Réseau neuronal récurrent
Un réseau neuronal récurrent ( RNN ) est une classe de réseaux neuronaux artificiels où les connexions entre les nœuds forment un graphe orienté ou non orienté le long d’une séquence temporelle. Cela lui permet de présenter un comportement dynamique temporel. Dérivés des réseaux de neurones à anticipation , les RNN peuvent utiliser leur état interne (mémoire) pour traiter des séquences d’entrées de longueur variable. [1] [2] [3] Cela les rend applicables à des tâches telles que la reconnaissance d’écriture manuscrite non segmentée [4] ou la reconnaissance vocale . [5] [6] Les Réseaux de neurones récurrents sont théoriquementTuring est complet et peut exécuter des programmes arbitraires pour traiter des séquences arbitraires d’entrées. [7]
Le terme “réseau neuronal récurrent” est utilisé pour désigner la classe des réseaux à réponse impulsionnelle infinie , tandis que “réseau neuronal convolutif” fait référence à la classe des réponses impulsionnelles finies . Les deux classes de réseaux présentent un comportement dynamique temporel . [8] Un réseau récurrent à impulsions finies est un graphe acyclique dirigé qui peut être déroulé et remplacé par un réseau neuronal strictement prédictif, tandis qu’un réseau récurrent à impulsions infinies est un graphe cyclique dirigé qui ne peut pas être déroulé.
Les réseaux récurrents à impulsions finies et à impulsions infinies peuvent avoir des états stockés supplémentaires, et le stockage peut être sous le contrôle direct du réseau neuronal. Le stockage peut également être remplacé par un autre réseau ou graphe s’il intègre des temporisations ou comporte des boucles de rétroaction. Ces états contrôlés sont appelés état fermé ou mémoire fermée et font partie des réseaux de mémoire à long terme (LSTM) et des unités récurrentes fermées . Ceci est également appelé réseau de neurones de rétroaction (FNN).
Histoire
Les Réseaux de neurones récurrents étaient basés sur les travaux de David Rumelhart en 1986. [9] Les réseaux de Hopfield – un type particulier de RNN – ont été (re-)découverts par John Hopfield en 1982. En 1993, un système de compression d’histoire neuronale a résolu un “très Deep Learning” tâche qui nécessitait plus de 1000 couches successives dans un RNN déroulées dans le temps. [dix]
LSTM
Les réseaux de mémoire longue à court terme (LSTM) ont été inventés par Hochreiter et Schmidhuber en 1997 et ont établi des records de précision dans de multiples domaines d’application. [11]
Vers 2007, LSTM a commencé à révolutionner la reconnaissance vocale , surpassant les modèles traditionnels dans certaines applications vocales. [12] En 2009, un réseau LSTM formé à la Classification temporelle connexionniste (CTC) a été le premier RNN à remporter des concours de reconnaissance de formes lorsqu’il a remporté plusieurs concours de reconnaissance d’écriture manuscrite connectée . [13] [14] En 2014, la société chinoise Baidu a utilisé des RNN formés par CTC pour casser l’ensemble de données de reconnaissance vocale 2S09 Switchboard Hub5’00 [15] sans utiliser de méthodes traditionnelles de traitement de la parole. [16]
LSTM a également amélioré la reconnaissance vocale à grand vocabulaire [5] [6] et la synthèse vocale [17] et a été utilisé dans Google Android . [13] [18] En 2015, la reconnaissance vocale de Google aurait connu un saut de performance spectaculaire de 49 % [ citation nécessaire ] grâce au LSTM formé par le CTC. [19]
LSTM a battu des records pour l’amélioration de la traduction automatique , [20] la Modélisation du langage [21] et le traitement du langage multilingue. [22] LSTM combiné avec des réseaux de neurones convolutifs (CNN) a amélioré le sous- titrage automatique des images . [23]
Architectures
Les RNN existent en de nombreuses variantes.
Entièrement récurrent
 Réseau neuronal récurrent de base compressé (à gauche) et déplié (à droite).
Réseau neuronal récurrent de base compressé (à gauche) et déplié (à droite).
Les réseaux de neurones entièrement récurrents (FRNN) connectent les sorties de tous les neurones aux entrées de tous les neurones. Il s’agit de la topologie de réseau neuronal la plus générale, car toutes les autres topologies peuvent être représentées en définissant certains poids de connexion sur zéro pour simuler le manque de connexions entre ces neurones. L’illustration de droite peut être trompeuse pour beaucoup car les topologies pratiques des réseaux de neurones sont souvent organisées en “couches” et le dessin donne cette apparence. Cependant, ce qui semble être des couches sont, en fait, différentes étapes dans le temps du même réseau de neurones entièrement récurrent. L’élément le plus à gauche de l’illustration montre les connexions récurrentes sous la forme d’un arc étiqueté « v ». Il est “déplié” dans le temps pour produire l’apparence de couches .
Réseaux Elman et réseaux Jordan
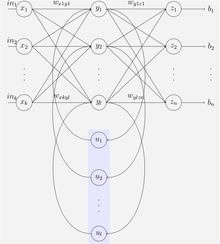 Le réseau Elman
Le réseau Elman
Un réseau Elman est un réseau à trois couches (organisé horizontalement en x , y et z dans l’illustration) avec l’ajout d’un ensemble d’unités de contexte ( u dans l’illustration). La couche intermédiaire (cachée) est connectée à ces unités de contexte fixées avec un poids de un. [24] A chaque pas de temps, l’entrée est avancée et une règle d’apprentissageest appliqué. Les back-connexions fixes enregistrent une copie des valeurs précédentes des unités cachées dans les unités de contexte (puisqu’elles se propagent sur les connexions avant que la règle d’apprentissage ne soit appliquée). Ainsi, le réseau peut maintenir une sorte d’état, lui permettant d’effectuer des tâches telles que la prédiction de séquence qui dépassent la puissance d’un perceptron multicouche standard .
Les réseaux Jordan sont similaires aux réseaux Elman. Les unités de contexte sont alimentées à partir de la couche de sortie au lieu de la couche masquée. Les unités de contexte d’un réseau jordanien sont également appelées couche d’état. Ils ont une connexion récurrente à eux-mêmes. [24]
Les réseaux Elman et Jordan sont également connus sous le nom de “Réseaux récurrents simples” (SRN).
Réseau Elman [25] h t = σ h ( O h x t + U h h t − 1 + b h ) y t = σ y ( W y h t + b y ) {displaystyle {begin{aligned}h_{t}&=sigma _{h}(W_{h}x_{t}+U_{h}h_{t-1}+b_{h})\y_ {t}&=sigma _{y}(W_{y}h_{t}+b_{y})end{aligné}}} 

Variables et fonctions
- x t {displaystyle x_{t}}
: vecteur d’entrée
- h t {displaystyle h_{t}}
: vecteur de calque caché
- y t {displaystyle y_{t}}
: vecteur de sortie
- W {displaystyle W}
, U {displaystyle U}
et b {displaystyle b}
: matrices de paramètres et vecteur
- σ h {displaystyle sigma _{h}}
et σ y {displaystyle sigma _{y}}
: Fonctions d’activation








Hopfield
Le réseau Hopfield est un RNN dans lequel toutes les connexions entre les couches sont de taille égale. Il nécessite des entrées fixes et n’est donc pas un RNN général, car il ne traite pas de séquences de motifs. Cependant, il garantit qu’il convergera. Si les connexions sont formées à l’aide de l’apprentissage Hebbian, le réseau Hopfield peut fonctionner comme une mémoire adressable par le contenu robuste , résistante à l’altération de la connexion.
Mémoire associative bidirectionnelle
Introduit par Bart Kosko, [27] un réseau de mémoire associative bidirectionnelle (BAM) est une variante d’un réseau Hopfield qui stocke les données associatives sous forme de vecteur. La bi-directionnalité vient du passage d’informations à travers une matrice et sa transposée . Typiquement, le codage bipolaire est préféré au codage binaire des paires associatives. Récemment, les modèles BAM stochastiques utilisant le pas de Markov ont été optimisés pour une stabilité accrue du réseau et une pertinence pour les applications du monde réel. [28]
Un réseau BAM comporte deux couches, chacune pouvant être pilotée en tant qu’entrée pour rappeler une association et produire une sortie sur l’autre couche. [29]
État d’écho
Le réseau d’état d’écho (ESN) a une couche cachée aléatoire peu connectée. Les poids des neurones de sortie sont la seule partie du réseau qui peut changer (être entraînée). Les ESN sont bons pour reproduire certaines séries chronologiques . [30] Une variante pour stimuler les neurones est connue sous le nom de machine à état liquide . [31]
Indépendamment RNN (IndRNN)
Le réseau de neurones indépendamment récurrent (IndRNN) [32] résout les problèmes de disparition et d’explosion de gradient dans le RNN traditionnel entièrement connecté. Chaque neurone d’une couche ne reçoit que son propre état passé comme information de contexte (au lieu d’une connectivité complète à tous les autres neurones de cette couche) et donc les neurones sont indépendants de l’historique des autres. La rétropropagation du gradient peut être régulée pour éviter que le gradient ne disparaisse et n’explose afin de conserver une mémoire à long ou à court terme. Les informations inter-neurones sont explorées dans les couches suivantes. IndRNN peut être formé de manière robuste avec les fonctions non linéaires non saturées telles que ReLU. En utilisant des connexions de saut, des réseaux profonds peuvent être formés.
Récursif
Un réseau de neurones récursif [33] est créé en appliquant le même ensemble de poids de manière récursive sur une structure de type graphe différentiable en traversant la structure dans l’ ordre topologique . Ces réseaux sont généralement également entraînés par le mode inverse de différenciation automatique . [34] [35] Ils peuvent traiter des représentations distribuées de structure, telles que des termes logiques . Un cas particulier des réseaux de neurones récursifs est le RNN dont la structure correspond à une chaîne linéaire. Les réseaux de neurones récursifs ont été appliqués au traitement du langage naturel . [36]Le réseau de tenseurs neuronaux récursifs utilise une fonction de composition basée sur les tenseurs pour tous les nœuds de l’arbre. [37]
Compresseur d’histoire neuronale
Le compresseur d’historique neuronal est une pile non supervisée de RNN. [38] Au niveau de l’entrée, il apprend à prédire sa prochaine entrée à partir des entrées précédentes. Seules les entrées imprévisibles de certains RNN dans la hiérarchie deviennent des entrées du RNN de niveau supérieur suivant, qui ne recalcule donc que rarement son état interne. Chaque RNN de niveau supérieur étudie ainsi une représentation compressée des informations dans le RNN inférieur. Ceci est fait de sorte que la séquence d’entrée puisse être précisément reconstruite à partir de la représentation au niveau le plus élevé.
Le système minimise efficacement la longueur de la description ou le logarithme négatif de la probabilité des données. [39] Compte tenu de la grande prévisibilité apprenable dans la séquence de données entrantes, le RNN de plus haut niveau peut utiliser l’apprentissage supervisé pour classer facilement même les séquences profondes avec de longs intervalles entre les événements importants.
Il est possible de distiller la hiérarchie RNN en deux RNN : le chunker “conscient” (niveau supérieur) et l’automate “subconscient” (niveau inférieur). [38] Une fois que le chunker a appris à prédire et à compresser les entrées qui sont imprévisibles par l’automatiseur, alors l’automatizer peut être forcé dans la phase d’apprentissage suivante à prédire ou imiter à travers des unités supplémentaires les unités cachées du chunker changeant plus lentement. Cela permet à l’automatiseur d’apprendre facilement des mémoires appropriées, qui changent rarement sur de longs intervalles. À son tour, cela aide l’automatiseur à rendre prévisibles bon nombre de ses entrées autrefois imprévisibles, de sorte que le fragmenteur peut se concentrer sur les événements imprévisibles restants. [38]
Un modèle génératif a partiellement surmonté le problème du gradient de fuite [40] de la différenciation automatique ou de la rétropropagation dans les réseaux de neurones en 1992. En 1993, un tel système a résolu une tâche de “Very Deep Learning” qui nécessitait plus de 1000 couches successives dans un RNN déployé dans le temps . [dix]
RNN de second ordre
Les RNN de second ordre utilisent des poids d’ordre supérieur w i j k {displaystyle w{}_{ijk}} 

Longue mémoire à court terme
 Unité de mémoire longue à court terme
Unité de mémoire longue à court terme
La mémoire longue à court terme (LSTM) est un système d’apprentissage en profondeur qui évite le problème du gradient de fuite . LSTM est normalement complété par des portes récurrentes appelées “forget gates”. [43] LSTM empêche les erreurs rétropropagées de disparaître ou d’exploser. [40] Au lieu de cela, les erreurs peuvent remonter à travers un nombre illimité de couches virtuelles déployées dans l’espace. Autrement dit, LSTM peut apprendre des tâches [13] qui nécessitent des souvenirs d’événements qui se sont produits des milliers, voire des millions de pas de temps discrets plus tôt. Des topologies de type LSTM spécifiques à un problème peuvent être développées. [44] LSTM fonctionne même avec de longs délais entre des événements significatifs et peut gérer des signaux qui mélangent des composants basse et haute fréquence.
De nombreuses applications utilisent des piles de RNN LSTM [45] et les entraînent par Classification temporelle connexionniste (CTC) [46] pour trouver une matrice de pondération RNN qui maximise la probabilité des séquences d’étiquettes dans un ensemble d’apprentissage, compte tenu des séquences d’entrée correspondantes. CTC atteint à la fois l’alignement et la reconnaissance.
LSTM peut apprendre à reconnaître les Langages contextuels contrairement aux modèles précédents basés sur des modèles de Markov cachés (HMM) et des concepts similaires. [47]
Unité récurrente fermée
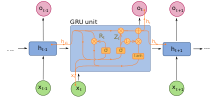 Unité récurrente fermée
Unité récurrente fermée
Les unités récurrentes fermées (GRU) sont un mécanisme de déclenchement dans les Réseaux de neurones récurrents introduits en 2014. Ils sont utilisés dans leur forme complète et plusieurs variantes simplifiées. [48] [49] Leur performance sur la modélisation de la musique polyphonique et la modélisation du signal vocal s’est avérée similaire à celle de la mémoire à court terme. [50] Ils ont moins de paramètres que LSTM, car ils n’ont pas de porte de sortie. [51]
Bidirectionnel
Les RNN bidirectionnels utilisent une séquence finie pour prédire ou étiqueter chaque élément de la séquence en fonction des contextes passés et futurs de l’élément. Cela se fait en concaténant les sorties de deux RNN, l’un traitant la séquence de gauche à droite, l’autre de droite à gauche. Les sorties combinées sont les prédictions des signaux cibles donnés par l’enseignant. Cette technique s’est avérée particulièrement utile lorsqu’elle est combinée avec les RNN LSTM. [52] [53]
Temps continu
Un réseau neuronal récurrent en temps continu (CTRNN) utilise un système d’ Équations différentielles ordinaires pour modéliser les effets sur un neurone des entrées entrantes.
Pour un neurone i {displaystyle i} 

τ i y ̇ i = − y i + ∑ j = 1 n w j i σ ( y j − Θ j ) + I i ( t ) {displaystyle tau _{i}{dot {y}}_{i}=-y_{i}+sum _{j=1}^{n}w_{ji}sigma (y_{j} -Thêta _{j})+I_{i}(t)} 
Où:
- τ i {displaystyle tau _{i}}
: Constante de temps du nœud post- synaptique
- y i {displaystyle y_{i}}
: Activation du nœud post-synaptique
- y ̇ i {displaystyle {point {y}}_{i}}
: Taux de changement d’activation du nœud post-synaptique
- w j i {displaystyle w{}_{ji}}
: Poids de la connexion du nœud pré-post-synaptique
- σ ( x ) {displaystyle sigma (x)}
: Sigmoïde de x ex. σ ( x ) = 1 / ( 1 + e − x ) {displaystyle sigma (x)=1/(1+e^{-x})}
.
- y j {displaystyle y_{j}}
: Activation du nœud présynaptique
- Θ j {displaystyle Thêta _{j}}
: Biais du nœud présynaptique
- I i ( t ) {displaystyle I_{i}(t)}
: Entrée (le cas échéant) au nœud








Les CTRNN ont été appliqués à la robotique évolutive où ils ont été utilisés pour traiter la vision, [54] la coopération, [55] et le comportement cognitif minimal. [56]
Notez que, par le Théorème d’échantillonnage de Shannon , les Réseaux de neurones récurrents à temps discret peuvent être considérés comme des Réseaux de neurones récurrents à temps continu où les équations différentielles se sont transformées en équations aux différences équivalentes . [57] Cette transformation peut être considérée comme se produisant après les fonctions d’activation des nœuds post-synaptiques y i ( t ) {displaystyle y_{i}(t)} 
Hiérarchique
| Apprendre encore plus Cette section a besoin d’être agrandie . Vous pouvez aider en y ajoutant . ( août 2019 ) |
Les RNN hiérarchiques connectent leurs neurones de différentes manières pour décomposer le comportement hiérarchique en sous-programmes utiles. [38] [58] De telles structures hiérarchiques de la cognition sont présentes dans les théories de la mémoire présentées par le philosophe Henri Bergson , dont les vues philosophiques ont inspiré des modèles hiérarchiques. [59]
Réseau perceptron multicouche récurrent
Généralement, un réseau de perceptron multicouche récurrent (RMLP) se compose de sous-réseaux en cascade, chacun contenant plusieurs couches de nœuds. Chacun de ces sous-réseaux est en aval, à l’exception de la dernière couche, qui peut avoir des connexions de retour. Chacun de ces sous-réseaux est connecté uniquement par des connexions en aval. [60]
Modèle à plusieurs échelles de temps
Un réseau neuronal récurrent à plusieurs échelles de temps (MTRNN) est un modèle informatique basé sur les neurones qui peut simuler la hiérarchie fonctionnelle du cerveau par le biais d’une auto-organisation qui dépend de la connexion spatiale entre les neurones et de types distincts d’activités neuronales, chacune avec des propriétés temporelles distinctes. [61] [62] Avec des activités neuronales aussi variées, des séquences continues de tout ensemble de comportements sont segmentées en primitives réutilisables, qui à leur tour sont intégrées de manière flexible dans divers comportements séquentiels. L’approbation biologique d’un tel type de hiérarchie a été discutée dans la théorie de la mémoire-prédiction de la fonction cérébrale par Hawkins dans son livre On Intelligence . [ citation nécessaire ]Une telle hiérarchie s’accorde également avec les théories de la mémoire posées par le philosophe Henri Bergson , qui ont été incorporées dans un modèle MTRNN. [59] [63]
Machines de Turing neurales
Les machines neuronales de Turing (NTM) sont une méthode d’extension des Réseaux de neurones récurrents en les couplant à des ressources de mémoire externes avec lesquelles ils peuvent interagir par des processus attentionnels . Le système combiné est analogue à une machine de Turing ou à une architecture de Von Neumann mais est différenciable de bout en bout, ce qui lui permet d’être entraîné efficacement avec une descente de gradient . [64]
Ordinateur neuronal différentiable
Les ordinateurs neuronaux différentiables (DNC) sont une extension des machines neuronales de Turing, permettant l’utilisation de quantités floues de chaque adresse mémoire et d’un enregistrement de la chronologie.
Automates de refoulement de réseau de neurones
Les automates de refoulement de réseau de neurones (NNPDA) sont similaires aux NTM, mais les bandes sont remplacées par des piles analogiques différentiables et entraînées. De cette façon, ils sont similaires en complexité aux reconnaisseurs de grammaires sans contexte (CFG). [65]
Réseaux memristifs
Greg Snider de HP Labs décrit un système d’informatique corticale avec des nanodispositifs memristifs. [66] Les Memristors (résistances à mémoire) sont mis en œuvre par des matériaux à couche mince dans lesquels la résistance est électriquement accordée via le transport d’ions ou de lacunes d’oxygène dans le film. Le projet SyNAPSE de la DARPA a financé IBM Research et HP Labs, en collaboration avec le Département des systèmes cognitifs et neuronaux (CNS) de l’Université de Boston, pour développer des architectures neuromorphiques qui peuvent être basées sur des systèmes memristifs. Les réseaux memristifs sont un type particulier de réseau neuronal physiquequi ont des propriétés très similaires aux réseaux de (Little-)Hopfield, car ils ont une dynamique continue, ont une capacité de mémoire limitée et ils se relaxent naturellement via la minimisation d’une fonction qui est asymptotique au modèle d’Ising. En ce sens, la dynamique d’un circuit memristif a l’avantage par rapport à un réseau Résistance-Condensateur d’avoir un comportement non linéaire plus intéressant. De ce point de vue, l’ingénierie d’un réseau memristif analogique représente un type particulier d’ ingénierie neuromorphique dans lequel le comportement du dispositif dépend du câblage du circuit ou de la topologie. [67] [68]
Formation
Descente graduelle
La descente de gradient est un algorithme d’ optimisation itératif du premier ordre pour trouver le minimum d’une fonction. Dans les réseaux de neurones, il peut être utilisé pour minimiser le terme d’erreur en modifiant chaque poids proportionnellement à la dérivée de l’erreur par rapport à ce poids, à condition que les fonctions d’ activation non linéaires soient différentiables . Diverses méthodes pour ce faire ont été développées dans les années 1980 et au début des années 1990 par Werbos , Williams , Robinson , Schmidhuber , Hochreiter , Pearlmutter et d’autres.
La méthode standard est appelée ” rétropropagation dans le temps ” ou BPTT, et est une généralisation de la rétropropagation pour les réseaux à anticipation. [69] [70] Comme cette méthode, c’est une instance de différenciation automatique dans le mode d’accumulation inverse du principe minimum de Pontryagin . Une variante en ligne plus coûteuse en calcul est appelée “Apprentissage récurrent en temps réel” ou RTRL, [71] [72] qui est une instance de différenciation automatique dans le mode d’accumulation avant avec des vecteurs tangents empilés. Contrairement à BPTT, cet algorithme est local dans le temps mais pas local dans l’espace.
Dans ce contexte, local dans l’espace signifie que le vecteur de poids d’une unité peut être mis à jour en utilisant uniquement les informations stockées dans les unités connectées et l’unité elle-même, de sorte que la complexité de mise à jour d’une seule unité est linéaire dans la dimensionnalité du vecteur de poids. Local dans le temps signifie que les mises à jour ont lieu en continu (en ligne) et ne dépendent que du pas de temps le plus récent plutôt que de plusieurs pas de temps dans un horizon temporel donné comme dans BPTT. Les réseaux de neurones biologiques semblent être locaux à la fois dans le temps et dans l’espace. [73] [74]
Pour le calcul récursif des dérivées partielles, RTRL a une complexité temporelle de O (nombre de cachés x nombre de poids) par pas de temps pour le calcul des matrices jacobiennes , tandis que BPTT ne prend que O (nombre de poids) par pas de temps, au prix de stocker toutes les activations vers l’avant dans l’horizon temporel donné. [75] Un hybride en ligne entre BPTT et RTRL avec la complexité intermédiaire existe, [76] [77] avec des variantes pour le temps continu. [78]
Un problème majeur avec la descente de gradient pour les architectures RNN standard est que les gradients d’erreur disparaissent rapidement de manière exponentielle avec la taille du décalage temporel entre les événements importants. [40] [79] LSTM combiné avec une méthode d’apprentissage hybride BPTT/RTRL tente de surmonter ces problèmes. [11] Ce problème est également résolu dans le réseau neuronal indépendamment récurrent (IndRNN) [32] en réduisant le contexte d’un neurone à son propre état passé et les informations inter-neurones peuvent ensuite être explorées dans les couches suivantes. Des souvenirs de différentes gammes, y compris la mémoire à long terme, peuvent être appris sans le problème de disparition et d’explosion du gradient.
L’algorithme en ligne appelé rétropropagation causale récursive (CRBP), implémente et combine les paradigmes BPTT et RTRL pour les réseaux localement récurrents. [80] Il fonctionne avec les réseaux récurrents locaux les plus généraux. L’algorithme CRBP peut minimiser le terme d’erreur global. Ce fait améliore la stabilité de l’algorithme, offrant une vue unificatrice sur les techniques de calcul de gradient pour les réseaux récurrents avec rétroaction locale.
Une approche du calcul des informations de gradient dans les RNN avec des architectures arbitraires est basée sur la dérivation schématique des graphes de flux de signaux. [81] Il utilise l’algorithme batch BPTT, basé sur le théorème de Lee pour les calculs de sensibilité du réseau. [82] Il a été proposé par Wan et Beaufays, tandis que sa version en ligne rapide a été proposée par Campolucci, Uncini et Piazza. [82]
Méthodes d’optimisation globale
La formation des poids dans un réseau de neurones peut être modélisée comme un problème d’optimisation globale non linéaire . Une fonction cible peut être formée pour évaluer l’adéquation ou l’erreur d’un vecteur de pondération particulier comme suit : Tout d’abord, les pondérations dans le réseau sont définies en fonction du vecteur de pondération. Ensuite, le réseau est évalué par rapport à la séquence d’apprentissage. En règle générale, la différence somme-carré entre les prédictions et les valeurs cibles spécifiées dans la séquence d’apprentissage est utilisée pour représenter l’erreur du vecteur de pondération actuel. Des techniques arbitraires d’optimisation globale peuvent alors être utilisées pour minimiser cette fonction cible.
La méthode d’optimisation globale la plus courante pour la formation des RNN est les algorithmes génétiques , en particulier dans les réseaux non structurés. [83] [84] [85]
Initialement, l’algorithme génétique est codé avec les poids du réseau neuronal d’une manière prédéfinie où un gène dans le chromosome représente un lien de poids. L’ensemble du réseau est représenté par un seul chromosome. La fonction de fitness est évaluée comme suit :
- Chaque poids codé dans le chromosome est attribué au lien de poids respectif du réseau.
- L’ensemble d’apprentissage est présenté au réseau qui propage les signaux d’entrée vers l’avant.
- L’erreur quadratique moyenne est renvoyée à la fonction de fitness.
- Cette fonction pilote le processus de sélection génétique.
De nombreux chromosomes composent la population; par conséquent, de nombreux réseaux de neurones différents évoluent jusqu’à ce qu’un critère d’arrêt soit satisfait. Un schéma d’arrêt courant est :
- Lorsque le réseau de neurones a appris un certain pourcentage des données d’entraînement ou
- Lorsque la valeur minimale de l’erreur quadratique moyenne est satisfaite ou
- Lorsque le nombre maximal de générations d’apprentissage a été atteint.
Le critère d’arrêt est évalué par la fonction de fitness car il obtient l’inverse de l’erreur quadratique moyenne de chaque réseau pendant l’entraînement. Par conséquent, l’objectif de l’algorithme génétique est de maximiser la fonction de fitness, en réduisant l’erreur quadratique moyenne.
D’autres techniques d’optimisation globale (et/ou évolutive) peuvent être utilisées pour rechercher un bon ensemble de poids, comme le recuit simulé ou l’optimisation par essaim de particules .
Domaines et modèles associés
Les RNN peuvent se comporter de manière chaotique . Dans de tels cas, la théorie des systèmes dynamiques peut être utilisée pour l’analyse.
Ce sont en fait des réseaux de neurones récursifs avec une structure particulière : celle d’une chaîne linéaire. Alors que les réseaux de neurones récursifs fonctionnent sur n’importe quelle structure hiérarchique, combinant des représentations enfants dans des représentations parentes, les Réseaux de neurones récurrents fonctionnent sur la progression linéaire du temps, combinant le pas de temps précédent et une représentation cachée dans la représentation du pas de temps actuel.
En particulier, les RNN peuvent apparaître comme des versions non linéaires de filtres à réponse impulsionnelle finie et à réponse impulsionnelle infinie , ainsi que comme un modèle exogène autorégressif non linéaire (NARX). [86]
Bibliothèques
- Apache Singa
- Caffe : Créé par le Berkeley Vision and Learning Center (BVLC). Il prend en charge à la fois le CPU et le GPU. Développé en C++ et possède des wrappers Python et MATLAB .
- Chainer : La première bibliothèque d’apprentissage en profondeur stable qui prend en charge les réseaux de neurones dynamiques définis par exécution. Entièrement en Python, support de production pour CPU, GPU, formation distribuée.
- Deeplearning4j : Deep learning en Java et Scala sur Spark multi-GPU . Une bibliothèque d’apprentissage en profondeur à usage général pour la pile de production JVM exécutée sur un moteur de calcul scientifique C++ . Permet la création de calques personnalisés. S’intègre à Hadoop et Kafka .
- Flux : comprend des interfaces pour les RNN, y compris les GRU et les LSTM, écrits en Julia .
- Keras : API de haut niveau et facile à utiliser, fournissant un wrapper à de nombreuses autres bibliothèques d’apprentissage en profondeur.
- Boîte à outils cognitive Microsoft
- MXNet : un cadre moderne d’apprentissage en profondeur open source utilisé pour former et déployer des réseaux de neurones profonds.
- PyTorch : Tenseurs et réseaux de neurones dynamiques en Python avec une forte accélération GPU.
- TensorFlow : bibliothèque de type Theano sous licence Apache 2.0 avec prise en charge du CPU, du GPU et du TPU propriétaire de Google , [87] mobile
- Theano : La bibliothèque de deep learning de référence pour Python avec une API largement compatible avec la populaire bibliothèque NumPy . Permet à l’utilisateur d’écrire des expressions mathématiques symboliques, puis génère automatiquement leurs dérivées, évitant à l’utilisateur d’avoir à coder des gradients ou une rétropropagation. Ces expressions symboliques sont automatiquement compilées en code CUDA pour une implémentation rapide sur le GPU.
- Torch ( www.torch.ch ): Un cadre de calcul scientifique avec un large support pour les algorithmes d’apprentissage automatique, écrit en C et lua . L’auteur principal est Ronan Collobert, et il est maintenant utilisé sur Facebook AI Research et Twitter.
Applications
Les applications des Réseaux de neurones récurrents comprennent :
- Traduction automatique [20]
- Commande de robots [88]
- Prédiction de séries chronologiques [89] [90] [91]
- Reconnaissance vocale [92] [93] [94]
- Synthèse vocale [95]
- Interfaces cerveau-ordinateur [96]
- Détection d’anomalies de séries chronologiques [97]
- Apprentissage du rythme [98]
- Composition musicale [99]
- Apprentissage de la grammaire [100] [101] [102]
- Reconnaissance de l’écriture manuscrite [103] [104]
- Reconnaissance de l’action humaine [105]
- Détection d’homologie protéique [106]
- Prédire la localisation subcellulaire des protéines [53]
- Plusieurs tâches de prédiction dans le domaine de la gestion des processus métier [107]
- Prédiction dans les parcours de soins [108]
Références
- ^ Dupond, Samuel (2019). “Un examen approfondi de l’avancée actuelle des structures de réseaux de neurones” . Examens annuels sous contrôle . 14 : 200–230.
- ^ Abiodun, Oludare Isaac; Jantan, Aman; Omolara, Abiodun Esther ; Dada, Kemi Victoria ; Mohamed, Nachaat Abdelatif; Arshad, Humaira (2018-11-01). “État de l’art dans les applications de réseaux de neurones artificiels : une enquête” . Héliyon . 4 (11) : e00938. doi : 10.1016/j.heliyon.2018.e00938 . ISSN 2405-8440 . PMC 6260436 . PMID 30519653 .
- ^ Tealab, Ahmed (2018-12-01). “Prévision de séries chronologiques à l’aide de méthodologies de réseaux de neurones artificiels : une revue systématique” . Future Computing and Informatics Journal . 3 (2): 334–340. doi : 10.1016/j.fcij.2018.10.003 . ISSN 2314-7288 .
- ^ Graves, Alex ; Liwicki, Marcus; Fernández, Santiago ; Bertolami, Romain ; Bunke, Horst; Schmidhuber, Jürgen (2009). “Un nouveau système connexionniste pour une meilleure reconnaissance de l’écriture manuscrite sans contrainte” (PDF) . Transactions IEEE sur l’analyse de modèles et l’intelligence artificielle . 31 (5): 855–868. CiteSeerX 10.1.1.139.4502 . doi : 10.1109/tpami.2008.137 . PMID 19299860 . S2CID 14635907 .
- ^ un b Sak, Hasim; Sénior, André ; Beaufays, Françoise (2014). “Architectures de Réseaux de neurones récurrents à longue mémoire à court terme pour la modélisation acoustique à grande échelle” (PDF) .
- ^ un b Li, Xiangang; Wu, Xihong (2014-10-15). “Construire des Réseaux de neurones récurrents profonds basés sur la mémoire à court terme pour la reconnaissance vocale à grand vocabulaire”. arXiv : 1410.4281 [ cs.CL ].
- ^ Hyötyniemi, Heikki (1996). “Les machines de Turing sont des Réseaux de neurones récurrents“. Actes de STeP ’96 / Publications de la Société finlandaise d’intelligence artificielle : 13–24.
- ^ Miljanovic, Milos (février-mars 2012). “Analyse comparative des réseaux de neurones à réponse impulsionnelle récurrente et finie dans la prédiction des séries chronologiques” (PDF) . Journal indien d’informatique et d’ingénierie . 3 (1).
- ^ Williams, Ronald J.; Hinton, Geoffrey E.; Rumelhart, David E. (octobre 1986). “Apprentissage des représentations par rétro-propagation des erreurs”. Nature . 323 (6088): 533–536. Bibcode : 1986Natur.323..533R . doi : 10.1038/323533a0 . ISSN 1476-4687 . S2CID 205001834 .
- ^ un b Schmidhuber, Jürgen (1993). Mémoire de fin d’études : Modélisation et optimisation des systèmes (PDF) . La page 150 et suivantes illustre l’attribution de crédits sur l’équivalent de 1 200 couches dans un RNN déplié.
- ^ un Hochreiter b , Sepp ; Schmidhuber, Jürgen (1997-11-01). “Longue mémoire à court terme”. Calcul neuronal . 9 (8): 1735–1780. doi : 10.1162/neco.1997.9.8.1735 . PMID 9377276 . S2CID 1915014 .
- ^ Fernandez, Santiago; Graves, Alex ; Schmidhuber, Jürgen (2007). Une application des Réseaux de neurones récurrents au repérage discriminant des mots-clés . Actes de la 17e Conférence internationale sur les réseaux de neurones artificiels . ICANN’07. Berlin, Heidelberg : Springer Verlag. p. 220–229. ISBN 978-3-540-74693-5.
- ^ un bc Schmidhuber , Jürgen (janvier 2015). “Apprentissage en profondeur dans les réseaux de neurones : un aperçu”. Réseaux de neurones . 61 : 85–117. arXiv : 1404.7828 . doi : 10.1016/j.neunet.2014.09.003 . PMID 25462637 . S2CID 11715509 .
- ^ Graves, Alex; Schmidhuber, Jürgen (2009). Bengio, Yoshua ; Schuurmans, Dale; Lafferty, John; Williams, Chris éditeur-KI ; Culotta, Aron (éd.). “Reconnaissance de l’écriture manuscrite hors ligne avec des Réseaux de neurones récurrents multidimensionnels” . Fondation des systèmes de traitement de l’information neuronale (NIPS): 545–552. {{cite journal}}: ; a un nom générique ( aide )Cite journal requires |journal= (help)|editor-first4=
- ^ “Discours d’évaluation en anglais HUB5 2000 – Consortium de données linguistiques” . catalog.ldc.upenn.edu .
- ^ Hannoun, Awni; Cas, Carl ; Caspar, Jared ; Catanzaro, Bryan; Diamos, Greg ; Elsen, Erich; Prenger, Ryan; Satheesh, Sanjeev ; Sengupta, Shubho (2014-12-17). « Discours profond : mise à l’échelle de la reconnaissance vocale de bout en bout ». arXiv : 1412.5567 [ cs.CL ].
- ^ Fan, Bo; Wang, Lijuan ; Soong, Frank K.; Xie, Lei (2015) “Tête parlante photo-réelle avec LSTM bidirectionnel profond”, dans les actes de l’ICASSP 2015
- ^ Zen, Heiga; Sak, Hasim (2015). “Réseau de neurones récurrent à mémoire longue et à court terme unidirectionnelle avec couche de sortie récurrente pour la synthèse vocale à faible latence” (PDF) . Google.com . ICASSP. pages 4470–4474.
- ^ Sak, Hasim; Sénior, André ; Rao, Kanishka; Beaufays, Françoise; Schalkwyk, Johan (septembre 2015). “Recherche vocale Google : plus rapide et plus précise” .
- ^ un b Sutskever, Ilya; Vinyles, Oriol ; En ligneLe, Quoc V. (2014). “Apprentissage de séquence à séquence avec les réseaux de neurones” (PDF) . Actes électroniques de la conférence sur les systèmes de traitement de l’information neuronale . 27 : 5346. arXiv : 1409,3215 . Bibcode : 2014arXiv1409.3215S .
- ^ Jozefowicz, Rafal; Vinyles, Oriol ; Schuster, Mike; Shazeer, Noam ; Wu, Yonghui (2016-02-07). “Explorer les limites de la Modélisation du langage“. arXiv : 1602.02410 [ cs.CL ].
- ^ Gillick, Dan; Brunk, Cliff ; Vinyles, Oriol ; Subramanya, Amarnag (2015-11-30). “Traitement de langue multilingue à partir d’octets”. arXiv : 1512.00103 [ cs.CL ].
- ^ Vinyles, Oriol; Toshev, Alexandre; Bengio, Samy; Erhan, Dumitru (2014-11-17). “Montrer et dire : un générateur de légendes d’images neurales”. arXiv : 1411.4555 [ cs.CV ].
- ^ un b Cruse, Holk; Neural Networks as Cybernetic Systems , 2e édition révisée
- ^ Elman, Jeffrey L. (1990). “Trouver une structure dans le temps” . Sciences Cognitives . 14 (2): 179–211. doi : 10.1016/0364-0213(90)90002-E .
- ^ Jordanie, Michael I. (1997-01-01). “Ordre en série: une approche de traitement distribué parallèle”. Modèles de réseau de neurones de la cognition – Fondements biocomportementaux . Les progrès de la psychologie . Modèles de réseaux de neurones de la cognition. Vol. 121. pp. 471–495. doi : 10.1016/s0166-4115(97)80111-2 . ISBN 9780444819314.
- ^ Kosko, Bart (1988). “Mémoires associatives bidirectionnelles”. Transactions IEEE sur les systèmes, l’homme et la cybernétique . 18 (1): 49–60. doi : 10.1109/21.87054 . S2CID 59875735 .
- ^ Rakkiyappan, Rajan; Chandrasekar, Arunachalam ; Lakshmanan, Subramanien ; Park, Ju H. (2 janvier 2015). “Stabilité exponentielle pour les réseaux de neurones BAM stochastiques à saut markovien avec des retards probabilistes variant dans le temps dépendant du mode et un contrôle des impulsions”. Complexité . 20 (3): 39–65. Bibcode : 2015Cmplx..20c..39R . doi : 10.1002/cplx.21503 .
- ^ Rojas, Rául (1996). Réseaux de neurones : une introduction systématique . Springer. p. 336.ISBN _ 978-3-540-60505-8.
- ^ Jaeger, Herbert; Haas, Harald (2004-04-02). “Exploiter la non-linéarité : prévoir les systèmes chaotiques et économiser de l’énergie dans les communications sans fil”. Sciences . 304 (5667) : 78–80. Bib code : 2004Sci …304…78J . CiteSeerX 10.1.1.719.2301 . doi : 10.1126/science.1091277 . PMID 15064413 . S2CID 2184251 .
- ^ Maass, Wolfgang; Natschlager, Thomas; Markram, Henry (2002-08-20). “Un nouveau regard sur le calcul en temps réel dans les circuits neuronaux récurrents génériques”. Rapport technique. Institut d’informatique théorique, Technische Universität Graz. {{cite journal}}: Cite journal requires |journal= (help)
- ^ un b Li, Shuai; Li, Wanqing; Cuisinier, Chris ; Zhu, Ce; Yanbo, Gao (2018). “Réseau de neurones indépendamment récurrent (IndRNN): Construire un RNN plus long et plus profond”. arXiv : 1803.04831 [ cs.CV ].
- ^ Goller, Christoph; Küchler, Andreas (1996). Apprentissage de représentations distribuées dépendantes des tâches par rétropropagation à travers la structure . Conférence internationale IEEE sur les réseaux de neurones . Vol. 1. p. 347. CiteSeerX 10.1.1.52.4759 . doi : 10.1109/ICNN.1996.548916 . ISBN 978-0-7803-3210-2. S2CID 6536466 .
- ^ Linnainmaa, Seppo (1970). Représentation de l’erreur d’arrondi cumulée d’un algorithme sous la forme d’un développement de Taylor des erreurs d’arrondi locales . M.Sc. thèse (en finnois), Université d’Helsinki.
- ^ Griewank, Andreas; Walther, Andrea (2008). Évaluer les dérivés: principes et techniques de différenciation algorithmique (deuxième éd.). SIAM. ISBN 978-0-89871-776-1.
- ^ Socher, Richard; Lin, Falaise ; Ng, Andrew Y. ; Manning, Christopher D., “Parsing Natural Scenes and Natural Language with Recursive Neural Networks” (PDF) , 28e Conférence internationale sur l’apprentissage automatique (ICML 2011)
- ^ Socher, Richard; Perelygin, Alex; Wu, Jean Y.; Chuang, Jason; Manning, Christopher D.; Ng, Andrew Y. ; Potts, Christophe. “Modèles profonds récursifs pour la compositionnalité sémantique sur une arborescence de sentiments” (PDF) . Emnlp 2013 .
- ^ un bcd Schmidhuber , Jürgen (1992). “Apprentissage de séquences complexes et étendues en utilisant le principe de la compression d’historique” (PDF) . Calcul neuronal . 4 (2): 234–242. doi : 10.1162/neco.1992.4.2.234 . S2CID 18271205 .
- ^ Schmidhuber, Jürgen (2015). “Apprentissage en profondeur” . Scholarpédia . 10 (11): 32832. Bibcode : 2015SchpJ..1032832S . doi : 10.4249/scholarpedia.32832 .
- ^ un bc Hochreiter , Sepp (1991), Untersuchungen zu dynamischen neuronalen Netzen , Thèse de diplôme, Institut f. Informatique, Technische Univ. Munich, conseiller Jürgen Schmidhuber
- ^ Giles, C. Lee; Miller, Clifford B.; Chen, Dong ; Chen, Hsing-Hen; Soleil, Guo-Zheng ; Lee, Yee-Chun (1992). “Apprentissage et extraction d’automates à états finis avec des Réseaux de neurones récurrents de second ordre” (PDF) . Calcul neuronal . 4 (3): 393–405. doi : 10.1162/neco.1992.4.3.393 . S2CID 19666035 .
- ^ Omlin, Christian W.; Giles, C. Lee (1996). “Construire des automates à états finis déterministes dans des Réseaux de neurones récurrents“. Journal de l’ACM . 45 (6): 937–972. CiteSeerX 10.1.1.32.2364 . doi : 10.1145/235809.235811 . S2CID 228941 .
- ↑ Gers, Félix A. ; Schraudolph, Nicol N.; Schmidhuber, Jürgen (2002). “Apprentissage de la synchronisation précise avec les réseaux récurrents LSTM” (PDF) . Journal de recherche sur l’apprentissage automatique . 3 : 115–143 . Récupéré le 13/06/2017 .
- ^ Bayer, Justin; Wierstra, Daan; Togelius, Julien; Schmidhuber, Jürgen (2009-09-14). Structures de cellules de mémoire en évolution pour l’apprentissage de séquences (PDF) . Réseaux de neurones artificiels – ICANN 2009 . Notes de cours en informatique. Vol. 5769. Berlin, Heidelberg : Springer. pp. 755–764. doi : 10.1007/978-3-642-04277-5_76 . ISBN 978-3-642-04276-8.
- ^ Fernandez, Santiago; Graves, Alex ; Schmidhuber, Jürgen (2007). “Étiquetage de séquences dans des domaines structurés avec des Réseaux de neurones récurrents hiérarchiques”. Proc. 20e Conférence conjointe internationale sur l’intelligence artificielle, Ijcai 2007 : 774–779. CiteSeerX 10.1.1.79.1887 .
- ^ Graves, Alex; Fernandez, Santiago ; Gomez, Faustino J. (2006). “Classification temporelle connexionniste: étiquetage des données de séquence non segmentées avec des Réseaux de neurones récurrents“. Actes de la conférence internationale sur l’apprentissage automatique : 369–376. CiteSeerX 10.1.1.75.6306 .
- ↑ Gers, Félix A. ; Schmidhuber, Jürgen (novembre 2001). “Les réseaux récurrents LSTM apprennent des langages simples sans contexte et sensibles au contexte” . Transactions IEEE sur les réseaux de neurones . 12 (6): 1333–1340. doi : 10.1109/72.963769 . ISSN 1045-9227 . PMID 18249962 . S2CID 10192330 .
- ^ Heck, Joel; Salem, Fathi M. (2017-01-12). “Variations d’unités fermées minimales simplifiées pour les Réseaux de neurones récurrents“. arXiv : 1701.03452 [ cs.NE ].
- ^ Dey, Rahul; Salem, Fathi M. (2017-01-20). “Variantes de porte des réseaux de neurones à unité récurrente fermée (GRU)”. arXiv : 1701.05923 [ cs.NE ].
- ^ Chung, Junyoung; Gulcehre, Caglar ; Cho, KyungHyun ; Bengio, Yoshua (2014). “Évaluation empirique des Réseaux de neurones récurrents fermés sur la modélisation de séquence”. arXiv : 1412.3555 [ cs.NE ].
- ^ Britz, Denny (27 octobre 2015). “Didacticiel de réseau de neurones récurrent, partie 4 – Implémentation d’un RNN GRU/LSTM avec Python et Theano – WildML” . Wildml.com . Consulté le 18 mai 2016 .
- ^ Graves, Alex; Schmidhuber, Jürgen (2005-07-01). “Classification des phonèmes par trame avec LSTM bidirectionnel et autres architectures de réseaux neuronaux”. Réseaux de neurones . IJCNN 2005. 18 (5) : 602–610. CiteSeerX 10.1.1.331.5800 . doi : 10.1016/j.neunet.2005.06.042 . PMID 16112549 .
- ^ un b Thireou, Trias; Reczko, Martin (juillet 2007). “Réseaux de mémoire à long terme bidirectionnels pour prédire la localisation subcellulaire des protéines eucaryotes”. Transactions IEEE/ACM sur la biologie computationnelle et la bioinformatique . 4 (3): 441–446. doi : 10.1109/tcbb.2007.1015 . PMID 17666763 . S2CID 11787259 .
- ^ Harvey, Inman; Maris, Phil ; Cliff, Dave (1994), “Seeing the light: Artificial evolution, real vision” , 3e conférence internationale sur la simulation du comportement adaptatif: des animaux aux animats 3 , pp. 392–401
- ^ Quinn, Matthieu (2001). “Une communication évolutive sans canaux de communication dédiés”. Progrès de la vie artificielle . Notes de cours en informatique. Vol. 2159. pp. 357–366. CiteSeerX 10.1.1.28.5890 . doi : 10.1007/3-540-44811-X_38 . ISBN 978-3-540-42567-0. {{cite book}}: Manquant ou vide |title=( aide )
- ^ Bière, Randall D. (1997). « La dynamique du comportement adaptatif : Un programme de recherche ». Robotique et systèmes autonomes . 20 (2–4): 257–289. doi : 10.1016/S0921-8890(96)00063-2 .
- ^ Sherstinsky, Alex (2018-12-07). Bloem-Reddy, Benjamin ; Paige, Brooks; Kusner, Matt ; Caruana, riche ; Pluie, Tom ; Teh, Yee Whye (éd.). Dérivation de la définition du réseau de neurones récurrent et du déroulement du RNN à l’aide du traitement du signal . Critiquer et corriger les tendances dans l’atelier d’apprentissage automatique à NeurIPS-2018 .
- ^ Paine, Rainer W.; Tani, juin (2005-09-01). “Comment le contrôle hiérarchique s’auto-organise dans les systèmes adaptatifs artificiels”. Comportement adaptatif . 13 (3): 211–225. doi : 10.1177/105971230501300303 . S2CID 9932565 .
- ^ un b “Burns, Benureau, Tani (2018) Une constante de temps adaptative inspirée de Bergson pour le modèle de réseau neuronal récurrent à plusieurs échelles de temps. JNNS” .
- ^ Tutschku, Kurt (juin 1995). Perceptrons multicouches récurrents pour l’identification et le contrôle : la route vers les applications . Rapport de l’Institut de recherche en informatique. Vol. 118. Université de Würzburg Am Hubland. CiteSeerX 10.1.1.45.3527 . {{cite book}}: CS1 maint: date and year (link)
- ^ Yamashita, Yuichi; Tani, juin (2008-11-07). “Émergence de la hiérarchie fonctionnelle dans un modèle de réseau de neurones à plusieurs échelles de temps : une expérience de robot humanoïde” . Biologie computationnelle PLOS . 4 (11) : e1000220. Bibcode : 2008PLSCB…4E0220Y . doi : 10.1371/journal.pcbi.1000220 . PMC 2570613 . PMID 18989398 .
- ^ Alnajjar, Fady; Yamashita, Yuichi; Tani, juin (2013). “La connectivité hiérarchique et fonctionnelle des mécanismes cognitifs d’ordre supérieur : modèle neurorobotique pour étudier la stabilité et la flexibilité de la mémoire de travail” . Frontières en neurorobotique . 7 : 2. doi : 10.3389/fnbot.2013.00002 . PMC 3575058 . PMID 23423881 .
- ^ “Actes de la 28e conférence annuelle de la Japanese Neural Network Society (octobre 2018)” (PDF) .
- ^ Graves, Alex; Wayne, Greg; Danihelka, Ivo (2014). “Machines de Turing neurales”. arXiv : 1410.5401 [ cs.NE ].
- ^ Soleil, Guo-Zheng; Giles, C. Lee; Chen, Hsing-Hen (1998). “L’automate de refoulement de réseau neuronal : architecture, dynamique et formation”. Dans Giles, C. Lee; Gori, Marco (éd.). Traitement adaptatif des séquences et des structures de données . Notes de cours en informatique. Berlin, Heidelberg : Springer. p. 296–345. CiteSeerX 10.1.1.56.8723 . doi : 10.1007/bfb0054003 . ISBN 9783540643418.
- ^ Snider, Greg (2008), “Informatique corticale avec des nanodispositifs memristifs” , Sci-DAC Review , 10 : 58–65
- ^ Caravelli, Francesco; Traversa, Fabio Lorenzo; Di Ventra, Massimiliano (2017). “La dynamique complexe des circuits memristifs : résultats analytiques et relaxation lente universelle”. Examen physique E . 95 (2) : 022140. arXiv : 1608.08651 . Bibcode : 2017PhRvE..95b2140C . doi : 10.1103/PhysRevE.95.022140 . PMID 28297937 . S2CID 6758362 .
- ^ Caravelli, Francesco (2019-11-07). “Comportement asymptotique des circuits memristifs” . Entropie . 21 (8): 789. Bibcode : 2019Entrp..21..789C . doi : 10.3390/e21080789 . PMC 789 . PMID 33267502 .
- ^ Werbos, Paul J. (1988). “Généralisation de la rétropropagation avec application à un modèle récurrent de marché du gaz” . Réseaux de neurones . 1 (4): 339–356. doi : 10.1016/0893-6080(88)90007-x .
- ^ Rumelhart, David E. (1985). Apprentissage des représentations internes par propagation d’erreurs . San Diego (CA) : Institut des sciences cognitives, Université de Californie.
- ^ Robinson, Anthony J.; Fallside, Frank (1987). Le réseau de propagation d’erreur dynamique piloté par l’utilitaire . Rapport technique CUED/F-INFENG/TR.1. Département d’ingénierie, Université de Cambridge.
- ^ Williams, Ronald J.; Zipser, D. (1er février 2013). “Algorithmes d’apprentissage basés sur les gradients pour les réseaux récurrents et leur complexité de calcul”. À Chauvin, Yves; Rumelhart, David E. (éd.). Rétropropagation : théorie, architectures et applications . Presse Psychologique. ISBN 978-1-134-77581-1.
- ^ Schmidhuber, Jürgen (1989-01-01). “Un algorithme d’apprentissage local pour les réseaux dynamiques à anticipation et récurrents”. Sciences de la connexion . 1 (4): 403–412. doi : 10.1080/09540098908915650 . S2CID 18721007 .
- ^ Príncipe, José C.; Euliano, Neil R.; En ligneLefebvre, W. Curt (2000). Systèmes neuronaux et adaptatifs : les fondamentaux à travers les simulations . Wiley. ISBN 978-0-471-35167-2.
- ↑ Yann, Ollivier ; Tallec, Corentin; Charpiat, Guillaume (2015-07-28). « Former des réseaux récurrents en ligne sans retour en arrière ». arXiv : 1507.07680 [ cs.NE ].
- ^ Schmidhuber, Jürgen (1992-03-01). “Un algorithme d’apprentissage de la complexité temporelle de stockage de taille fixe O (n3) pour des réseaux fonctionnant en continu entièrement récurrents”. Calcul neuronal . 4 (2): 243–248. doi : 10.1162/neco.1992.4.2.243 . S2CID 11761172 .
- ^ Williams, Ronald J. (1989). “Complexité des algorithmes de calcul de gradient exact pour les Réseaux de neurones récurrents” . Rapport technique NU-CCS-89-27. Boston (MA): Université Northeastern, Collège d’informatique. {{cite journal}}: Cite journal requires |journal= (help)
- ^ Pearlmutter, Barak A. (1989-06-01). “Apprentissage des trajectoires d’espace d’état dans les Réseaux de neurones récurrents” . Calcul neuronal . 1 (2): 263–269. doi : 10.1162/neco.1989.1.2.263 . S2CID 16813485 .
- ^ Hochreiter, Sepp; et coll. (15 janvier 2001). “Flux de gradient dans les réseaux récurrents : la difficulté d’apprendre les dépendances à long terme” . À Kolen, John F. ; Kremer, Stefan C. (éd.). Un guide de terrain pour les réseaux récurrents dynamiques . John Wiley et fils. ISBN 978-0-7803-5369-5.
- ^ Campolucci, Paolo; Uncini, Aurelio; Place, Francesco; Rao, Bhaskar D. (1999). “Algorithmes d’apprentissage en ligne pour les réseaux de neurones localement récurrents”. Transactions IEEE sur les réseaux de neurones . 10 (2): 253–271. CiteSeerX 10.1.1.33.7550 . doi : 10.1109/72.750549 . PMID 18252525 .
- ^ Wan, Eric A.; Beaufays, Françoise (1996). “Dérivation schématique des algorithmes de gradient pour les réseaux de neurones”. Calcul neuronal . 8 : 182–201. doi : 10.1162/neco.1996.8.1.182 . S2CID 15512077 .
- ^ un b Campolucci, Paolo; Uncini, Aurelio; Place, Francesco (2000). “Une approche Signal-Flow-Graph pour le calcul de gradient en ligne”. Calcul neuronal . 12 (8) : 1901–1927. CiteSeerX 10.1.1.212.5406 . doi : 10.1162/089976600300015196 . PMID 10953244 . S2CID 15090951 .
- ^ Gomez, Faustino J.; Miikkulainen, Risto (1999), “Résoudre des tâches de contrôle non-Markoviennes avec la neuroévolution” (PDF) , IJCAI 99 , Morgan Kaufmann , récupéré le 5 août 2017
- ^ Syed, Omar (mai 1995). “Application d’algorithmes génétiques aux Réseaux de neurones récurrents pour l’apprentissage des paramètres et de l’architecture du réseau” . M.Sc. thèse, Département de génie électrique, Case Western Reserve University, conseiller Yoshiyasu Takefuji.
- ^ Gomez, Faustino J.; Schmidhuber, Jürgen; Miikkulainen, Risto (juin 2008). “Évolution neuronale accélérée grâce à des synapses coévoluées en coopération” . Journal de recherche sur l’apprentissage automatique . 9 : 937–965.
- ^ Siegelmann, Hava T.; Horne, Bill G.; Giles, C. Lee (1995). “Capacités de calcul des réseaux de neurones NARX récurrents” . Transactions IEEE sur les systèmes, l’homme et la cybernétique, partie B (cybernétique) . 27 (2): 208–215. CiteSeerX 10.1.1.48.7468 . doi : 10.1109/3477.558801 . PMID 18255858 .
- ^ Metz, Cade (18 mai 2016). “Google a construit ses propres puces pour alimenter ses robots IA” . Câblé .
- ^ Mayer, Hermann; Gomez, Faustino J.; Wierstra, Daan; Nagy, Istvan ; Knoll, Alois ; Schmidhuber, Jürgen (octobre 2006). Un système de chirurgie cardiaque robotique qui apprend à faire des nœuds à l’aide de Réseaux de neurones récurrents . 2006 Conférence internationale IEEE/RSJ sur les robots et systèmes intelligents . pages 543–548. CiteSeerX 10.1.1.218.3399 . doi : 10.1109/IROS.2006.282190 . ISBN 978-1-4244-0258-8. S2CID 12284900 .
- ^ Wierstra, Daan; Schmidhuber, Jürgen; Gomez, Faustino J. (2005). « Evolino : neuroévolution hybride/recherche linéaire optimale pour l’apprentissage de séquences » . Actes de la 19e Conférence conjointe internationale sur l’intelligence artificielle (IJCAI), Édimbourg : 853–858.
- ^ Petneházi, Gábor (2019-01-01). “Réseaux de neurones récurrents pour la prévision de séries chronologiques”. arXiv : 1901.00069 [ cs.LG ].
- ^ Hewamalage, Hansika; Bergmeir, Christoph; Bandara, Kasun (2020). “Réseaux de neurones récurrents pour la prévision de séries chronologiques : état actuel et orientations futures”. Journal international de prévision . 37 : 388–427. arXiv : 1909.00590 . doi : 10.1016/j.ijforecast.2020.06.008 . S2CID 202540863 .
- ^ Graves, Alex; Schmidhuber, Jürgen (2005). “Classification des phonèmes par trame avec LSTM bidirectionnel et autres architectures de réseaux neuronaux”. Réseaux de neurones . 18 (5–6): 602–610. CiteSeerX 10.1.1.331.5800 . doi : 10.1016/j.neunet.2005.06.042 . PMID 16112549 .
- ^ Fernandez, Santiago; Graves, Alex ; Schmidhuber, Jürgen (2007). Une application des Réseaux de neurones récurrents au repérage discriminant des mots-clés . Actes de la 17e Conférence internationale sur les réseaux de neurones artificiels . ICANN’07. Berlin, Heidelberg : Springer Verlag. p. 220–229. ISBN 978-3540746935.
- ^ Graves, Alex; Mohamed, Abdel-rahman; En ligneHinton, Geoffrey E. (2013). “Reconnaissance vocale avec des Réseaux de neurones récurrents profonds”. Acoustique, traitement de la parole et du signal (ICASSP), Conférence internationale IEEE 2013 sur : 6645–6649. arXiv : 1303.5778 . Bibcode : 2013arXiv1303.5778G . doi : 10.1109/ICASSP.2013.6638947 . ISBN 978-1-4799-0356-6. S2CID 206741496 .
- ^ Chang, Edward F.; Chartier, Josh; Anumanchipalli, Gopala K. (24 avril 2019). “Synthèse de la parole à partir du décodage neuronal des phrases parlées”. Nature . 568 (7753): 493–498. Bibcode : 2019Natur.568..493A . doi : 10.1038/s41586-019-1119-1 . ISSN 1476-4687 . PMID 31019317 . S2CID 129946122 .
- ^ Moïse, David A., Sean L. Metzger, Jessie R. Liu, Gopala K. Anumanchipalli, Joseph G. Makin, Pengfei F. Sun, Josh Chartier, et al. “Neuroprothèse pour le décodage de la parole chez une personne paralysée atteinte d’anarthrie.” New England Journal of Medicine 385, no. 3 (15 juillet 2021) : 217–227. https://doi.org/10.1056/NEJMoa2027540 .
- ^ Malhotra, Pankaj; Vig, Lovekesh ; Shroff, Gautam ; Agarwal, Puneet (avril 2015). “Réseaux de mémoire à long terme pour la détection d’anomalies dans les séries chronologiques” (PDF) . Symposium européen sur les réseaux de neurones artificiels, l’intelligence computationnelle et l’apprentissage automatique — ESANN 2015 .
- ↑ Gers, Félix A. ; Schraudolph, Nicol N.; Schmidhuber, Jürgen (2002). “Apprentissage d’un timing précis avec les réseaux récurrents LSTM” (PDF) . Journal de recherche sur l’apprentissage automatique . 3 : 115–143.
- ^ Eck, Douglas; Schmidhuber, Jürgen (2002-08-28). Apprendre la structure à long terme du Blues . Réseaux de neurones artificiels — ICANN 2002 . Notes de cours en informatique. Vol. 2415. Berlin, Heidelberg : Springer. p. 284–289. CiteSeerX 10.1.1.116.3620 . doi : 10.1007/3-540-46084-5_47 . ISBN 978-3540460848.
- ^ Schmidhuber, Jürgen; Gers, Félix A. ; En ligneEck, Douglas (2002). “Apprentissage des langues non régulières: Une comparaison des réseaux récurrents simples et LSTM”. Calcul neuronal . 14 (9): 2039-2041. CiteSeerX 10.1.1.11.7369 . doi : 10.1162/089976602320263980 . PMID 12184841 . S2CID 30459046 .
- ↑ Gers, Félix A. ; Schmidhuber, Jürgen (2001). “Les réseaux récurrents LSTM apprennent des langages simples sans contexte et sensibles au contexte” (PDF) . Transactions IEEE sur les réseaux de neurones . 12 (6): 1333–1340. doi : 10.1109/72.963769 . PMID 18249962 .
- ^ Pérez-Ortiz, Juan Antonio; Gers, Félix A. ; Eck, Douglas ; Schmidhuber, Jürgen (2003). “Les filtres de Kalman améliorent les performances du réseau LSTM dans les problèmes insolubles par les réseaux récurrents traditionnels”. Réseaux de neurones . 16 (2): 241–250. CiteSeerX 10.1.1.381.1992 . doi : 10.1016/s0893-6080(02)00219-8 . PMID 12628609 .
- ^ Graves, Alex; Schmidhuber, Jürgen (2009). “Reconnaissance de l’écriture manuscrite hors ligne avec des Réseaux de neurones récurrents multidimensionnels”. Advances in Neural Information Processing Systems 22, NIPS’22 . Vancouver (C.-B.) : MIT Press : 545–552.
- ^ Graves, Alex; Fernandez, Santiago ; Liwicki, Marcus; Bunke, Horst; Schmidhuber, Jürgen (2007). Reconnaissance de l’écriture manuscrite en ligne sans contrainte avec les Réseaux de neurones récurrents . Actes de la 20e Conférence internationale sur les systèmes de traitement de l’information neuronale . NIPS’07. Curran Associates Inc. p. 577–584. ISBN 9781605603520.
- ^ Baccouche, Moez; Mamalet, Franck; loup, chrétien; Garcia, Christophe; Baskurt, Atilla (2011). Salah, Albert Ali; Lepri, Bruno (dir.). “Apprentissage profond séquentiel pour la reconnaissance de l’action humaine”. 2e Atelier international sur la compréhension du comportement humain (HBU) . Notes de cours en informatique. Amsterdam, Pays-Bas : Springer. 7065 : 29–39. doi : 10.1007/978-3-642-25446-8_4 . ISBN 978-3-642-25445-1.
- ^ Hochreiter, Sepp; Heusel, Martin; Obermayer, Klaus (2007). “Détection rapide d’homologie de protéines basée sur un modèle sans alignement” . Bioinformatique . 23 (14): 1728-1736. doi : 10.1093/bioinformatique/btm247 . PMID 17488755 .
- ^ Taxe, Niek; Verenich, Ilya; La Rosa, Marcello; Dumas, Marlon (2017). Surveillance prédictive des processus métier avec les réseaux de neurones LSTM . Actes de la Conférence internationale sur l’ingénierie des systèmes d’information avancés (CAiSE) . Notes de cours en informatique. Vol. 10253. p. 477–492. arXiv : 1612.02130 . doi : 10.1007/978-3-319-59536-8_30 . ISBN 978-3-319-59535-1. S2CID 2192354 .
- ^ Choi, Edouard; Bahadori, Mohammad Taha; Schuetz, Andy; Stewart, Walter F.; Soleil, Jimeng (2016). “Doctor AI : Prédire les événements cliniques via les Réseaux de neurones récurrents” . Actes de la 1ère conférence Machine Learning for Healthcare . 56 : 301–318. arXiv : 1511.05942 . Bibcode : 2015arXiv151105942C . PMC 5341604 . PMID 28286600 .
Lectures complémentaires
- Mandic, Danilo P. & Chambers, Jonathon A. (2001). Réseaux de neurones récurrents pour la prédiction : algorithmes d’apprentissage, architectures et stabilité . Wiley. ISBN 978-0-471-49517-8.
Liens externes
- Recurrent Neural Networks avec plus de 60 articles RNN par le groupe de Jürgen Schmidhuber à l’ Institut Dalle Molle pour la recherche sur l’intelligence artificielle
- Mise en œuvre du réseau de neurones Elman pour WEKA