèmes de base de données (3e éd.). Palgrave Macmillan. ISBN 978-1403916013.
- Chapple, Mike (2005). “Bases SQL” . Bases de données . À propos.com. Archivé de l’original le 22 février 2009 . Récupéré le 28 janvier 2009 .
- Childs, David L. (1968a). “Description d’une structure de données ensembliste” (PDF) . Projet CONCOMP (Recherche sur l’utilisation conversationnelle des ordinateurs) . Vol. Rapport technique 3. Université du Michigan.
- Childs, David L. (1968b). “Faisabilité d’une structure de données ensembliste: une structure générale basée sur une définition reconstituée” (PDF) . Projet CONCOMP (Recherche sur l’utilisation conversationnelle des ordinateurs) . Vol. Rapport technique 6. Université du Michigan.
- Chong, Raul F.; Wang, Xiaomei ; Merde, Michael ; Neige, Dwaine R. (2007). “Introduction à DB2” . Comprendre DB2 : Apprendre visuellement avec des exemples (2e éd.). ISBN 978-0131580183. Récupéré le 17 mars 2013 .
- Codd, Edgar F. (1970). “Un modèle relationnel de données pour les grandes banques de données partagées” (PDF) . Communications de l’ACM . 13 (6): 377–387. doi : 10.1145/362384.362685 . S2CID 207549016 .
- Connolly, Thomas M.; Begg, Carolyn E. (2014). Systèmes de base de données – Une approche pratique de la mise en œuvre et de la gestion de la conception (6e éd.). Person. ISBN 978-1292061184.
- Date, CJ (2003). Une introduction aux systèmes de base de données (8e éd.). Person. ISBN 978-0321197849.
- Halder, Raju ; Cortesi, Agostino (2011). “Interprétation abstraite des langages de requête de base de données” (PDF) . Langages informatiques, systèmes et structures . 38 (2): 123–157. doi : 10.1016/j.cl.2011.10.004 . ISSN 1477-8424 .
- Hershey, William; Easthope, Carol (1972). Une structure de données théorique ensembliste et un langage de récupération . Spring Joint Computer Conference, mai 1972. ACM SIGIR Forum . Vol. 7, non. 4. p. 45–55. doi : 10.1145/1095495.1095500 .
- Nelson, Anne Fulcher; Nelson, William Harris Morehead (2001). Construire le commerce électronique : avec les constructions de bases de données Web . Prentice Hall. ISBN 978-0201741308.
- Nord, Ken (10 mars 2010). “Ensembles, modèles de données et indépendance des données” . Dr Dobb’s . Archivé de l’original le 24 octobre 2010.
- Tsitchizris, Dionysios C.; En ligneLochovsky, Fred H. (1982). Modèles de données . Prentice Hall. ISBN 978-0131964280.
- Ullman, Jeffrey; Widom, Jennifer (1997). Un premier cours sur les systèmes de bases de données . Prentice Hall. ISBN 978-0138613372.
- Wagner, Michael (2010), SQL/XML:2006 – Evaluierung der Standardkonformität ausgewählter Datenbanksysteme , Diplomica Verlag, ISBN 978-3836696098
Lectures complémentaires
- Ling Liu et Tamer M. Özsu (Eds.) (2009). ” Encyclopédie des systèmes de bases de données , 4100 p. 60 ill. ISBN 978-0-387-49616-0 .
- Gray, J. et Reuter, A. Transaction Processing: Concepts and Techniques , 1ère édition, Morgan Kaufmann Publishers, 1992.
- Kroenke, David M. et David J. Auer. Concepts de base de données. 3e éd. New York : Apprenti, 2007.
- Raghu Ramakrishnan et Johannes Gehrke , Systèmes de gestion de bases de données
- Abraham Silberschatz , Henry F. Korth , S. Sudarshan, Concepts de système de base de données
- Lightstone, S.; Teorey, T.; En ligneNadeau, T. (2007). Conception de bases de données physiques : le guide du professionnel des bases de données pour exploiter les index, les vues, le stockage, etc. Presse Morgan Kaufmann. ISBN 978-0-12-369389-1.
- Teorey, T.; Lightstone, S. et Nadeau, T. Database Modeling & Design: Logical Design , 4e édition, Morgan Kaufmann Press, 2005. ISBN 0-12-685352-5
Liens externes
Base de donnéesdans les projets frères de Wikipédia
-
![]()
![]() Définitions du Wiktionnaire
Définitions du Wiktionnaire -
![]()
![]() Médias de Commons
Médias de Commons -
![]()
![]() Nouvelles de Wikinews
Nouvelles de Wikinews -
![]()
![]() Citations de Wikiquote
Citations de Wikiquote -
![]()
![]() Textes de Wikisource
Textes de Wikisource -
![]()
![]() Manuels de Wikibooks
Manuels de Wikibooks -
![]()
![]() Ressources de Wikiversité
Ressources de Wikiversité
- Extension de fichier DB – informations sur les fichiers avec l’extension DB