Covariance
En théorie des probabilités et en statistique , la covariance est une mesure de la variabilité conjointe de deux variables aléatoires . [1] Si les valeurs supérieures d’une variable correspondent principalement aux valeurs supérieures de l’autre variable, et qu’il en va de même pour les valeurs inférieures (c’est-à-dire que les variables ont tendance à afficher un comportement similaire), la covariance est positive. [2] Dans le cas contraire, lorsque les valeurs supérieures d’une variable correspondent principalement aux valeurs inférieures de l’autre (c’est-à-dire que les variables ont tendance à montrer un comportement opposé), la covariance est négative. Le signe de la covariance montre donc la tendance de la relation linéaireentre les variables. L’amplitude de la covariance n’est pas facile à interpréter car elle n’est pas normalisée et dépend donc de l’amplitude des variables. La version normalisée de la covariance , le coefficient de corrélation , montre cependant par sa grandeur la force de la Relation linéaire.
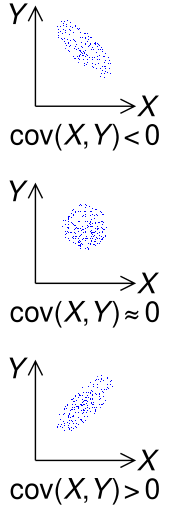 Le signe de la covariance de deux variables aléatoires X et Y
Le signe de la covariance de deux variables aléatoires X et Y
Il faut distinguer (1) la covariance de deux variables aléatoires, qui est un paramètre de population pouvant être vu comme une propriété de la distribution de probabilité conjointe , et (2) la covariance d’échantillon , qui en plus de servir de descripteur de l’échantillon, sert également de valeur estimée du paramètre de population.
Définition
Pour deux variables aléatoires à valeurs réelles distribuées conjointement X {displaystyle X} 

cov ( X , Oui ) = E [ ( X − E [ X ] ) ( Y − E [ Y ] ) ] {displaystyle operatorname {cov} (X,Y)=operatorname {E} {{big [}(X-operatorname {E} [X])(Y-operatorname {E} [Y]){ gros ]}}} ![{displaystyle operatorname {cov} (X,Y)=operatorname {E} {{big [}(X-operatorname {E} [X])(Y-operatorname {E} [Y]){big ]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f98a8bf924edb41a8025b5ffaa1b255b4a6f48b9)
où E [ X ] {displaystyle operatorname {E} [X]} ![operatorname {E} [X]](https://wikimedia.org/api/rest_v1/media/math/render/svg/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93)


cov ( X , Y ) = E [ ( X − E [ X ] ) ( Y − E [ Y ] ) ] = E [ X Y − X E [ Y ] − E [ X ] Y + E [ X ] E [ Y ] ] = E [ X Y ] − E [ X ] E [ Y ] − E [ X ] E [ Y ] + E [ X ] E [ Y ] = E [ X Y ] − E [ X ] E [ Y ] , {displaystyle {begin{aligned}operatorname {cov} (X,Y)&=operatorname {E} left[left(X-operatorname {E} left[Xright]right)left(Y-operatorname {E} left[Yright]right)right]\&=operatorname {E} left[XY-Xoperatorname {E} left[Yright]-operatorname {E} left[Xright]Y+operatorname {E} left[Xright]operatorname {E} left[Yright]right]\&=operatorname {E} left[XYright]-operatorname {E} left[Xright]operatorname {E} left[Yright]-operatorname {E} left[Xright]operatorname {E} left[Yright]+operatorname {E} left[Xright]operatorname {E} left[Yright]\&=operatorname {E} left[XYright]-operatorname {E} left[Xright]operatorname {E} left[Yright],end{aligned}}} ![{displaystyle {begin{aligned}operatorname {cov} (X,Y)&=operatorname {E} left[left(X-operatorname {E} left[Xright]right)left(Y-operatorname {E} left[Yright]right)right]\&=operatorname {E} left[XY-Xoperatorname {E} left[Yright]-operatorname {E} left[Xright]Y+operatorname {E} left[Xright]operatorname {E} left[Yright]right]\&=operatorname {E} left[XYright]-operatorname {E} left[Xright]operatorname {E} left[Yright]-operatorname {E} left[Xright]operatorname {E} left[Yright]+operatorname {E} left[Xright]operatorname {E} left[Yright]\&=operatorname {E} left[XYright]-operatorname {E} left[Xright]operatorname {E} left[Yright],end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b82a8c24b0063ffd95d8624f460acaaacb2a99b3)
mais cette équation est susceptible d’ annulation catastrophique (voir la section sur le calcul numérique ci-dessous).
Les unités de mesure de la covariance cov ( X , Y ) {displaystyle operatorname {cov} (X,Y)} 
Définition des variables aléatoires complexes
La covariance entre deux variables aléatoires complexes Z , W {displaystyle Z,W} 
cov ( Z , W ) = E [ ( Z − E [ Z ] ) ( W − E [ W ] ) ̄ ] = E [ Z W ̄ ] − E [ Z ] E [ W ̄ ] {displaystyle operatorname {cov} (Z,W)=operatorname {E} left[(Z-operatorname {E} [Z]){overline {(W-operatorname {E} [W]) }}right]=operatorname {E} left[Z{overline {W}}right]-operatorname {E} [Z]operatorname {E} left[{overline {W}} à droite]} ![{displaystyle operatorname {cov} (Z,W)=operatorname {E} left[(Z-operatorname {E} [Z]){overline {(W-operatorname {E} [W])}}right]=operatorname {E} left[Z{overline {W}}right]-operatorname {E} [Z]operatorname {E} left[{overline {W}}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cc823fe25634365b1859a3ee206ca894203a9ee2)
Remarquez la conjugaison complexe du deuxième facteur dans la définition.
Une Pseudo-covariance associée peut également être définie.
Variables aléatoires discrètes
Si la paire de variables aléatoires (réelles) ( X , Y ) {displaystyle (X,Y)} 



![{displaystyle operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/639e8577c6faffc0471c7e123ead30970034e6d5)
cov ( X , Y ) = 1 n ∑ i = 1 n ( x i − E ( X ) ) ( y i − E ( Y ) ) . {displaystyle operatorname {cov} (X,Y)={frac {1}{n}}sum _{i=1}^{n}(x_{i}-E(X))(y_{ i}-E(Y)).} 
Il peut également être exprimé de manière équivalente, sans se référer directement aux moyens, comme [5]
cov ( X , Y ) = 1 n 2 ∑ i = 1 n ∑ j = 1 n 1 2 ( x i − x j ) ( y i − y j ) = 1 n 2 ∑ i ∑ j > i ( x i − x j ) ( y i − y j ) . {displaystyle operatorname {cov} (X,Y)={frac {1}{n^{2}}}sum _{i=1}^{n}sum _{j=1}^{ n}{frac {1}{2}}(x_{i}-x_{j})(y_{i}-y_{j})={frac {1}{n^{2}}} somme _{i}somme _{j>i}(x_{i}-x_{j})(y_{i}-y_{j}).} 
Plus généralement, s’il existe n {displaystyle n} 

cov ( X , Y ) = ∑ i = 1 n p i ( x i − E ( X ) ) ( y i − E ( Y ) ) . {displaystyle operatorname {cov} (X,Y)=sum _{i=1}^{n}p_{i}(x_{i}-E(X))(y_{i}-E(Y )).} 
Exemple
 Interprétation géométrique de l’exemple de covariance. Chaque cuboïde est la boîte englobante de son point ( x , y , f ( x , y )) et les moyennes X et Y (point magenta). La covariance est la somme des volumes des cuboïdes rouges moins les cuboïdes bleus.
Interprétation géométrique de l’exemple de covariance. Chaque cuboïde est la boîte englobante de son point ( x , y , f ( x , y )) et les moyennes X et Y (point magenta). La covariance est la somme des volumes des cuboïdes rouges moins les cuboïdes bleus.
Supposer que X {displaystyle X} 

| f ( x , y ) {displaystyle f(x,y)} |
X | f Y ( y ) {displaystyle f_{Y}(y)}  |
|||
|---|---|---|---|---|---|
| 5 | 6 | 7 | |||
| y | 8 | 0 | 0,4 | 0,1 | 0,5 |
| 9 | 0,3 | 0 | 0,2 | 0,5 | |
f X ( x ) {displaystyle f_{X}(x)}  |
0,3 | 0,4 | 0,3 | 1 |
X {displaystyle X} 

cov ( X , Y ) = σ X Y = ∑ ( x , y ) ∈ S f ( x , y ) ( x − μ X ) ( y − μ Y ) = ( 0 ) ( 5 − 6 ) ( 8 − 8.5 ) + ( 0.4 ) ( 6 − 6 ) ( 8 − 8.5 ) + ( 0.1 ) ( 7 − 6 ) ( 8 − 8.5 ) + ( 0.3 ) ( 5 − 6 ) ( 9 − 8.5 ) + ( 0 ) ( 6 − 6 ) ( 9 − 8.5 ) + ( 0.2 ) ( 7 − 6 ) ( 9 − 8.5 ) = − 0.1 . {displaystyle {begin{aligned}operatorname {cov} (X,Y)={}&sigma _{XY}=sum _{(x,y)in S}f(x,y) gauche(x-mu _{X}droite)gauche(y-mu _{Y}droite)\[4pt]={}&(0)(5-6)(8-8.5)+ (0.4)(6-6)(8-8.5)+(0.1)(7-6)(8-8.5)+{}\[4pt]&(0.3)(5-6)(9-8.5)+ (0)(6-6)(9-8.5)+(0.2)(7-6)(9-8.5)\[4pt]={}&{-0.1};.end{aligné}}} ![{displaystyle {begin{aligned}operatorname {cov} (X,Y)={}&sigma _{XY}=sum _{(x,y)in S}f(x,y)left(x-mu _{X}right)left(y-mu _{Y}right)\[4pt]={}&(0)(5-6)(8-8.5)+(0.4)(6-6)(8-8.5)+(0.1)(7-6)(8-8.5)+{}\[4pt]&(0.3)(5-6)(9-8.5)+(0)(6-6)(9-8.5)+(0.2)(7-6)(9-8.5)\[4pt]={}&{-0.1};.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a80fa4db641ca7ddd6f7a3fee8620eed15321a7)
Propriétés
Covariance avec lui-même
La variance est un cas particulier de covariance où les deux variables sont identiques (c’est-à-dire où une variable prend toujours la même valeur que l’autre) : [4] : p. 121
cov ( X , X ) = var ( X ) ≡ σ 2 ( X ) ≡ σ X 2 . {displaystyle operatorname {cov} (X,X)=operatorname {var} (X)equiv sigma ^{2}(X)equiv sigma _{X}^{2}.} 
Covariance des combinaisons linéaires
Si X {displaystyle X} 


cov ( X , a ) = 0 cov ( X , X ) = var ( X ) cov ( X , Y ) = cov ( Y , X ) cov ( a X , b Y ) = a b cov ( X , Y ) cov ( X + a , Y + b ) = cov ( X , Y ) cov ( a X + b Y , c W + d V ) = a c cov ( X , W ) + a d cov ( X , V ) + b c cov ( Y , W ) + b d cov ( Y , V ) {displaystyle {begin{aligned}operatorname {cov} (X,a)&=0\operatorname {cov} (X,X)&=operatorname {var} (X)\operatorname {cov } (X,Y)&=nomopérateur {cov} (Y,X)\nomopérateur{cov} (aX,bY)&=ab,nomopérateur {cov} (X,Y)\nomopérateur { cov} (X+a,Y+b)&=nomopérateur {cov} (X,Y)\nomopérateur{cov} (aX+bY,cW+dV)&=ac,nomopérateur {cov} ( X,W)+ad,operatorname {cov} (X,V)+bc,operatorname {cov} (Y,W)+bd,operatorname {cov} (Y,V)end{aligned }}} 
Pour une séquence X 1 , … , X n {displaystyle X_{1},ldots ,X_{n}} 

var ( ∑ i = 1 n a i X i ) = ∑ i = 1 n a i 2 σ 2 ( X i ) + 2 ∑ i , j : i < j a i a j cov ( X i , X j ) = ∑ i , j a i a j cov ( X i , X j ) {displaystyle operatorname {var} left(sum _{i=1}^{n}a_{i}X_{i}right)=sum _{i=1}^{n}a_{i }^{2}sigma ^{2}(X_{i})+2sum _{i,j,:,i<j}a_{i}a_{j}operatorname {cov} (X_ {i},X_{j})=sum _{i,j}{a_{i}a_{j}nomopérateur {cov} (X_{i},X_{j})}} 
Identité de covariance de Hoeffding
Une identité utile pour calculer la covariance entre deux variables aléatoires X , Y {displaystyle X,Y} 
cov ( X , Y ) = ∫ R ∫ R ( F ( X , Y ) ( x , y ) − F X ( x ) F Y ( y ) ) d x d y {displaystyle operatorname {cov} (X,Y)=int _{mathbb {R} }int _{mathbb {R} }left(F_{(X,Y)}(x,y) -F_{X}(x)F_{Y}(y)droite),dx,dy} 
où F ( X , Y ) ( x , y ) {displaystyle F_{(X,Y)}(x,y)} 

Non-corrélation et indépendance
Les variables aléatoires dont la covariance est nulle sont dites non corrélées . [4] : p. 121 De même, les composantes de vecteurs aléatoires dont la matrice de covariance est nulle dans chaque entrée en dehors de la diagonale principale sont également appelées non corrélées.
Si X {displaystyle X}
E [ X Y ] = E [ X ] ⋅ E [ Y ] . {displaystyle operatorname {E} [XY]=operatorname {E} [X]cdot operatorname {E} [Y].} ![{displaystyle operatorname {E} [XY]=operatorname {E} [X]cdot operatorname {E} [Y].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c0c2870ec57051083bd6262aa4069a2500dfda44)
L’inverse, cependant, n’est généralement pas vrai. Par exemple, laissez X {displaystyle X} ![[-1,1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/51e3b7f14a6f70e614728c583409a0b9a8b9de01)

cov ( X , Y ) = cov ( X , X 2 ) = E [ X ⋅ X 2 ] − E [ X ] ⋅ E [ X 2 ] = E [ X 3 ] − E [ X ] E [ X 2 ] = 0 − 0 ⋅ E [ X 2 ] = 0. {displaystyle {begin{aligned}operatorname {cov} (X,Y)&=operatorname {cov} left(X,X^{2}right)\&=operatorname {E} left [Xcdot X^{2}right]-operatorname {E} [X]cdot operatorname {E} left[X^{2}right]\&=operatorname {E} left [X^{3}right]-operatorname {E} [X]operatorname {E} left[X^{2}right]\&=0-0cdot operatorname {E} [X ^{2}]\&=0.end{aligné}}} ![{displaystyle {begin{aligned}operatorname {cov} (X,Y)&=operatorname {cov} left(X,X^{2}right)\&=operatorname {E} left[Xcdot X^{2}right]-operatorname {E} [X]cdot operatorname {E} left[X^{2}right]\&=operatorname {E} left[X^{3}right]-operatorname {E} [X]operatorname {E} left[X^{2}right]\&=0-0cdot operatorname {E} [X^{2}]\&=0.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/19b6f2d636d5ef9ba85b6350e49222109a28d665)
Dans ce cas, la relation entre Y {displaystyle Y}
Relation avec les produits internes
De nombreuses propriétés de la covariance peuvent être extraites élégamment en observant qu’elle satisfait des propriétés similaires à celles d’un produit scalaire :
- bilinéaire : pour les constantes a {displaystyle a}
et b {displaystyle b}
et variables aléatoires X , Y , Z , cov ( a X + b Y , Z ) = a cov ( X , Z ) + b cov ( Y , Z ) {displaystyle X,Y,Z,operatorname {cov} (aX+bY,Z)=aoperatorname {cov} (X,Z)+boperatorname {cov} (Y,Z)}
- symétrique: cov ( X , Y ) = cov ( Y , X ) {displaystyle operatorname {cov} (X,Y)=operatorname {cov} (Y,X)}
- semi-défini positif : σ 2 ( X ) = cov ( X , X ) ≥ 0 {displaystyle sigma ^{2}(X)=operatorname {cov} (X,X)geq 0}
pour toutes les variables aléatoires X {displaystyle X}
, et cov ( X , X ) = 0 {displaystyleoperatorname {cov} (X,X)=0}
implique que X {displaystyle X}
est constant presque sûrement .






En fait, ces propriétés impliquent que la covariance définit un produit interne sur l’ espace vectoriel quotient obtenu en prenant le sous-espace des variables aléatoires avec un second moment fini et en identifiant deux qui diffèrent par une constante. (Cette identification transforme la semi-définition positive ci-dessus en définition positive.) Cet espace vectoriel quotient est isomorphe au sous-espace des variables aléatoires avec un second moment fini et une moyenne nulle; sur ce sous-espace, la covariance est exactement le produit interne L 2 des fonctions à valeurs réelles sur l’espace échantillon.
Par conséquent, pour des variables aléatoires à variance finie, l’inégalité
| cov ( X , Y ) | ≤ σ 2 ( X ) σ 2 ( Y ) {displaystyle |operatorname {cov} (X,Y)|leq {sqrt {sigma ^{2}(X)sigma ^{2}(Y)}}} 
se vérifie via l’ inégalité de Cauchy-Schwarz .
Preuve : Si σ 2 ( Y ) = 0 {displaystyle sigma ^{2}(Y)=0} 
Z = X − cov ( X , Oui ) σ 2 ( Y ) Y . {displaystyle Z=X-{frac {operatorname {cov} (X,Y)}{sigma ^{2}(Y)}}Y.} 
Ensuite nous avons
0 ≤ σ 2 ( Z ) = cov ( X − cov ( X , Y ) σ 2 ( Y ) Y , X − cov ( X , Y ) σ 2 ( Y ) Y ) = σ 2 ( X ) − ( cov ( X , Y ) ) 2 σ 2 ( Y ) . {displaystyle {begin{aligned}0leq sigma ^{2}(Z)&=operatorname {cov} left(X-{frac {operatorname {cov} (X,Y)}{ sigma ^{2}(Y)}}Y,;X-{frac {operatorname {cov} (X,Y)}{sigma ^{2}(Y)}}Yright)\[ 12pt]&=sigma ^{2}(X)-{frac {(operatorname {cov} (X,Y))^{2}}{sigma ^{2}(Y)}}.end {aligné}}} ![{displaystyle {begin{aligned}0leq sigma ^{2}(Z)&=operatorname {cov} left(X-{frac {operatorname {cov} (X,Y)}{sigma ^{2}(Y)}}Y,;X-{frac {operatorname {cov} (X,Y)}{sigma ^{2}(Y)}}Yright)\[12pt]&=sigma ^{2}(X)-{frac {(operatorname {cov} (X,Y))^{2}}{sigma ^{2}(Y)}}.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fc8741ab12cb5943efe9d8dbfeb455517bc63347)
Calcul de la covariance de l’échantillon
Les covariances d’échantillon entre K {displaystyle K} 


![{displaystyle textstyle {overline {mathbf {q} }}=left[q_{jk}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cb28ac928a2a379d039d27fb99d56dd21c1c027c)
q j k = 1 N − 1 ∑ i = 1 N ( X i j − X ̄ j ) ( X i k − X ̄ k ) , {displaystyle q_{jk}={frac {1}{N-1}}sum _{i=1}^{N}left(X_{ij}-{bar {X}}_{j }droite)gauche(X_{ik}-{bar {X}}_{k}droite),} 
qui est une estimation de la covariance entre la variable j {displaystyle j} 

La moyenne de l’échantillon et la matrice de covariance de l’échantillon sont des estimations non biaisées de la moyenne et de la matrice de covariance du Vecteur aléatoire X {displaystyle textstyle mathbf {X} } 





q j k = 1 N ∑ i = 1 N ( X i j − E ( X j ) ) ( X i k − E ( X k ) ) {displaystyle q_{jk}={frac {1}{N}}sum _{i=1}^{N}left(X_{ij}-operatorname {E} left(X_{j} right)right)left(X_{ik}-operatorname {E} left(X_{k}right)right)} 
Généralisations
Matrice d’auto-covariance de vecteurs aléatoires réels
Pour un vecteur X = [ X 1 X 2 … X m ] T {displaystyle mathbf {X} ={begin{bmatrix}X_{1}&X_{2}&dots &X_{m}end{bmatrix}}^{mathrm {T} }} 




K X X = cov ( X , X ) = E [ ( X − E [ X ] ) ( X − E [ X ] ) T ] = E [ X X T ] − E [ X ] E [ X ] T . {displaystyle {begin{aligned}operatorname {K} _{mathbf {XX} }=operatorname {cov} (mathbf {X} ,mathbf {X} )&=operatorname {E} left [(mathbf {X} -nom de l’opérateur {E} [mathbf {X} ])(mathbf {X} -nom de l’opérateur {E} [mathbf {X} ])^{mathrm {T} } right]\&=operatorname {E} left[mathbf {XX} ^{mathrm {T} }right]-operatorname {E} [mathbf {X} ]operatorname {E} [ mathbf {X} ]^{mathrm {T} }.end{aligné}}} ![{displaystyle {begin{aligned}operatorname {K} _{mathbf {XX} }=operatorname {cov} (mathbf {X} ,mathbf {X} )&=operatorname {E} left[(mathbf {X} -operatorname {E} [mathbf {X} ])(mathbf {X} -operatorname {E} [mathbf {X} ])^{mathrm {T} }right]\&=operatorname {E} left[mathbf {XX} ^{mathrm {T} }right]-operatorname {E} [mathbf {X} ]operatorname {E} [mathbf {X} ]^{mathrm {T} }.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/15725714f72a46ffb0686bafdb209260b842ac39)
Laisser X {displaystyle mathbf {X} } 
cov ( A X , A X ) = E [ A X ( A X ) T ] − E [ A X ] E [ ( A X ) T ] = E [ A X X T A T ] − E [ A X ] E [ X T A T ] = A E [ X X T ] A T − A E [ X ] E [ X T ] A T = A ( E [ X X T ] − E [ X ] E [ X T ] ) A T = A Σ A T . {displaystyle {begin{aligned}operatorname {cov} (mathbf {AX} ,mathbf {AX} )&=operatorname {E} left[mathbf {AX(A} mathbf {X)} ^{mathrm {T} }right]-operatorname {E} [mathbf {AX} ]operatorname {E} left[(mathbf {A} mathbf {X} )^{mathrm {T} }right]\&=operatorname {E} left[mathbf {AXX} ^{mathrm {T} }mathbf {A} ^{mathrm {T} }right]-operatorname {E} [mathbf {AX} ]operatorname {E} left[mathbf {X} ^{mathrm {T} }mathbf {A} ^{mathrm {T} }right]\&=mathbf {A} operatorname {E} left[mathbf {XX} ^{mathrm {T} }right]mathbf {A} ^{mathrm {T} }-mathbf {A} operatorname {E} [mathbf {X} ]operatorname {E} left[mathbf {X} ^{mathrm {T} }right]mathbf {A} ^{mathrm {T} }\&=mathbf {A} left(operatorname {E} left[mathbf {XX} ^{mathrm {T} }right]-operatorname {E} [mathbf {X} ]operatorname {E} left[mathbf {X} ^{mathrm {T} }right]right)mathbf {A} ^{mathrm {T} }\&=mathbf {A} Sigma mathbf {A} ^{mathrm {T} }.end{aligned}}} ![{displaystyle {begin{aligned}operatorname {cov} (mathbf {AX} ,mathbf {AX} )&=operatorname {E} left[mathbf {AX(A} mathbf {X)} ^{mathrm {T} }right]-operatorname {E} [mathbf {AX} ]operatorname {E} left[(mathbf {A} mathbf {X} )^{mathrm {T} }right]\&=operatorname {E} left[mathbf {AXX} ^{mathrm {T} }mathbf {A} ^{mathrm {T} }right]-operatorname {E} [mathbf {AX} ]operatorname {E} left[mathbf {X} ^{mathrm {T} }mathbf {A} ^{mathrm {T} }right]\&=mathbf {A} operatorname {E} left[mathbf {XX} ^{mathrm {T} }right]mathbf {A} ^{mathrm {T} }-mathbf {A} operatorname {E} [mathbf {X} ]operatorname {E} left[mathbf {X} ^{mathrm {T} }right]mathbf {A} ^{mathrm {T} }\&=mathbf {A} left(operatorname {E} left[mathbf {XX} ^{mathrm {T} }right]-operatorname {E} [mathbf {X} ]operatorname {E} left[mathbf {X} ^{mathrm {T} }right]right)mathbf {A} ^{mathrm {T} }\&=mathbf {A} Sigma mathbf {A} ^{mathrm {T} }.end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c1b2123c32a8acefc209a4f69d571ee1197a8c59)
Ceci est un résultat direct de la linéarité de l’ attente et est utile lors de l’application d’une Transformation linéaire , telle qu’une transformation de blanchiment , à un vecteur.
Matrice de covariance croisée de vecteurs aléatoires réels
Pour les vecteurs aléatoires réels X ∈ R m {displaystyle mathbf {X} in mathbb {R} ^{m}} 


K X Y = cov ( X , Y ) = E [ ( X − E [ X ] ) ( Y − E [ Y ] ) T ] = E [ X Y T ] − E [ X ] E [ Y ] T {displaystyle {begin{aligned}operatorname {K} _{mathbf {X} mathbf {Y} }=operatorname {cov} (mathbf {X} ,mathbf {Y} )&=operatorname {E} left[(mathbf {X} -nomopérateur {E} [mathbf {X} ])(mathbf {Y} -nomopérateur {E} [mathbf {Y} ])^{mathrm {T} }right]\&=operatorname {E} left[mathbf {X} mathbf {Y} ^{mathrm {T} }right]-operatorname {E} [mathbf { X} ]nomopérateur {E} [mathbf {Y} ]^{mathrm {T} }end{aligned}}} ![{displaystyle {begin{aligned}operatorname {K} _{mathbf {X} mathbf {Y} }=operatorname {cov} (mathbf {X} ,mathbf {Y} )&=operatorname {E} left[(mathbf {X} -operatorname {E} [mathbf {X} ])(mathbf {Y} -operatorname {E} [mathbf {Y} ])^{mathrm {T} }right]\&=operatorname {E} left[mathbf {X} mathbf {Y} ^{mathrm {T} }right]-operatorname {E} [mathbf {X} ]operatorname {E} [mathbf {Y} ]^{mathrm {T} }end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/99e6f5ef675f7bb826d04f206bd212d14632ab8c) |
( Éq.2 ) |
où Y T { displaystyle mathbf {Y} ^ { mathrm {T} }} 

Le ( i , j ) {displaystyle (i,j)} 



Forme sesquilinéaire à covariance croisée de vecteurs aléatoires dans un espace de Hilbert réel ou complexe
Plus généralement laisser H 1 = ( H 1 , ⟨ , ⟩ 1 ) {displaystyle H_{1}=(H_{1},langle ,,rangle _{1})} 








K X , Y ( h 1 , h 2 ) = cov ( X , Y ) ( h 1 , h 2 ) = E [ ⟨ h 1 , ( X − E [ X ] ) ⟩ 1 ⟨ ( Y − E [ Y ] ) , h 2 ⟩ 2 ] = E [ ⟨ h 1 , X ⟩ 1 ⟨ Y , h 2 ⟩ 2 ] − E [ ⟨ h , X ⟩ 1 ] E [ ⟨ Y , h 2 ⟩ 2 ] = ⟨ h 1 , E [ ( X − E [ X ] ) ( Y − E [ Y ] ) † ] h 2 ⟩ 1 = ⟨ h 1 , ( E [ X Y † ] − E [ X ] E [ Y ] † ) h 2 ⟩ 1 {displaystyle {begin{aligned}operatorname {K} _{X,Y}(h_{1},h_{2})=operatorname {cov} (mathbf {X} ,mathbf {Y} )(h_{1},h_{2})&=operatorname {E} left[langle h_{1},(mathbf {X} -operatorname {E} [mathbf {X} ])rangle _{1}langle (mathbf {Y} -operatorname {E} [mathbf {Y} ]),h_{2}rangle _{2}right]\&=operatorname {E} [langle h_{1},mathbf {X} rangle _{1}langle mathbf {Y} ,h_{2}rangle _{2}]-operatorname {E} [langle h,mathbf {X} rangle _{1}]operatorname {E} [langle mathbf {Y} ,h_{2}rangle _{2}]\&=langle h_{1},operatorname {E} left[(mathbf {X} -operatorname {E} [mathbf {X} ])(mathbf {Y} -operatorname {E} [mathbf {Y} ])^{dagger }right]h_{2}rangle _{1}\&=langle h_{1},left(operatorname {E} [mathbf {X} mathbf {Y} ^{dagger }]-operatorname {E} [mathbf {X} ]operatorname {E} [mathbf {Y} ]^{dagger }right)h_{2}rangle _{1}\end{aligned}}} ![{displaystyle {begin{aligned}operatorname {K} _{X,Y}(h_{1},h_{2})=operatorname {cov} (mathbf {X} ,mathbf {Y} )(h_{1},h_{2})&=operatorname {E} left[langle h_{1},(mathbf {X} -operatorname {E} [mathbf {X} ])rangle _{1}langle (mathbf {Y} -operatorname {E} [mathbf {Y} ]),h_{2}rangle _{2}right]\&=operatorname {E} [langle h_{1},mathbf {X} rangle _{1}langle mathbf {Y} ,h_{2}rangle _{2}]-operatorname {E} [langle h,mathbf {X} rangle _{1}]operatorname {E} [langle mathbf {Y} ,h_{2}rangle _{2}]\&=langle h_{1},operatorname {E} left[(mathbf {X} -operatorname {E} [mathbf {X} ])(mathbf {Y} -operatorname {E} [mathbf {Y} ])^{dagger }right]h_{2}rangle _{1}\&=langle h_{1},left(operatorname {E} [mathbf {X} mathbf {Y} ^{dagger }]-operatorname {E} [mathbf {X} ]operatorname {E} [mathbf {Y} ]^{dagger }right)h_{2}rangle _{1}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a5e62db23468fadd6a7f877ed44ede2bfbc07365)
Calcul numérique
Lorsque E [ X Y ] ≈ E [ X ] E [ Y ] {displaystyle operatorname {E} [XY]approx operatorname {E} [X]operatorname {E} [Y]} ![operatorname {E} [XY]approx operatorname {E} [X]operatorname {E} [Y]](https://wikimedia.org/api/rest_v1/media/math/render/svg/5cc8091d0da21aa8f5a114797ba5113ddf534f69)
![{displaystyle operatorname {cov} (X,Y)=operatorname {E} left[XYright]-operatorname {E} left[Xright]operatorname {E} left[Yright]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bdf56a30f7ff1be354713f144bfd02ba949a77f4)
![{displaystyle operatorname {E} left[XYright]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/128f7734bafe2a92d25d3df5fbb614e1d22b2e45)
![{displaystyle operatorname {E} left[Xright]operatorname {E} left[Yright]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f05701ae57cc8e32cd812037d7ba5d3d433021d4)
commentaires
La covariance est parfois appelée une mesure de “Dépendance linéaire” entre les deux variables aléatoires. Cela ne veut pas dire la même chose que dans le cadre de l’algèbre linéaire (voir Dépendance linéaire ). Lorsque la covariance est normalisée, on obtient le coefficient de corrélation de Pearson , qui donne la qualité de l’ajustement pour la meilleure fonction linéaire possible décrivant la relation entre les variables. En ce sens, la covariance est une jauge linéaire de dépendance.
Applications
En génétique et biologie moléculaire
La covariance est une mesure importante en biologie . Certaines séquences d’ ADN sont plus conservées que d’autres parmi les espèces, et ainsi pour étudier les structures secondaires et tertiaires des protéines , ou des structures d’ ARN , les séquences sont comparées chez des espèces étroitement apparentées. Si des changements de séquence sont trouvés ou si aucun changement n’est trouvé dans l’ARN non codant (comme le microARN), les séquences s’avèrent nécessaires pour les motifs structurels courants, tels qu’une boucle d’ARN. En génétique, la covariance sert de base au calcul de la matrice de relations génétiques (GRM) (alias matrice de parenté), permettant l’inférence sur la structure de la population à partir d’un échantillon sans parents proches connus ainsi que l’inférence sur l’estimation de l’héritabilité de traits complexes.
Dans la théorie de l’ évolution et de la sélection naturelle , l’ équation de Price décrit comment un trait génétique change de fréquence au fil du temps. L’équation utilise une covariance entre un trait et la forme physique , pour donner une description mathématique de l’évolution et de la sélection naturelle. Il fournit un moyen de comprendre les effets de la transmission génétique et de la sélection naturelle sur la proportion de gènes au sein de chaque nouvelle génération d’une population. [12] [13] L’équation de Price a été dérivée par George R. Price , pour re-dériver le travail de WD Hamilton sur la sélection des parents .Des exemples de l’équation de prix ont été construits pour divers cas d’évolution.
En économie financière
Les covariances jouent un rôle clé en économie financière , en particulier dans la théorie moderne du portefeuille et dans le modèle d’évaluation des actifs financiers . Les covariances entre les rendements de divers actifs sont utilisées pour déterminer, sous certaines hypothèses, les montants relatifs des différents actifs que les investisseurs devraient (dans une analyse normative ) ou devraient (dans une analyse positive ) choisir de détenir dans un contexte de diversification .
En assimilation de données météorologiques et océanographiques
La matrice de covariance est importante pour estimer les conditions initiales requises pour exécuter des modèles de prévision météorologique, une procédure connue sous le nom d’assimilation de données . La «matrice de covariance des erreurs de prévision» est généralement construite entre des perturbations autour d’un état moyen (soit une moyenne climatologique, soit une moyenne d’ensemble). La «matrice de covariance des erreurs d’observation» est construite pour représenter l’ampleur des erreurs d’observation combinées (sur la diagonale) et les erreurs corrélées entre les mesures (hors de la diagonale). Ceci est un exemple de son application généralisée au filtrage de Kalman et à l’estimation d’état plus générale pour les systèmes variant dans le temps.
En micrométéorologie
La technique de covariance des tourbillons est une technique de mesure atmosphérique clé où la covariance entre l’écart instantané de la vitesse verticale du vent par rapport à la valeur moyenne et l’écart instantané de la concentration de gaz est la base du calcul des flux turbulents verticaux.
En traitement du signal
La matrice de covariance est utilisée pour capturer la variabilité spectrale d’un signal. [14]
En statistiques et traitement d’images
La matrice de covariance est utilisée dans l’analyse en composantes principales pour réduire la dimensionnalité des caractéristiques dans le prétraitement des données .
Voir également
- Algorithmes de calcul de covariance
- Analyse de covariance
- Autocovariance
- Fonction de covariance
- Opérateur de covariance
- Covariance de distance ou covariance brownienne.
- Loi de covariance totale
- Propagation de l’incertitude
Références
- ^ Riz, John (2007). Statistiques mathématiques et analyse de données . Belmont, Californie : Brooks/Cole Cengage Learning. p. 138. ISBN 978-0534-39942-9.
- ^ Weisstein, Eric W. “Covariance” . MathWorld .
- ^ Oxford Dictionary of Statistics, Oxford University Press, 2002, p. 104.
- ^ un bcde Park , Kun Il (2018) . Principes fondamentaux des probabilités et des processus stochastiques avec des applications aux communications . Springer. ISBN 978-3-319-68074-3.
- ^ Yuli Zhang, Huaiyu Wu, Lei Cheng (juin 2012). Quelques nouvelles formules de déformation sur la variance et la covariance . Actes de la 4e Conférence internationale sur la modélisation, l’identification et le contrôle (ICMIC2012). pp. 987–992. {{cite conference}}: CS1 maint: uses authors parameter (link)
- ^ “Covariance de X et Y | STAT 414/415” . L’Université d’État de Pennsylvanie. Archivé de l’original le 17 août 2017 . Consulté le 4 août 2019 .
- ^ Papoulis (1991). Probabilité, variables aléatoires et processus stochastiques . McGraw-Hill.
- ^ Siegrist, Kyle. « Covariance et corrélation » . Université de l’Alabama à Huntsville . Consulté le 4 août 2019 .
- ^ un b Gubner, John A. (2006). Probabilités et processus aléatoires pour les ingénieurs électriciens et informaticiens . La presse de l’Universite de Cambridge. ISBN 978-0-521-86470-1.
- ^ Donald E. Knuth (1998). The Art of Computer Programming , volume 2 : Seminumerical Algorithms , 3e éd., p. 232. Boston : Addison-Wesley.
- ^ Schubert, Érich; Gertz, Michael (2018). “Calcul parallèle numériquement stable de la (co-)variance” . Actes de la 30e Conférence internationale sur la gestion des bases de données scientifiques et statistiques – SSDBM ’18 . Bozen-Bolzano, Italie : ACM Press : 1–12. doi : 10.1145/3221269.3223036 . ISBN 9781450365055. S2CID 49665540 .
- ^ Prix, George (1970). “Sélection et covariance”. Nature . 227 (5257): 520–521. doi : 10.1038/227520a0 . PMID 5428476 . S2CID 4264723 .
- ^ Harman, Oren (2020). “Quand la science reflète la vie : aux origines de l’équation des prix” . Phil. Trans. R. Soc. B. _ 375 (1797): 1–7. doi : 10.1098/rstb.2019.0352 . PMC 7133509 . PMID 32146891 . Récupéré le 15/05/2020 .
- ^ Sahidullah, Maryland; Kinnunen, Tomi (mars 2016). “Fonctionnalités de variabilité spectrale locale pour la vérification du locuteur” . Traitement numérique du signal . 50 : 1–11. doi : 10.1016/j.dsp.2015.10.011 .