Optimisation du moteur de recherche
L’ optimisation pour les moteurs de recherche ( SEO ) est le processus d’amélioration de la qualité et de la quantité du trafic d’un site Web vers un site Web ou une page Web à partir des moteurs de recherche . [1] Le référencement cible le trafic non rémunéré (appelé résultats “naturels” ou ” organiques “) plutôt que le trafic direct ou le trafic payant . Le trafic non rémunéré peut provenir de différents types de recherches, y compris la recherche d’images , la recherche de vidéos , la recherche académique , [2] la recherche d’actualités et les moteurs de recherche verticaux spécifiques à l’industrie .
En tant que stratégie de marketing Internet , le référencement prend en compte le fonctionnement des moteurs de recherche, les algorithmes programmés par ordinateur qui dictent le comportement des moteurs de recherche, ce que les gens recherchent, les termes de recherche réels ou les mots clés saisis dans les moteurs de recherche et les moteurs de recherche préférés par leur public cible. . Le référencement est effectué parce qu’un site Web recevra plus de visiteurs d’un moteur de recherche lorsque les sites Web seront mieux classés sur la page de résultats du moteur de recherche (SERP). Ces visiteurs peuvent alors potentiellement être convertis en clients. [3]
Histoire
Les webmasters et les fournisseurs de contenu ont commencé à optimiser les sites Web pour les moteurs de recherche au milieu des années 1990, alors que les premiers moteurs de recherche cataloguaient les débuts du Web . Au départ, tous les webmasters n’avaient qu’à soumettre l’adresse d’une page, ou URL , aux différents moteurs qui enverraient un robot d’indexation pour explorer cette page, en extraire des liens vers d’autres pages et renvoyer les informations trouvées sur la page à indexer . . [4] Le processus implique qu’un moteur de recherche télécharge une page et la stocke sur le propre serveur du moteur de recherche. Un deuxième programme, connu sous le nom d’ indexeur, extrait des informations sur la page, telles que les mots qu’elle contient, où ils se trouvent, et tout poids pour des mots spécifiques, ainsi que tous les liens que la page contient. Toutes ces informations sont ensuite placées dans un planificateur pour une exploration ultérieure.
Les propriétaires de sites Web ont reconnu la valeur d’un classement et d’une visibilité élevés dans les résultats des moteurs de recherche [5] , créant une opportunité pour les professionnels du référencement White Hat et Black Hat . Selon l’analyste de l’industrie Danny Sullivan , l’expression “optimisation pour les moteurs de recherche” a probablement été utilisée en 1997. Sullivan attribue à Bruce Clay l’une des premières personnes à populariser le terme. [6]
Les premières versions des algorithmes de recherche s’appuyaient sur des informations fournies par les webmasters, telles que la Balise méta du mot-clé ou les fichiers d’index dans des moteurs comme ALIWEB . Les balises Meta fournissent un guide pour le contenu de chaque page. Cependant, l’utilisation des métadonnées pour indexer les pages s’est avérée peu fiable, car le choix des mots-clés par le webmaster dans la Balise méta pouvait potentiellement être une représentation inexacte du contenu réel du site. Les données erronées dans les Balises méta telles que celles qui n’étaient pas exactes, complètes ou faussement attribuées ont créé le risque que les pages soient mal caractérisées dans des recherches non pertinentes. [7] [ douteux – discuter ] Les fournisseurs de contenu Web ont également manipulé certains attributs dans leSource HTML d’une page dans le but de bien se classer dans les moteurs de recherche. [8] En 1997, les concepteurs de moteurs de recherche ont reconnu que les webmasters faisaient des efforts pour bien se classer dans leur moteur de recherche, et que certains webmasters manipulaient même leur classement dans les résultats de recherche en bourrant les pages de mots-clés excessifs ou non pertinents. Les premiers moteurs de recherche, tels que Altavista et Infoseek , ont ajusté leurs algorithmes pour empêcher les webmasters de manipuler les classements. [9]
En s’appuyant fortement sur des facteurs tels que la densité des mots clés , qui étaient exclusivement sous le contrôle d’un webmaster, les premiers moteurs de recherche ont souffert d’abus et de manipulations de classement. Pour fournir de meilleurs résultats à leurs utilisateurs, les moteurs de recherche ont dû s’adapter pour s’assurer que leurs pages de résultats affichent les résultats de recherche les plus pertinents, plutôt que des pages sans rapport bourrées de nombreux mots-clés par des webmasters peu scrupuleux. Cela impliquait de passer d’une forte dépendance à la densité de termes à un processus plus holistique de notation des signaux sémantiques. [dix]Étant donné que le succès et la popularité d’un moteur de recherche sont déterminés par sa capacité à produire les résultats les plus pertinents pour une recherche donnée, des résultats de recherche de mauvaise qualité ou non pertinents pourraient amener les utilisateurs à trouver d’autres sources de recherche. Les moteurs de recherche ont réagi en développant des algorithmes de classement plus complexes, prenant en compte des facteurs supplémentaires plus difficiles à manipuler pour les webmasters.
Les entreprises qui utilisent des techniques trop agressives peuvent faire bannir les sites Web de leurs clients des résultats de recherche. En 2005, le Wall Street Journal a rendu compte d’une entreprise, Traffic Power , qui aurait utilisé des techniques à haut risque et n’a pas divulgué ces risques à ses clients. [11] Le magazine Wired a rapporté que la même société avait poursuivi le blogueur et SEO Aaron Wall pour avoir écrit sur l’interdiction. [12] Matt Cutts de Google a confirmé plus tard que Google avait effectivement interdit Traffic Power et certains de ses clients. [13]
Certains moteurs de recherche ont également contacté l’industrie du référencement et sont fréquemment sponsors et invités lors de conférences, de discussions en ligne et de séminaires sur le référencement. Les principaux moteurs de recherche fournissent des informations et des directives pour aider à l’optimisation du site Web. [14] [15] Google a un programme Sitemaps pour aider les webmasters à savoir si Google a des problèmes pour indexer leur site Web et fournit également des données sur le trafic de Google vers le site Web. [16] Bing Webmaster Tools permet aux webmasters de soumettre un plan du site et des flux Web, permet aux utilisateurs de déterminer le “taux d’exploration” et de suivre l’état de l’index des pages Web.
En 2015, il a été signalé que Google développait et promouvait la recherche mobile en tant que fonctionnalité clé dans les futurs produits. En réponse, de nombreuses marques ont commencé à adopter une approche différente de leurs stratégies de marketing Internet. [17]
Relation avec Google
En 1998, deux étudiants diplômés de l’Université de Stanford , Larry Page et Sergey Brin , ont développé “Backrub”, un moteur de recherche qui s’appuyait sur un algorithme mathématique pour évaluer la proéminence des pages Web. Le nombre calculé par l’algorithme, PageRank , est fonction de la quantité et de la force des liens entrants . [18] PageRank estime la probabilité qu’une page donnée soit atteinte par un internaute qui navigue au hasard sur le Web et suit les liens d’une page à l’autre. En effet, cela signifie que certains liens sont plus forts que d’autres, car une page PageRank plus élevée est plus susceptible d’être atteinte par l’internaute aléatoire.
Page et Brin ont fondé Google en 1998. [19] Google a attiré une clientèle fidèle parmi le nombre croissant d’ internautes , qui ont aimé sa conception simple. [20] Des facteurs hors page (tels que le PageRank et l’analyse des hyperliens) ont été pris en compte ainsi que des facteurs sur la page (tels que la fréquence des mots clés, les Balises méta , les en-têtes, les liens et la structure du site) pour permettre à Google d’éviter le type de manipulation observé dans les moteurs de recherche qui ne tenaient compte que des facteurs sur la page pour leurs classements. Bien que le PageRank soit plus difficile à jouer , les webmasters avaient déjà développé des outils de création de liens et des schémas pour influencer l’ Inktomi.moteur de recherche, et ces méthodes se sont avérées applicables de la même manière au jeu PageRank. De nombreux sites se sont concentrés sur l’échange, l’achat et la vente de liens, souvent à grande échelle. Certains de ces stratagèmes, ou fermes de liens , impliquaient la création de milliers de sites dans le seul but de spammer des liens . [21]
En 2004, les moteurs de recherche avaient intégré un large éventail de facteurs non divulgués dans leurs algorithmes de classement afin de réduire l’impact de la manipulation des liens. En juin 2007, Saul Hansell du New York Times a déclaré que Google classait les sites en utilisant plus de 200 signaux différents. [22] Les principaux moteurs de recherche, Google, Bing et Yahoo , ne divulguent pas les algorithmes qu’ils utilisent pour classer les pages. Certains praticiens du référencement ont étudié différentes approches de l’optimisation des moteurs de recherche et ont partagé leurs opinions personnelles. [23] Les brevets liés aux moteurs de recherche peuvent fournir des informations permettant de mieux comprendre les moteurs de recherche. [24]En 2005, Google a commencé à personnaliser les résultats de recherche pour chaque utilisateur. En fonction de l’historique de leurs recherches précédentes, Google a créé des résultats pour les utilisateurs connectés. [25]
En 2007, Google a annoncé une campagne contre les liens payants qui transfèrent le PageRank. [26] Le 15 juin 2009, Google a révélé qu’il avait pris des mesures pour atténuer les effets de la sculpture du PageRank en utilisant l’ attribut nofollow sur les liens. Matt Cutts , un ingénieur logiciel bien connu de Google, a annoncé que Google Bot ne traiterait plus aucun lien nofollow, de la même manière, pour empêcher les fournisseurs de services SEO d’utiliser le nofollow pour la sculpture PageRank. [27] À la suite de ce changement, l’utilisation du nofollow a conduit à l’évaporation du PageRank. Afin d’éviter ce qui précède, les ingénieurs SEO ont développé des techniques alternatives qui remplacent les balises nofollowed par du JavaScript obfusqué.et ainsi permettre la sculpture du PageRank. De plus, plusieurs solutions ont été suggérées qui incluent l’utilisation d’ iframes , Flash et JavaScript. [28]
En décembre 2009, Google a annoncé qu’il utiliserait l’historique de recherche Web de tous ses utilisateurs afin de remplir les résultats de recherche. [29] Le 8 juin 2010, un nouveau système d’indexation Web appelé Google Caffeine a été annoncé. Conçu pour permettre aux utilisateurs de trouver des résultats d’actualités, des messages de forum et d’autres contenus beaucoup plus tôt après la publication qu’auparavant, Google Caffeine a modifié la façon dont Google a mis à jour son index afin que les choses s’affichent plus rapidement sur Google qu’auparavant. Selon Carrie Grimes, l’ingénieur logiciel qui a annoncé Caffeine pour Google, “Caffeine fournit 50 % de résultats plus récents pour les recherches sur le Web que notre dernier index…” [30] Google Instant, la recherche en temps réel, a été introduite fin 2010 dans le but de rendre les résultats de recherche plus opportuns et pertinents. Historiquement, les administrateurs de site ont passé des mois, voire des années, à optimiser un site Web pour augmenter les classements de recherche. Avec la popularité croissante des sites de médias sociaux et des blogs, les principaux moteurs ont modifié leurs algorithmes pour permettre au nouveau contenu de se classer rapidement dans les résultats de recherche. [31]
En février 2011, Google a annoncé la mise à jour Panda , qui pénalise les sites Web contenant du contenu dupliqué à partir d’autres sites Web et sources. Historiquement, les sites Web ont copié le contenu les uns des autres et ont bénéficié des classements des moteurs de recherche en s’engageant dans cette pratique. Cependant, Google a mis en place un nouveau système qui punit les sites dont le contenu n’est pas unique. [32] Le Google Penguin de 2012 a tenté de pénaliser les sites Web qui utilisaient des techniques de manipulation pour améliorer leur classement sur le moteur de recherche. [33] Bien que Google Penguin ait été présenté comme un algorithme visant à lutter contre le spam Web, il se concentre vraiment sur les liens spammés [34] en évaluant la qualité des sites d’où proviennent les liens. Le 2013La mise à jour de Google Hummingbird comportait un changement d’algorithme conçu pour améliorer le traitement du langage naturel de Google et la compréhension sémantique des pages Web. Le système de traitement du langage de Hummingbird relève du terme nouvellement reconnu de ” recherche conversationnelle ” où le système accorde plus d’attention à chaque mot de la requête afin de mieux faire correspondre les pages au sens de la requête plutôt qu’à quelques mots. [35] En ce qui concerne les modifications apportées à l’optimisation des moteurs de recherche, pour les éditeurs de contenu et les rédacteurs, Hummingbird vise à résoudre les problèmes en se débarrassant du contenu non pertinent et du spam, permettant à Google de produire un contenu de haute qualité et de compter sur eux pour être ‘ auteurs de confiance.
En octobre 2019, Google a annoncé qu’il commencerait à appliquer les modèles BERT (Représentations d’encodeurs bidirectionnels de transformateurs) pour les requêtes de recherche en anglais aux États-Unis. BERT était une autre tentative de Google pour améliorer leur traitement du langage naturel, mais cette fois afin de mieux comprendre les requêtes de recherche de leurs utilisateurs. [36] En termes d’optimisation des moteurs de recherche, le BERT visait à connecter plus facilement les utilisateurs à un contenu pertinent et à augmenter la qualité du trafic provenant des sites Web classés dans la page de résultats des moteurs de recherche.
Méthodes
Se faire indexer
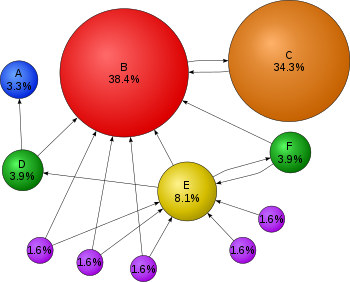 Les moteurs de recherche utilisent des algorithmes mathématiques complexes pour interpréter les sites Web qu’un utilisateur recherche. Dans ce diagramme, où chaque bulle représente un site Web, des programmes parfois appelés araignées examinent quels sites renvoient vers quels autres sites, avec des flèches représentant ces liens. Les sites Web obtenant plus de liens entrants, ou des liens plus forts, sont présumés être plus importants et ce que l’utilisateur recherche. Dans cet exemple, puisque le site Web B est le destinataire de nombreux liens entrants, il se classe plus haut dans une recherche Web. Et les liens “transfèrent”, de sorte que le site Web C, même s’il n’a qu’un seul Lien entrant, a un Lien entrant d’un site très populaire (B) alors que le site E n’en a pas. Remarque : Les pourcentages sont arrondis.
Les moteurs de recherche utilisent des algorithmes mathématiques complexes pour interpréter les sites Web qu’un utilisateur recherche. Dans ce diagramme, où chaque bulle représente un site Web, des programmes parfois appelés araignées examinent quels sites renvoient vers quels autres sites, avec des flèches représentant ces liens. Les sites Web obtenant plus de liens entrants, ou des liens plus forts, sont présumés être plus importants et ce que l’utilisateur recherche. Dans cet exemple, puisque le site Web B est le destinataire de nombreux liens entrants, il se classe plus haut dans une recherche Web. Et les liens “transfèrent”, de sorte que le site Web C, même s’il n’a qu’un seul Lien entrant, a un Lien entrant d’un site très populaire (B) alors que le site E n’en a pas. Remarque : Les pourcentages sont arrondis.
Les principaux moteurs de recherche, tels que Google, Bing et Yahoo!, utilisent des robots d’exploration pour trouver des pages pour leurs résultats de recherche algorithmiques. Les pages qui sont liées à partir d’autres pages indexées par les moteurs de recherche n’ont pas besoin d’être soumises car elles sont trouvées automatiquement. Le Yahoo! Directory et DMOZ , deux répertoires majeurs qui ont fermé respectivement en 2014 et 2017, nécessitaient tous deux une soumission manuelle et une révision éditoriale humaine. [37] Google propose Google Search Console , pour laquelle un flux Sitemap XML peut être créé et soumis gratuitement pour s’assurer que toutes les pages sont trouvées, en particulier les pages qui ne sont pas détectables en suivant automatiquement les liens [38]en plus de leur console de soumission d’URL. [39] Yahoo! exploitait auparavant un service de soumission payant qui garantissait l’exploration pour un coût par clic ; [40] cependant, cette pratique a été abandonnée en 2009.
Les robots des moteurs de recherche peuvent examiner un certain nombre de facteurs différents lors de l’ exploration d’un site. Toutes les pages ne sont pas indexées par les moteurs de recherche. La distance entre les pages et le répertoire racine d’un site peut également être un facteur déterminant si les pages sont explorées ou non. [41]
Aujourd’hui, la plupart des gens effectuent des recherches sur Google à l’aide d’un appareil mobile. [42] En novembre 2016, Google a annoncé un changement majeur dans la façon d’explorer les sites Web et a commencé à rendre son index mobile d’abord, ce qui signifie que la version mobile d’un site Web donné devient le point de départ de ce que Google inclut dans son index. [43] En mai 2019, Google a mis à jour le moteur de rendu de son crawler pour qu’il soit la dernière version de Chromium (74 au moment de l’annonce). Google a indiqué qu’il mettrait régulièrement à jour le moteur de rendu Chromium vers la dernière version. [44]En décembre 2019, Google a commencé à mettre à jour la chaîne User-Agent de son robot d’exploration pour refléter la dernière version de Chrome utilisée par son service de rendu. Le délai était de donner aux webmasters le temps de mettre à jour leur code qui répondait à des chaînes d’agent utilisateur de bot particulières. Google a effectué des évaluations et était convaincu que l’impact serait mineur. [45]
Empêcher l’exploration
Pour éviter le contenu indésirable dans les index de recherche, les webmasters peuvent demander aux araignées de ne pas explorer certains fichiers ou répertoires via le fichier robots.txt standard dans le répertoire racine du domaine. De plus, une page peut être explicitement exclue de la base de données d’un moteur de recherche en utilisant une balise meta spécifique aux robots (généralement <meta name=”robots” content=”noindex”> ). Lorsqu’un moteur de recherche visite un site, le fichier robots.txt situé dans le répertoire racineest le premier fichier exploré. Le fichier robots.txt est ensuite analysé et indiquera au robot quelles pages ne doivent pas être explorées. Comme un robot d’exploration de moteur de recherche peut conserver une copie en cache de ce fichier, il peut à l’occasion explorer des pages qu’un webmaster ne souhaite pas explorer. Les pages généralement empêchées d’être explorées incluent les pages spécifiques à la connexion telles que les paniers d’achat et le contenu spécifique à l’utilisateur tel que les résultats de recherche des recherches internes. En mars 2007, Google a averti les webmasters qu’ils devaient empêcher l’indexation des résultats de recherche interne car ces pages sont considérées comme du spam de recherche. [46] En 2020, Google a supprimé la norme (et ouvert son code) et la traite désormais comme un indice et non comme une directive. Pour garantir de manière adéquate que les pages ne sont pas indexées, une Balise méta de robot au niveau de la page doit être incluse.[47]
Accroître la notoriété
Diverses méthodes peuvent augmenter la visibilité d’une page Web dans les résultats de recherche. Les liens croisés entre les pages d’un même site Web pour fournir plus de liens vers des pages importantes peuvent améliorer sa visibilité. La conception de la page incite les utilisateurs à faire confiance à un site et à rester une fois qu’ils l’ont trouvé. Lorsque les gens rebondissent sur un site, cela compte pour le site et affecte leur crédibilité. [48] La rédaction de contenu comprenant des expressions de mots clés fréquemment recherchées, afin d’être pertinent pour une grande variété de requêtes de recherche, aura tendance à augmenter le trafic. La mise à jour du contenu de manière à ce que les moteurs de recherche reviennent fréquemment peut donner plus de poids à un site. Ajout de mots clés pertinents aux métadonnées d’une page Web, y compris la balise de titre et la méta description, aura tendance à améliorer la pertinence des listes de recherche d’un site, augmentant ainsi le trafic. La canonisation des URL des pages Web accessibles via plusieurs URL, en utilisant l’ élément de lien canonique [49] ou via des redirections 301 peut aider à s’assurer que les liens vers différentes versions de l’URL comptent tous dans le score de popularité des liens de la page. Ceux-ci sont connus sous le nom de liens entrants, qui pointent vers l’URL et peuvent être pris en compte dans le score de popularité du lien de la page, ce qui a un impact sur la crédibilité d’un site Web. [48]
De plus, ces derniers temps, Google donne plus de priorité aux éléments ci-dessous pour SERP (Search Engine Ranking Position).
- Version HTTPS (Site sécurisé)
- Vitesse des pages
- Données structurées
- Compatibilité mobile
- AMP (pages mobiles accélérées)
- BERT
Techniques du chapeau blanc contre le chapeau noir
Les techniques de référencement peuvent être classées en deux grandes catégories : les techniques recommandées par les sociétés de moteurs de recherche dans le cadre d’une bonne conception (“chapeau blanc”) et les techniques que les moteurs de recherche n’approuvent pas (“chapeau noir”). Les moteurs de recherche tentent de minimiser l’effet de ces derniers, parmi lesquels le spamdexing . Les commentateurs de l’industrie ont classé ces méthodes, et les praticiens qui les emploient, en tant que White Hat SEO ou Black Hat SEO. [50] Les chapeaux blancs ont tendance à produire des résultats qui durent longtemps, tandis que les chapeaux noirs prévoient que leurs sites pourraient éventuellement être interdits temporairement ou définitivement une fois que les moteurs de recherche auront découvert ce qu’ils font. [51]
Une technique de référencement est considérée comme un chapeau blanc si elle est conforme aux directives des moteurs de recherche et n’implique aucune tromperie. Comme les directives des moteurs de recherche [14] [15] [52] ne sont pas écrites comme une série de règles ou de commandements, il s’agit d’une distinction importante à noter. White hat SEO ne consiste pas seulement à suivre des directives, mais à s’assurer que le contenu qu’un moteur de recherche indexe et classe par la suite est le même contenu qu’un utilisateur verra. Les conseils White Hat se résument généralement à créer du contenu pour les utilisateurs, pas pour les moteurs de recherche, puis à rendre ce contenu facilement accessible aux algorithmes “araignées” en ligne, plutôt que d’essayer de tromper l’algorithme de son objectif. White hat SEO est à bien des égards similaire au développement Web qui favorise l’accessibilité, [53]bien que les deux ne soient pas identiques.
Black Hat SEO tente d’améliorer les classements d’une manière qui est désapprouvée par les moteurs de recherche ou qui implique une tromperie. Une technique de chapeau noir utilise du texte masqué, soit sous forme de texte coloré de manière similaire à l’arrière-plan, dans un div invisible ou positionné hors écran. Une autre méthode donne une page différente selon que la page est demandée par un visiteur humain ou un moteur de recherche, une technique connue sous le nom de cloaking . Une autre catégorie parfois utilisée est le Grey Hat SEO . C’est entre les approches chapeau noir et chapeau blanc, où les méthodes employées évitent que le site soit pénalisé mais n’agissent pas dans la production du meilleur contenu pour les utilisateurs. Grey hat SEO est entièrement axé sur l’amélioration du classement des moteurs de recherche.
Les moteurs de recherche peuvent pénaliser les sites qu’ils découvrent en utilisant des méthodes de chapeau noir ou gris, soit en réduisant leur classement, soit en éliminant complètement leurs listes de leurs bases de données. Ces pénalités peuvent être appliquées soit automatiquement par les algorithmes des moteurs de recherche, soit par une révision manuelle du site. Un exemple a été le retrait par Google en février 2006 de BMW Allemagne et de Ricoh Allemagne pour usage de pratiques trompeuses. [54] Les deux sociétés, cependant, se sont rapidement excusées, ont corrigé les pages incriminées et ont été restaurées sur la page de résultats du moteur de recherche de Google. [55]
Comme stratégie marketing
Le référencement n’est pas une stratégie appropriée pour tous les sites Web, et d’autres stratégies de marketing Internet peuvent être plus efficaces, telles que la publicité payante via des campagnes de paiement par clic (PPC) , en fonction des objectifs de l’opérateur du site. Le marketing sur les moteurs de recherche (SEM) consiste à concevoir, exécuter et optimiser des campagnes publicitaires sur les moteurs de recherche. Sa différence avec le référencement est simplement décrite comme la différence entre le classement prioritaire payant et non rémunéré dans les résultats de recherche. Le SEM se concentre davantage sur la proéminence que sur la pertinence ; Les développeurs de sites Web doivent accorder la plus haute importance au SEM en tenant compte de la visibilité, car la plupart naviguent vers les listes principales de leur recherche. [56]Une campagne de marketing Internet réussie peut également dépendre de la création de pages Web de haute qualité pour engager et persuader les internautes, de la mise en place de programmes d’ analyse pour permettre aux propriétaires de sites de mesurer les résultats et de l’amélioration du taux de conversion d’un site . [57] En novembre 2015, Google a publié une version complète de 160 pages de ses directives d’évaluation de la qualité de la recherche au public, [58] qui a révélé un changement d’orientation vers «l’utilité» et la recherche locale mobile . Ces dernières années, le marché mobile a explosé, dépassant l’utilisation des ordinateurs de bureau, comme l’a montré StatCounter en octobre 2016, où ils ont analysé 2,5 millions de sites Web et ont constaté que 51,3 % des pages étaient chargées par un appareil mobile.[59] Google a été l’une des entreprises qui exploitent la popularité de l’utilisation mobile en encourageant les sites Web à utiliser leur console de recherche Google , le test adapté aux mobiles, qui permet aux entreprises d’évaluer leur site Web par rapport aux résultats des moteurs de recherche et de déterminer comment leurs sites Web sont conviviaux. Plus les mots clés sont proches les uns des autres, plus leur classement s’améliorera en fonction des termes clés. [48]
Le référencement peut générer un retour sur investissement adéquat . Cependant, les moteurs de recherche ne sont pas payés pour le trafic de Recherche Organique, leurs algorithmes changent et il n’y a aucune garantie de références continues. En raison de ce manque de garantie et de l’incertitude, une entreprise qui dépend fortement du trafic des moteurs de recherche peut subir des pertes importantes si les moteurs de recherche cessent d’envoyer des visiteurs. [60] Les moteurs de recherche peuvent modifier leurs algorithmes, ce qui a un impact sur le classement d’un site Web dans les moteurs de recherche, ce qui peut entraîner une grave perte de trafic. Selon le PDG de Google, Eric Schmidt, en 2010, Google a effectué plus de 500 modifications d’algorithmes, soit près de 1,5 par jour. [61] Il est considéré comme une pratique commerciale judicieuse pour les exploitants de sites Web de se libérer de la dépendance vis-à-vis du trafic des moteurs de recherche.[62] En plus de l’accessibilité en termes de robots d’indexation Web (abordée ci-dessus), l’ accessibilité Web des utilisateurs est devenue de plus en plus importante pour le référencement.
Marchés internationaux
Les techniques d’optimisation sont parfaitement adaptées aux moteurs de recherche dominants du marché cible. Les parts de marché des moteurs de recherche varient d’un marché à l’autre, tout comme la concurrence. En 2003, Danny Sullivan a déclaré que Google représentait environ 75 % de toutes les recherches. [63] Sur les marchés en dehors des États-Unis, la part de Google est souvent plus importante et Google reste le moteur de recherche dominant dans le monde depuis 2007. [64] En 2006, Google détenait une part de marché de 85 à 90 % en Allemagne. [65] Alors qu’il y avait des centaines d’entreprises de référencement aux États-Unis à cette époque, il n’y en avait qu’environ cinq en Allemagne. [65] En juin 2008, la part de marché de Google au Royaume-Uni était proche de 90 % selon Hitwise . [66]Cette part de marché est obtenue dans un certain nombre de pays.
Depuis 2009, il n’y a que quelques grands marchés où Google n’est pas le principal moteur de recherche. Dans la plupart des cas, lorsque Google n’est pas leader sur un marché donné, il est en retard par rapport à un acteur local. Les exemples de marchés les plus notables sont la Chine, le Japon, la Corée du Sud, la Russie et la République tchèque où respectivement Baidu , Yahoo! Le Japon , Naver , Yandex et Seznam sont les leaders du marché.
Une optimisation de la recherche réussie pour les marchés internationaux peut nécessiter une traduction professionnelle des pages Web, l’enregistrement d’un nom de domaine avec un domaine de premier niveau sur le marché cible et un hébergement Web fournissant une adresse IP locale . Sinon, les éléments fondamentaux de l’optimisation de la recherche sont essentiellement les mêmes, quelle que soit la langue. [65]
Jurisprudence
Le 17 octobre 2002, SearchKing a intenté une action devant le tribunal de district des États-Unis , district ouest de l’Oklahoma, contre le moteur de recherche Google. L’affirmation de SearchKing était que les tactiques de Google pour empêcher le spamdexing constituaient une ingérence délictuelle dans les relations contractuelles. Le 27 mai 2003, le tribunal a accueilli la requête de Google visant à rejeter la plainte parce que SearchKing “n’a pas formulé de demande sur laquelle une réparation peut être accordée”. [67] [68]
En mars 2006, KinderStart a intenté une action en justice contre Google concernant les classements des moteurs de recherche. Le site Web de KinderStart a été supprimé de l’index de Google avant le procès, et le trafic vers le site a chuté de 70 %. Le 16 mars 2007, le tribunal de district des États-Unis pour le district nord de la Californie ( division de San Jose ) a rejeté la plainte de KinderStart sans autorisation de modification et a partiellement accueilli la requête de Google en vue de sanctions en vertu de la règle 11 contre l’avocat de KinderStart, l’obligeant à payer une partie des frais de Google. frais juridiques. [69] [70]
Voir également
- Réseau de blogs
- Backlinking des concurrents
- Liste des moteurs de recherche
- Marketing des moteurs de recherche
- Neutralité de la recherche , le contraire de la manipulation de la recherche
- Intention de l’utilisateur
- Promotion du site Web
Références
- ^ “SEO – optimisation des moteurs de recherche” . Webopédia . 19 décembre 2001.
- ^ Beel, Jöran et Gipp, Bela et Wilde, Erik (2010). “Optimisation des moteurs de recherche académiques (ASEO): Optimisation de la littérature savante pour Google Scholar and Co” (PDF) . Journal d’édition savante. p. 176–190 . Consulté le 18 avril 2010 . {{cite web}}: Maint CS1 : noms multiples : liste des auteurs ( lien )
- ^ Ortiz-Cordova, A. et Jansen, BJ (2012) Classification des requêtes de recherche Web afin d’identifier les clients générant des revenus élevés . Journal de la Société américaine des sciences et technologies de l’information. 63(7), 1426-1441.
- ^ Brian Pinkerton. “Trouver ce que les gens veulent : expériences avec le WebCrawler” (PDF) . La deuxième conférence internationale WWW Chicago, États-Unis, du 17 au 20 octobre 1994 . Récupéré le 7 mai 2007 .
- ^ “Introduction à l’optimisation des moteurs de recherche | Surveillance des moteurs de recherche” . searchenginewatch.com . 12 mars 2007 . Consulté le 7 octobre 2020 .
- ^ Danny Sullivan (14 juin 2004). “Qui a inventé le terme “Search Engine Optimization” ?” . Surveillance des moteurs de recherche . Archivé de l’original le 23 avril 2010 . Récupéré le 14 mai 2007 . Voir le fil de discussion des groupes Google .
- ^ “Le défi est ouvert” , Brain vs Computer , WORLD SCIENTIFIC, pp. 189–211, 17 novembre 2020, doi : 10.1142/9789811225017_0009 , ISBN 978-981-12-2500-0, S2CID 243130517 , récupéré le 20 septembre 2021
- ^ Pringle, G., Allison, L. et Dowe, D. (avril 1998). “Qu’est-ce qu’un grand coquelicot parmi les pages Web ?” . Proc. 7e Int. Conférence mondiale sur le Web . Récupéré le 8 mai 2007 . {{cite web}}: Maint CS1 : noms multiples : liste des auteurs ( lien )
- ^ Laurie J. Flynn (11 novembre 1996). “Recherche désespérément des surfeurs” . New York Times . Récupéré le 9 mai 2007 .
- ^ Jason Demers (20 janvier 2016). “La densité des mots clés est-elle toujours importante pour le référencement ?” . Forbes . Consulté le 15 août 2016 .
- ^ David Kesmodel (22 septembre 2005). “Les sites sont abandonnés par les moteurs de recherche après avoir essayé d'”optimiser” les classements” . Wall StreetJournal . Consulté le 30 juillet 2008 .
- ^ Adam L. Penenberg (8 septembre 2005). “Confrontation juridique dans Search Fracas” . Magazine filaire . Consulté le 11 août 2016 .
- ^ Matt Cutts (2 février 2006). “Confirmation d’une sanction” . mattcutts.com/blog . Récupéré le 9 mai 2007 .
- ^ un b “les Directives de Google sur la Conception d’emplacement” . Consulté le 18 avril 2007 .
- ^ un b “Bing Webmaster Guidelines” . bing.com . Consulté le 11 septembre 2014 .
- ^ “Plans de site” . Consulté le 4 mai 2012 .
- ^ “Par les données: pour les consommateurs, le mobile est Internet” Google for Entrepreneurs Startup Grind 20 septembre 2015.
- ^ Brin, Sergey & Page, Larry (1998). “L’anatomie d’un moteur de recherche Web hypertextuel à grande échelle” . Actes de la septième conférence internationale sur le World Wide Web. p. 107–117 . Récupéré le 8 mai 2007 .
- ^ “Les co-fondateurs de Google n’ont peut-être pas la reconnaissance du nom de Bill Gates, mais donnez-leur du temps : Google n’existe pas depuis aussi longtemps que Microsoft” . 15 octobre 2008.
- ^ Thompson, Bill (19 décembre 2003). “Est-ce que Google est bon pour vous ?” . Nouvelles de la BBC . Récupéré le 16 mai 2007 .
- ^ Zoltan Gyongyi et Hector Garcia-Molina (2005). “Lien Alliances Spam” (PDF) . Actes de la 31e Conférence VLDB, Trondheim, Norvège . Récupéré le 9 mai 2007 .
- ^ Hansell, Saül (3 juin 2007). “Google continue de peaufiner son moteur de recherche” . New York Times . Consulté le 6 juin 2007 .
- ^ Sullivan, Danny (29 septembre 2005). “Récapitulatif sur les facteurs de classement de recherche” . Surveillance des moteurs de recherche . Archivé de l’original le 28 mai 2007 . Récupéré le 8 mai 2007 .
- ^ Christine Churchill (23 novembre 2005). “Comprendre les brevets des moteurs de recherche” . Surveillance des moteurs de recherche . Archivé de l’original le 7 février 2007 . Récupéré le 8 mai 2007 .
- ^ “La recherche personnalisée de Google quitte Google Labs” . searchenginewatch.com . Surveillance des moteurs de recherche. Archivé de l’original le 25 janvier 2009 . Consulté le 5 septembre 2009 .
- ^ “8 choses que nous avons apprises sur Google PageRank” . www.searchenginejournal.com. 25 octobre 2007 . Consulté le 17 août 2009 .
- ^ “Sculpture du PageRank” . Matt Cuts . Consulté le 12 janvier 2010 .
- ^ “Google perd la” rétrocompatibilité “sur le blocage des liens payants et la sculpture du PageRank” . searchengineland.com. 3 juin 2009 . Consulté le 17 août 2009 .
- ^ “Recherche personnalisée pour tout le monde” . Consulté le 14 décembre 2009 .
- ^ “Notre nouvel index de recherche : Caféine” . Google : Blog officiel . Consulté le 10 mai 2014 .
- ^ “La pertinence rencontre le Web en temps réel” . Blogue Google .
- ^ “Mises à jour de la qualité de la recherche Google” . Blogue Google .
- ^ “Ce que vous devez savoir sur la mise à jour Penguin de Google” . Inc.com . 20 juin 2012.
- ^ “Google Penguin regarde principalement votre source de lien, dit Google” . Terre des moteurs de recherche . 10 octobre 2016 . Consulté le 20 avril 2017 .
- ^ “FAQ : Tout sur le nouvel algorithme “Hummingbird” de Google” . www.searchengineland.com . 26 septembre 2013 . Consulté le 17 mars 2018 .
- ^ “Comprendre les recherches mieux que jamais” . Google . 25 octobre 2019 . Consulté le 12 mai 2020 .
- ^ “Soumettre aux annuaires : Yahoo et l’Open Directory” . Surveillance des moteurs de recherche . 12 mars 2007. Archivé de l’original le 19 mai 2007 . Récupéré le 15 mai 2007 .
- ^ “Qu’est-ce qu’un fichier Sitemap et pourquoi devrais-je en avoir un ?” . Récupéré le 19 mars 2007 .
- ^ “Console de recherche – URL d’exploration” . Consulté le 18 décembre 2015 .
- ^ “Soumission aux robots de recherche : Google, Yahoo, Ask & Microsoft’s Live Search” . Surveillance des moteurs de recherche . 12 mars 2007. Archivé de l’original le 10 mai 2007 . Récupéré le 15 mai 2007 .
- ^ Cho, J., Garcia-Molina, H. (1998). “Exploration efficace grâce à la commande d’URL” . Actes de la septième conférence sur le World Wide Web, Brisbane, Australie . Récupéré le 9 mai 2007 . {{cite web}}: Maint CS1 : noms multiples : liste des auteurs ( lien )
- ^ “Index mobile d’abord” . Consulté le 19 mars 2018 .
- ^ Phan, Doantam (4 novembre 2016). “Indexation mobile d’abord” . Blog officiel de Google Webmaster Central . Consulté le 16 janvier 2019 .
- ^ “Le nouveau Googlebot à feuilles persistantes” . Blog officiel de Google Webmaster Central . Consulté le 2 mars 2020 .
- ^ “Mise à jour de l’agent utilisateur de Googlebot” . Blog officiel de Google Webmaster Central . Consulté le 2 mars 2020 .
- ^ “Journaux Amok! New York Times Spamming Google? LA Times Hijacking Cars.com?” . Terre des moteurs de recherche . 8 mai 2007 . Récupéré le 9 mai 2007 .
- ^ Jill Kocher Brown (24 février 2020). “Google rétrograde la directive Nofollow. Et maintenant ?” . Commerce électronique pratique . Consulté le 11 février 2021 .
- ^ un bc Morey , Sean (2008). L’écrivain numérique . Presse à fontaine. p. 171–187.
- ^ “Bing – Partenariat pour aider à résoudre les problèmes de contenu en double – Blog du webmaster – Communauté Bing” . www.bing.com . Consulté le 30 octobre 2009 .
- ^ Andrew Goodman. “Confrontation sur les moteurs de recherche : chapeaux noirs contre chapeaux blancs chez SES” . SearchEngineWatch. Archivé de l’original le 22 février 2007 . Récupéré le 9 mai 2007 .
- ^ Jill Whalen (16 novembre 2004). “Optimisation des moteurs de recherche Black Hat/White Hat” . searchengineguide.com. Archivé de l’original le 17 novembre 2004 . Récupéré le 9 mai 2007 .
- ^ “Qu’est-ce qu’un référencement ? Google recommande-t-il de travailler avec des entreprises qui proposent de rendre mon site convivial pour Google ?” . Consulté le 18 avril 2007 .
- ^ Andy Hagans (8 novembre 2005). “Une accessibilité élevée est une optimisation efficace des moteurs de recherche” . Une liste à part . Récupéré le 9 mai 2007 .
- ^ Matt Cutts (4 février 2006). « Montée en puissance des spams internationaux » . mattcutts.com/blog . Récupéré le 9 mai 2007 .
- ^ Matt Cutts (7 février 2006). “Réinclusions récentes” . mattcutts.com/blog . Récupéré le 9 mai 2007 .
- ^ Tapan, Panda (2013). “Marketing des moteurs de recherche : le processus de découverte des connaissances aide-t-il les détaillants en ligne ?”. Journal IUP de gestion des connaissances . 11 (3): 56–66. ProQuest 1430517207 .
- ^ Mélissa Burdon (13 mars 2007). “La bataille entre l’optimisation des moteurs de recherche et la conversion : qui gagne ?” . Grok.com. Archivé de l’original le 15 mars 2008 . Consulté le 10 avril 2017 .
- ^ “Lignes directrices pour l’évaluateur de la qualité de la recherche” Comment fonctionne la recherche 12 novembre 2015.
- ^ Titcomb, James (novembre 2016). “L’utilisation du Web mobile dépasse le bureau pour la première fois” . Le Télégraphe . Archivé de l’original le 10 janvier 2022 . Consulté le 17 mars 2018 .
- ^ Andy Greenberg (30 avril 2007). “Condamné à l’enfer de Google” . Forbes . Archivé de l’original le 2 mai 2007 . Récupéré le 9 mai 2007 .
- ^ Matt McGee (21 septembre 2011). “Le témoignage de Schmidt révèle comment Google teste les changements d’algorithme” .
- ^ Jakob Nielsen (9 janvier 2006). “Les moteurs de recherche comme sangsues sur le Web” . useit.com . Récupéré le 14 mai 2007 .
- ^ Graham, Jefferson (26 août 2003). “Le moteur de recherche qui pourrait” . Etats-Unis aujourd’hui . Récupéré le 15 mai 2007 .
- ^ Greg Jarboe (22 février 2007). “Les statistiques montrent que Google domine le paysage de la recherche internationale” . Surveillance des moteurs de recherche . Récupéré le 15 mai 2007 .
- ^ un bc Mike Grehan (3 avril 2006). “Optimisation des moteurs de recherche pour l’Europe” . Cliquez sur . Récupéré le 14 mai 2007 .
- ^ Jack Schofield (10 juin 2008). “Google UK se rapproche de 90 % de part de marché” . Gardien . Londres . Consulté le 10 juin 2008 .
- ^ “Search King, Inc. contre Google Technology, Inc., CIV-02-1457-M” (PDF) . docstock.com. 27 mai 2003 . Récupéré le 23 mai 2008 .
- ^ Stefanie Olsen (30 mai 2003). “Le juge rejette la poursuite contre Google” . CNET . Récupéré le 10 mai 2007 .
- ^ “Blog sur le droit de la technologie et du marketing: KinderStart contre Google rejeté – avec des sanctions contre l’avocat de KinderStart” . blog.ericgoldman.org . Consulté le 23 juin 2008 .
- ^ “Blog sur le droit de la technologie et du marketing : Google poursuivi pour les classements – KinderStart.com contre Google” . blog.ericgoldman.org . Consulté le 23 juin 2008 .
Liens externes
Écoutez cet article ( 22 minutes ) 21:41 ![]()
![]() Ce fichier audio a été créé à partir d’une révision de cet article datée du 20 mai 2008 et ne reflète pas les modifications ultérieures. ( 2008-05-20 ) ( Aide audio · Plus d’articles parlés )
Ce fichier audio a été créé à partir d’une révision de cet article datée du 20 mai 2008 et ne reflète pas les modifications ultérieures. ( 2008-05-20 ) ( Aide audio · Plus d’articles parlés )
- Promotion du développement Web chez Curlie
- Consignes aux webmasters de Google
- Consignes pour les évaluateurs de la qualité de la recherche Google (PDF)
- Ressources pour les webmasters de Yahoo!
- Consignes aux webmasters de Microsoft Bing
- The Dirty Little Secrets of Search dans le New York Times (12 février 2011)
- Google I/O 2010 – Conseils SEO du site par les experts sur YouTube – Tutoriel technique sur l’optimisation des moteurs de recherche, donné à Google I/O 2010